bluebell笔记
bluebell笔记
项目结构
1 | |
整个项目大体分为三层: - controller:服务的入口,负责处理路由、参数校验、请求转发 - logic/service:逻辑层,负责处理业务逻辑 - dao/reposity:负责数据与存储的相关 ## 使用validator做参数校验 在平常开发中,特别是在web应用开发中,为了验证输入字段的合法性,都会做一些验证操作。比如对用户提交的表单字段进行验证,或者对请求的API接口字段进行验证,验证字段的合法性,保证输入字段值的安全,防止用户的恶意请求。
一般的做法是用正则表达式,一个字段一个字段的进行验证。一个一个字段验证的话,写起来比较繁琐。那有没更好的方法,进行字段的合法性验证?有, 这就是下面要介绍的 validator 这个验证组件。
gin框架使用github.com/go-playground/validator进行参数校验,目前已经支持github.com/go-playground/validator/v10了,我们需要在定义结构体时使用 binding tag标识相关校验规则,可以查看validator文档查看支持的所有
tag。 基本示例:
1 | |
- gte、lte:验证规则,限定了该变量的范围。
- required: 验证规则,表示该字段是必填的。没有提供这个字段,或者提供的值是零值(如空字符串、零值的数字等),都会导致验证失败。
- email:验证规则,表示该字段的值必须符合电子邮件格式。如果提供的值不是一个有效的电子邮件地址,验证也会失败。
- eqfield:验证规则,用来比较结构体中两个字段的值是否相等。这里的
eqfield=Password表示RePassword字段必须与Password字段的值相同,以确保用户输入的确认密码与实际密码一致。
雪花算法作为数据库主键
为什么不使用其他算法?为什么选择雪花算法?
有时候在业务中,需要使用一些唯一的ID,来记录我们某个数据的标识。最常用的无非以下几种:UUID、数据库自增主键、Redis的Incr命令等方法来获取一个唯一的值。下面我们分别说一下它们的优劣,以便引出我们的分布式雪花算法。
UUID
首先是 UUID ,它是由128位二进制组成,一般转换成十六进制,然后用String表示。为了保证 UUID 的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成 UUID 的算法。
UUID 有五个版本:
- 版本1:基于时间戳和mac地址
- 版本2:基于时间戳,mac地址和
POSIX UID/GID - 版本3:基于MD5哈希算法
- 版本4:基于随机数
- 版本5:基于SHA-1哈希算法
UUID 的优缺点:
- 优点:代码简单,性能比较好。
- 缺点:没有排序,无法保证按序递增;其次是太长了,存储数据库占用空间比较大,不利于检索和排序。
数据库自增主键
优点:方便排序和索引
缺点:
- 数据库是磁盘IO,速度比较慢,所以会导致性能瓶颈
- 如果数据量太大的情况下需要分库分表,而多个库的情况下无法保证一个主键是全局唯一的
