tensort学习记录
tensorRT学习记录
基础概念
目标检测的mAP
AP & mAP
- AP:PR 曲线下面积
- mAP:mean Average Precision, 即各类别 AP 的平均值
TP、FP、FN、TN
- True Positive (TP)
- False Positive (FP)
- False Negative (FN)
- True Negative (TN)
查准率、查全率
- 查准率(Precision): TP/(TP + FP)
- 查全率(Recall): TP/(TP + FN)
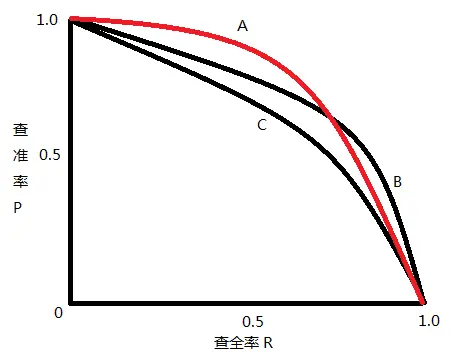
二者绘制的曲线称为 P-R 曲线
交并比 - Intersection Over Union (IOU)
交并比(IOU)是度量两个检测框(对于目标检测来说)的交叠程度,公式如下:
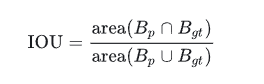
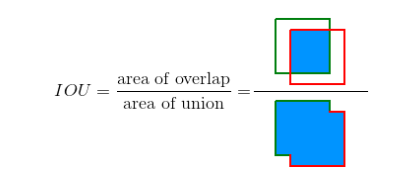
\(B_{gt}\) 代表的是目标实际的边框(Ground Truth,GT),\(B_p\) 代表的是预测的边框,通过计算这两者的 IOU,可以判断预测的检测框是否符合条件,IOU 用图片展示如下:
评价指标 mAP
先规定两个公式,一个是 Precision,一个是
Recall,这两个公式同上面的一样,我们把它们扩展开来,用另外一种形式进行展示,其中
all detctions 代表所有预测框的数量,
all ground truths 代表所有 GT 的数量。
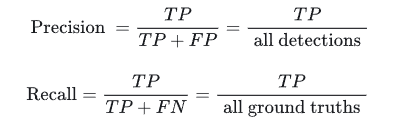
AP 是计算某一类 P-R 曲线下的面积,mAP 则是计算所有类别 P-R 曲线下面积的平均值。
Object Detection算法
RCNN
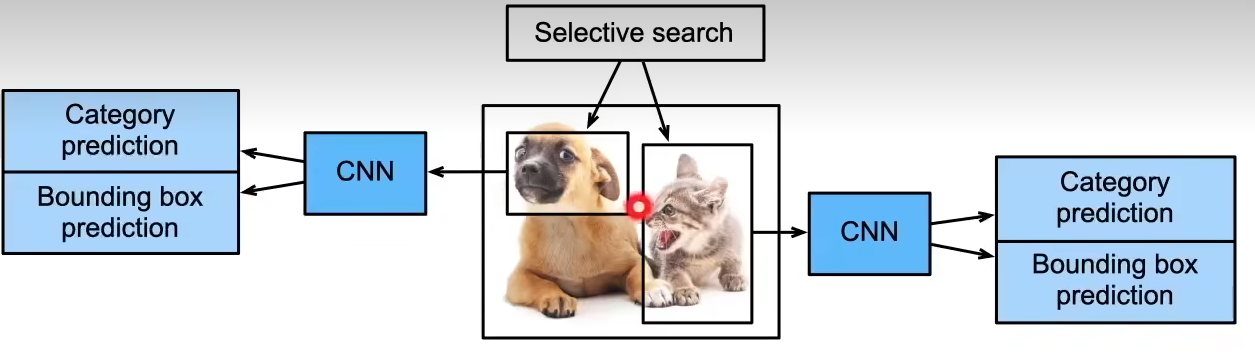
- 使用启发式搜索算法选择锚框
- 使用预训练模型对每个锚框抽取特征
- 训练一个SVM来对类别分类
- 训练一个线性回归模型来预测边缘框偏移
选择了不同的锚框大小是不一样的,那么怎么让这些锚框最后变成一个batch呢?