- 过度依赖数据库,如果数据库宕机了,这个功能是无法使用的
Redis
使用Redis 中的两个命令 Incr、IncrBy。
- 优点:
- redis是基于内存的,所以性能很高
- redis是单线程的,所以上面两个指令可以保证原子性,从而可以生成全局唯一的id,在分库分表的情况下相比较于数据库自增主键可以实现全局唯一id。
- 缺点:
- 即使有AOF和RDB持久化,仍然会有数据丢失,这样可能会造成id重复
- 依赖redis,如果redis服务不稳定,会影响id生成
Snowflake
Snowflake最早是twitter内部使用的分布式环境下的唯一ID生成算法。
它有以下几个特点:
- 能满足高并发分布式系统环境下ID不重复;
- 基于时间戳,可以保证基本有序递增;
- 不依赖于第三方的库或者中间件;
实现原理
Snowflake 结构是一个 64bit 的 int64 类型的数据。如下:
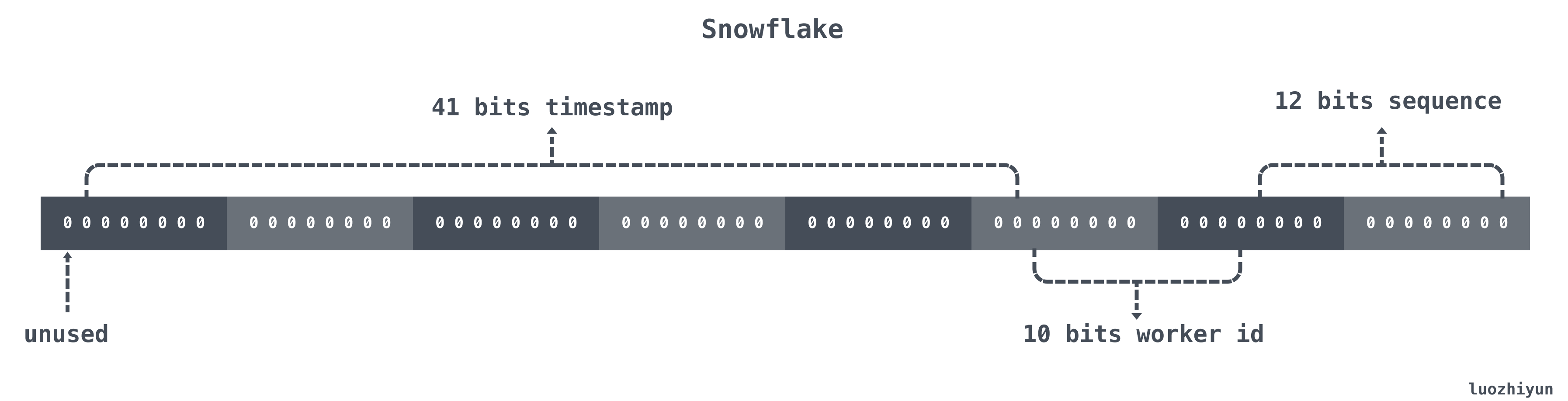
从低位到高位的bits作用依次为:
| 位置 | 大小 | 作用 |
|---|---|---|
| 0~11bit | 12bits | 序列号,用来对同一个毫秒之内产生不同的ID,可记录4095个 |
| 12~21bit | 10bits | 10bit用来记录机器ID,总共可以记录1024台机器 |
| 22~62bit | 41bits | 用来记录时间戳,这里可以记录69年 |
| 63bit | 1bit | 符号位,不做处理 |
即,从低到高:
- 12 bit序列号
- 10 bit机器id,又分为datacenter(即机房号)和worker id(即主机的id),10位一共可以有1024个不同的机器
- 41 bit时间戳
- 1 bit 未使用,置0
上面只是一个将 64bit 划分的通用标准,一般的情况可以根据自己的业务情况进行调整。例如目前业务只有机器10台左右预计未来会增加到三位数,并且需要进行多机房部署,QPS 几年之内会发展到百万。
那么对于百万 QPS 平分到 10 台机器上就是每台机器承担十万的请求即可,12 bit 的序列号完全够用。对于未来会增加到三位数机器,并且需要多机房部署的需求我们仅需要将 10 bits 的 work id 进行拆分,分割 3 bits 来代表机房数共代表可以部署8个机房,其他 7bits 代表机器数代表每个机房可以部署128台机器。那么数据格式就会如下所示:

Snowflake实现
其实看懂了上面的数据结构之后,需要自己实现一个雪花算法是非常简单,步骤大致如下:
- 获取当前的毫秒时间戳;
- 用当前的毫秒时间戳和上次保存的时间戳进行比较;
- 如果和上次保存的时间戳相等,那么对序列号 sequence 加一;
- 如果不相等,那么直接设置 sequence 为 0 即可;
- 然后通过或运算拼接雪花算法需要返回的 int64 返回值。
代码实现
首先我们需要定义一个 Snowflake 结构体:
1 | |
然后我们需要定义一些常量,方便我们在使用雪花算法的时候进行位运算取值:
1 | |
Tips:timestampMax怎么获得?
-1 在二进制上表示是:
1 | |
那么再和 -1 左移 41位 进行 ^异或运算:
1 | |
这就可以表示 41bits 的 timestamp 最大值。datacenteridMax、workeridMax也同理。
函数代码
1 | |
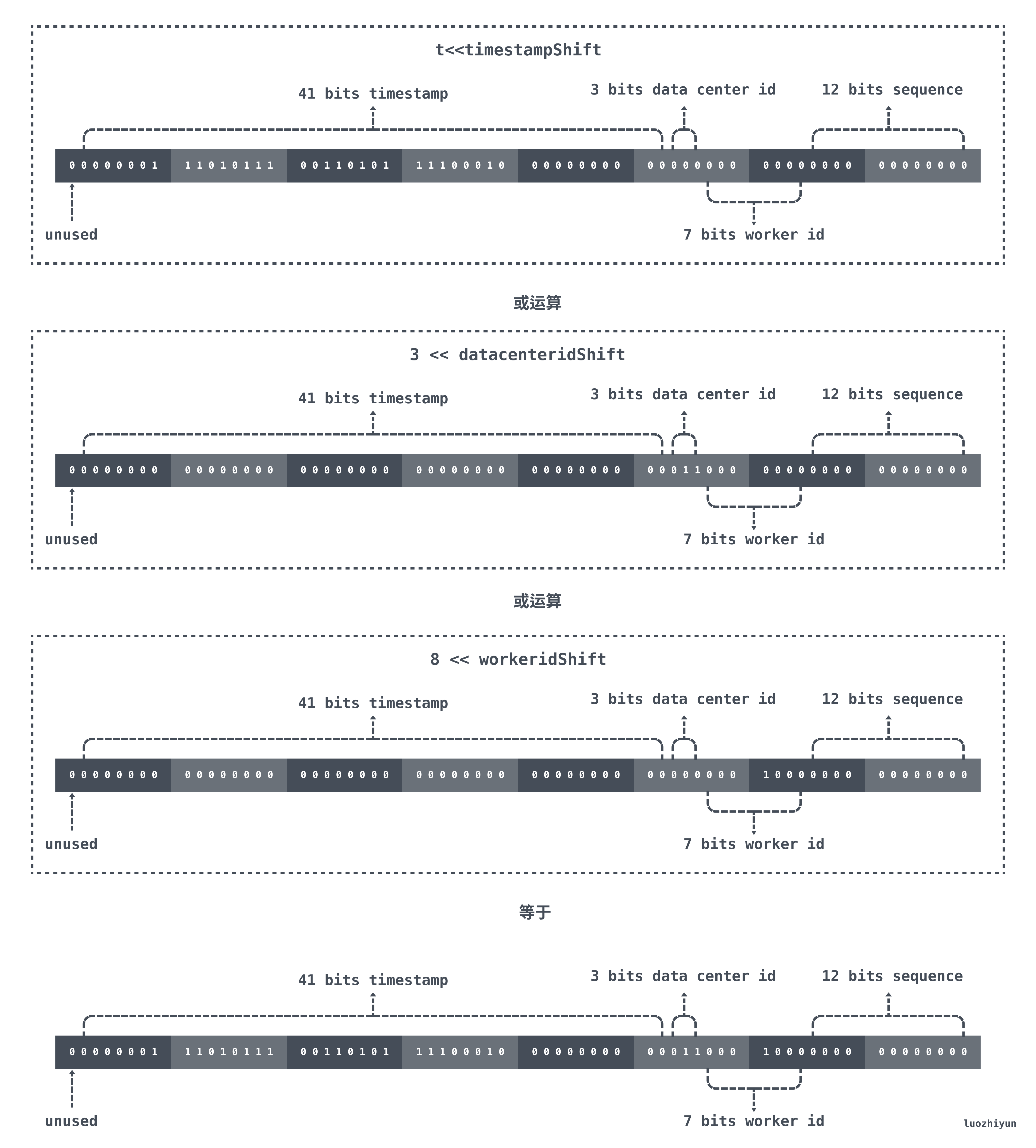
首先 t 表示的是现在距离 epoch 的时间差,我们 epoch
在初始化的时候设置的是2020-01-01 00:00:00,那么对于 41bit 的
timestamp 来说会在 69 年之后才溢出。对 t 进行向左位移之后,低于
timestampShift 位置上全是0 ,由 datacenterid、workerid、sequence
进行取或填充。
得到时间戳和机器码之后,通过或运算来得到最终的id:
- 将时间戳左移41位
- 将机器码左移12位
- 将序列号和左移之后的时间戳和左移之后的机器码做或运算得到最终的id号
在当前的例子中,如果当前时间是2021/01/01 00:00:00,那么位运算结果如下图所示:
JWT验证
这里使用和JWT-go库来实现,生成JWT和JWT解析的功能。
见基于Cookie、Session和基于Token的认证模式介绍
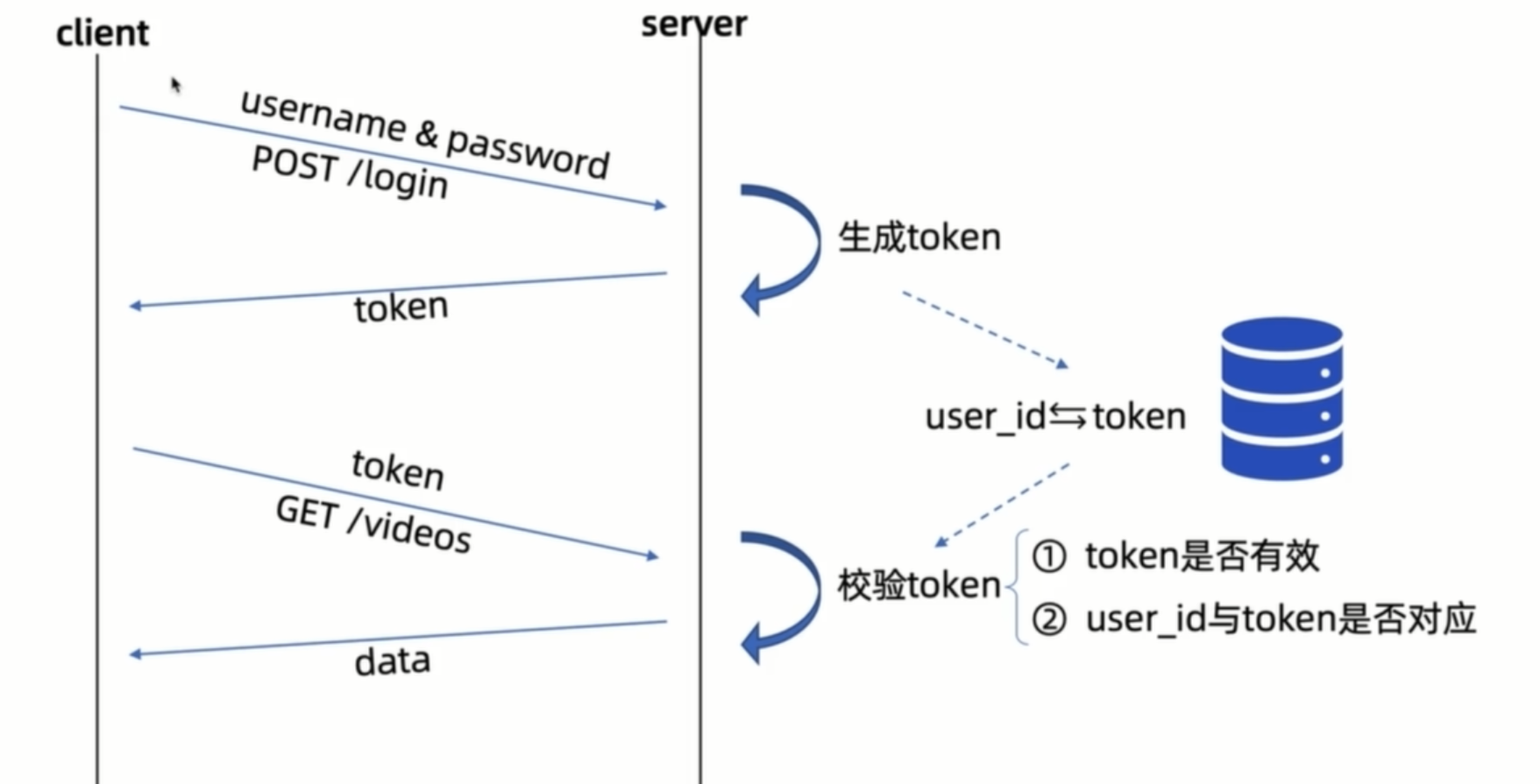
限制账号同一时间只能登录一个设备
思路是使用redis存储一个从user_id到token的映射,每次用户登录时,更新或替换这个 Token。每次请求时验证客户端 Token 是否与服务器端存储的 Token 一致。如果不一致,拒绝请求。新登录会使之前的 Token 失效,从而实现每个用户只能同时在一个设备上登录。
swag生成文档
写注释
在main函数中添加注释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23package main
// @title 这里写标题
// @version 1.0
// @description 这里写描述信息
// @termsOfService http://swagger.io/terms/
// @contact.name 这里写联系人信息
// @contact.url http://www.swagger.io/support
// @contact.email support@swagger.io
// @license.name Apache 2.0
// @license.url http://www.apache.org/licenses/LICENSE-2.0.html
// @host 这里写接口服务的host
// @BasePath 这里写base path
func main() {
r := gin.New()
// liwenzhou.com ...
r.Run()
}在controller中的函数添加注释:
1
2
3
4
5
6
7
8
9
10
11
12// GetPostListHandler2 升级版帖子列表接口
// @Summary 升级版帖子列表接口
// @Description 可按社区按时间或分数排序查询帖子列表接口
// @Tags 帖子相关接口(api分组展示使用的)
// @Accept application/json
// @Produce application/json
// @Param Authorization header string true "Bearer JWT"
// @Param object query models.ParamPostList false "查询参数"
// @Security ApiKeyAuth
// @Success 200 {object} _ResponsePostList
// @Router /posts2 [get]
func GetPostListHandler2(c *gin.Context)上面注释中参数类型使用了
object,models.ParamPostList具体定义如下:1
2
3
4
5
6
7
8
9// bluebell/models/params.go
// ParamPostList 获取帖子列表query string参数
type ParamPostList struct {
CommunityID int64 `json:"community_id" form:"community_id"` // 可以为空
Page int64 `json:"page" form:"page" example:"1"` // 页码
Size int64 `json:"size" form:"size" example:"10"` // 每页数据量
Order string `json:"order" form:"order" example:"score"` // 排序依据
}响应数据类型也使用的
object,我个人习惯在controller层专门定义一个docs_models.go文件来存储文档中使用的响应数据model。1
2
3
4
5
6
7
8// bluebell/controller/docs_models.go
// _ResponsePostList 帖子列表接口响应数据
type _ResponsePostList struct {
Code ResCode `json:"code"` // 业务响应状态码
Message string `json:"message"` // 提示信息
Data []*models.ApiPostDetail `json:"data"` // 数据
}安装并初始化swag
1
go install github.com/swaggo/swag/cmd/swag@latest在项目根目录执行以下命令,使用swag工具生成接口文档数据。
1
swag init执行完上述命令后,如果你写的注释格式没问题,此时你的项目根目录下会多出一个
docs文件夹。1
2
3
4./docs
├── docs.go
├── swagger.json
└── swagger.yaml引入gin-swagger渲染文档数据
然后在项目代码中注册路由的地方按如下方式引入
gin-swagger相关内容:1
2
3
4
5
6
7
8
9
10
11
12
import (
// liwenzhou.com ...
_ "bluebell/docs" // 千万不要忘了导入把你上一步生成的docs
gs "github.com/swaggo/gin-swagger"
"github.com/swaggo/gin-swagger/swaggerFiles"
"github.com/gin-gonic/gin"
)注册swagger api相关路由
1
r.GET("/swagger/*any", gs.WrapHandler(swaggerFiles.Handler))把你的项目程序运行起来,打开浏览器访问http://localhost:8080/swagger/index.html就能看到Swagger 2.0 Api文档了。
压测
ping
在windows本地运行本地使用ab测试:
1 thread: 3221.69
2 thread: 4875
4 threads: 5621
再翻倍qps基本没有变化,甚至更低了
阿里云:
1 thread: 6800
2 threads: 16369.96
3 threads: 18000
4 threads: 18000
8threads: 18000
从本地windows向阿里云服务器部署的项目压测:
1 thread: 20
2 thread2: 54
4 theads: 52.79
阿里云:
get请求: ab -n 10000 -c 4 -t 10 "http://127.0.0.1:8084/api/v1/posts?size=10", qps 2050
1 thread: 500
2 threads: 800
3 threads: 1000
4 threads: 1000
QA
介绍一下你的项目
bluebell项目你就介绍一下用户注册和登录功能怎么实现的,帖子投票功能怎么实现的,排行榜怎么实现的。注册登录功能可以提一下雪花算法。
为什么要先实现登录注册?
我们因为业务需求需要把不同的请求需求分离开,比如有登录注册的路由,还有一些其他的路由,而一些功能是需要登录之后才可以使用的(比如视频网站的高清)。
使用JWT的方式怎么测试
客户端携带token有三种方式:
- 放在请求头
- 放在请求体
- 放在url里
放在url里边肯定是不安全的,这里是放在请求头,在postman里边,authorization里面有一个Bearer Token.把之前登录/注册生成的token放进去就可以,如果需要与前端沟通的情况下,需要修改对token 的处理,目前是对Bearer Token处理的方法,使用其他的token传递方式会出问题。
实际发出去的请求头的数据如下所示:
1 | |
为什么用.分为三段见前面的JWT。
怎么按分数/时间获取community下最高的10个帖子?
在redis中用一个set记录一个community下的所有帖子id,用一个zset记录所有帖子的评分,那么可以对二者做一个zinterstore得到一个新的zset,新的zset存储该community下的帖子分数排行,如下图所示:
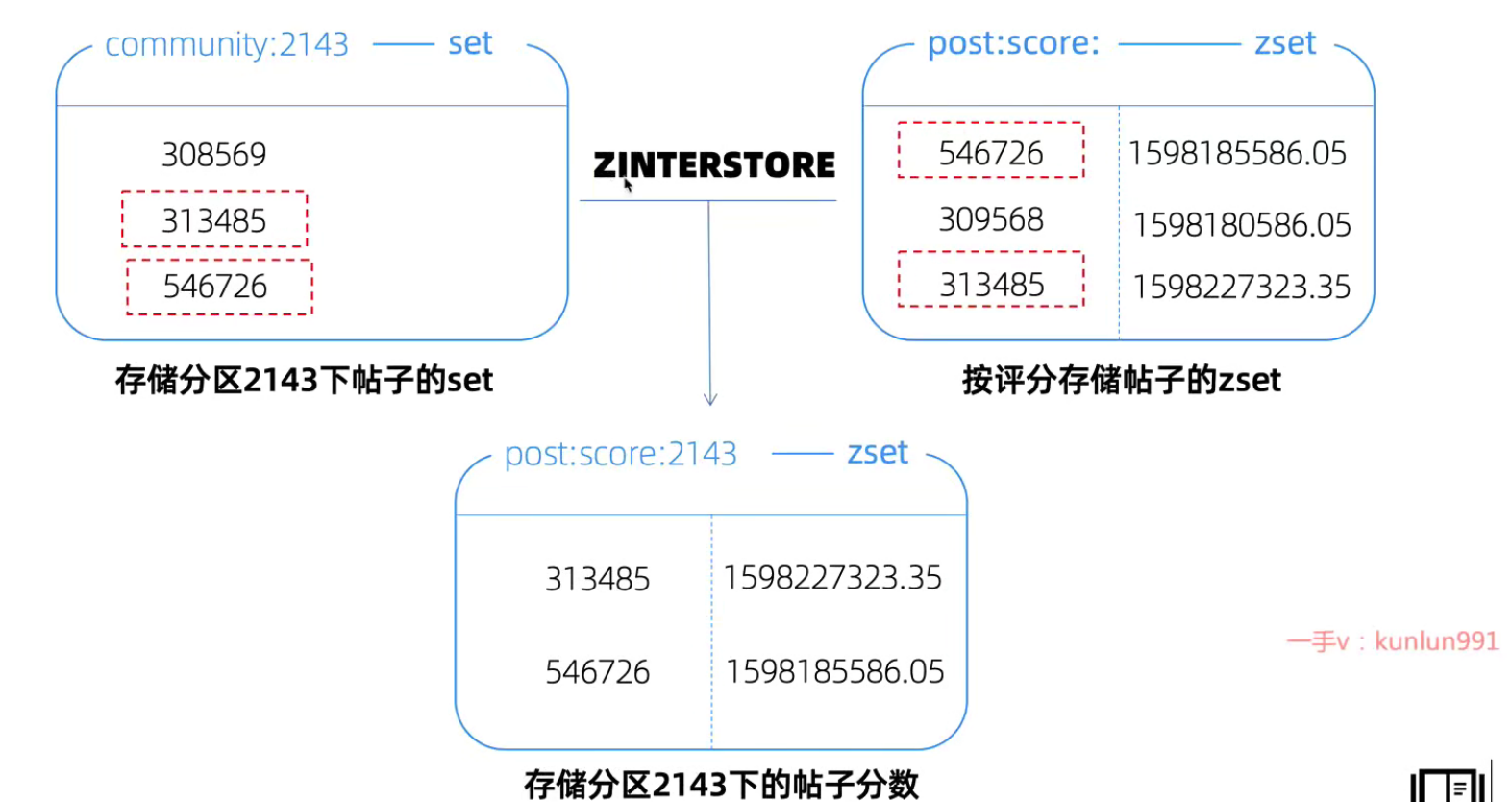
有什么心得/经验?
返回错误的时候不要对外返回过多的信息
比如CommunityHandler()中,查询到所有的社区(community_id, community_name) 以列表的形式返回,当logic.GetCommunityList()返回的err不为空的时候,使用zap将错误原因记录在日志中,而不对前端和用户返回过多的信息,同意对外返回CodeServerBusy.
1 | |
关于错误返回
众所周知,现在的项目一般都是分为三层:controller、logic、dao层,再加一个model层定义数据库对应的结构。那么controller、logic、dao这三层的函数应该按照什么规则返回呢?。。
首先dao层是直接与数据库交互的,所以出错的时候可以根据查询结果返回err,而logic层是调用dao层的函数来与数据库交互,所以logic层一般不对这个错误进行处理,而是直接返回给上一层的controller,controller层是首先是对数据进行校验,然后调用下面的层处理业务。如果数据校验失败,会直接返回错误;如果在调用下面的层执行业务的之后出错,根据上面的返回错误的时候不要对外返回过多的信息原则,在日志中记录错误原因,然后对错误进行封装然后返回,避免返回给前端和用户过多的信息。
关于业务代码怎么写
有时候可能拿到需求之后,知道怎么做,但是开始写的时候发现不知道从哪下手,可以考虑先把每一层做的东西明确,然后依次实现router、controller、logic、dao层;
如何实现每一个层?比如logic层的业务逻辑很复杂,要做的东西很多,不知道怎么下手,可以先梳理一下该层要做的事情,然后用注释的方式将需要做的事情排序,然后用代码实现每一步的业务逻辑。
dao层注意事项
dao层免不了要和数据库交互,那么就需要sql语句,在使用sql语句的时候一定要注意,不要拼接sql语句的字符串,因为可能会被sql注入。
Q:不使用字符串拼接的方法怎么在sql语句中添加代码中的变量?
A:可以使用?通配符来代替字符串拼接,从而防止sql注入
Q:
为什么使用?的方式可以避免sql注入?
A:使用通配符?的方式,可以使sql与参数分离,,当sql语句被数据库接收的时候,数据库会先先对sql语句进行预编译,生成一个执行计划,此时SQL
语句只包含占位符,不包含具体的参数值。在 SQL
语句执行时,具体的参数值被绑定到预编译好的占位符上,这些参数被数据库驱动程序处理成字面量数据,而不是代码。
给前端传递数字的数字失真问题
前端js传递过来的格式是json格式的,但是js在IEEE 754中规定的双浮点范围是-(2^53) ~ 2^53 - 1。而雪花算法产生的id是int64类型,范围是-(2^64) ~ 2^64 - 1
解决方案:
传递uid的时候改为传string,后端传递给前端数据的时候将int64转为string然后返回,前端给后端返回数据的时候发送string,然后后端再处理转为int64.最简单的方式是在结构体声明的时候就声明为string类型,然后在序列化之后再将string转换为int64。但是Go语言提供了一个更好的方法,如下所示:
1 | |
redis命令使用pipline优化
在查找帖子的时候需要查找每个帖子的投票数据,然后计算每个帖子的分数,而每个帖子的投票数据是用一个zset来存储的,常规的做法是遍历每个帖子,然后计算这个帖子的赞成票数。
一个更优的做法是使用pipline依次将对每个帖子赞成票数的查询命令打包成一个请求,然后发送,这样可以减少redis的网络延迟,如果依次执行每个命令的话,每个命令都有一个单独的网络往返延迟。
1 | |
限定json数据中某个字段值的范围
validator库中有一个one of字段,如下所示:
1 | |
sqlx库
有哪些改进地方?
- 结构体映射:
sqlx允许将数据库查询的结果映射到 Go 结构体中,简化了数据的处理和访问。 - 命名参数: 支持使用命名参数执行查询,使得 SQL 语句更易读且更易维护。
- Null 值支持: 对于可能为 NULL
的字段,
sqlx提供了null类型,以方便地处理这些情况。 - 更丰富的查询方法:
sqlx提供了一些额外的查询方法,如Get、Select,使得执行查询更加方便。 - 数据库连接池: 支持数据库连接池,提高了在并发环境中的性能。
- 支持多种数据库:
sqlx可以与多种数据库一起使用,包括 PostgreSQL、MySQL、SQLite 等。 - 原生 SQL 支持:
sqlx支持使用原生的 SQL 语句,同时也支持使用预处理语句。 - 扫描任意类型:
sqlx具有更灵活的Scan方法,可以直接将查询结果映射到任意类型。
怎么使用go操作mysql和redis?
gin框架怎么使用
还有哪些投票算法
Delicious、Hacker news、reddit、stackoverflow、牛顿冷却定律、威尔逊区间、贝叶斯平均。
### 面试拓展:
用redis实现百万用户游戏积分排行榜
Redis是一个高性能的内存数据存储系统,对于游戏的积分排行榜来说非常适合。可以通过以下步骤来实现百万用户游戏积分排行榜:
1使用Redis的Sorted Set数据结构存储用户积分:将用户ID作为成员,积分作为分数,每当用户得分变化时,通过ZADD命令更新积分。
2使用ZREVRANGE命令获取排行榜:该命令可以根据分数的降序返回成员,从而实现排行榜。
3使用Hash数据结构存储用户详细信息:将用户ID作为键,用户详细信息(例如用户名、头像等)作为值,可以通过HGET命令快速获取用户详细信息。
这样,通过排序集合和哈希数据结构的结合,就可以实现高效、稳定的百万用户游戏积分排行榜。
可以改进的地方
- 用户投票算法
- 实现refresh token