这里使用了ROI pooling:
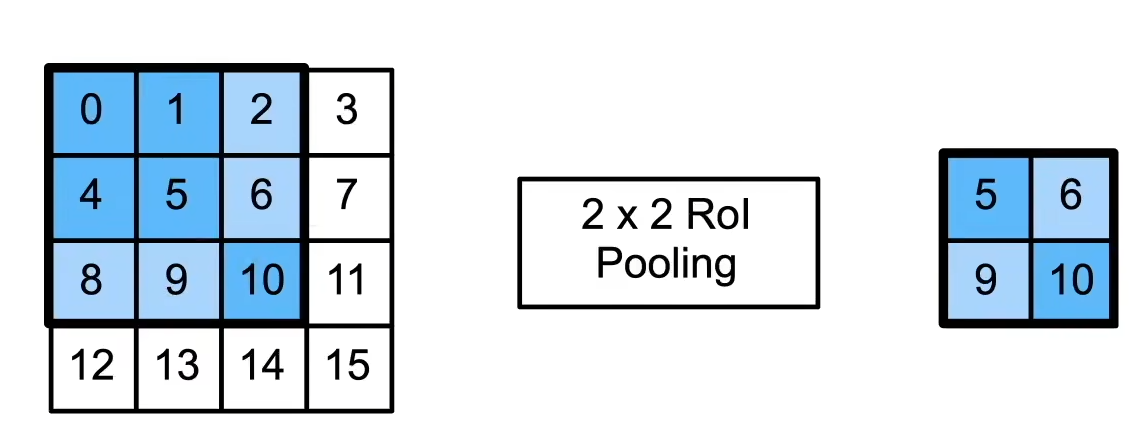
- 给定一个锚框,均匀分割成n × m块,输出每块里的最大值
- 不管锚框多大,总是输出n × m个值
尽管 R-CNN 模型通过预训练的卷积神经网络有效地抽取了图像特征,但是速度非常慢(如果从一张图片中选取了上千个提议区域,就需要上千次的卷积神经网络的前向传播来执行目标检测,计算量非常大)
Fast RCNN
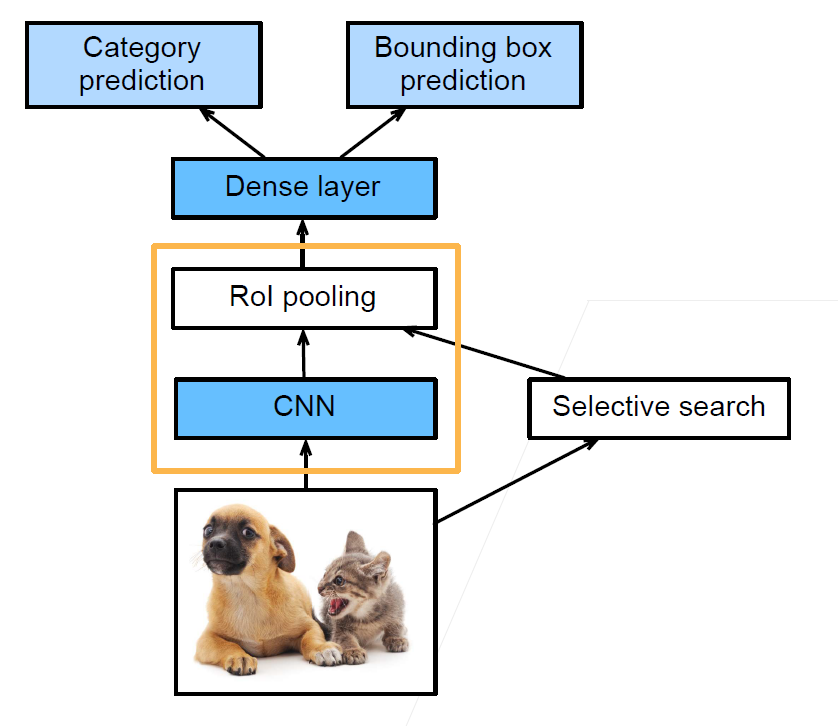
- 使用CNN对图片抽取特征
- 在原图片上使用启发式搜索算法选择锚框,并将其映射到提取特征后的feature上
- 使用RoI池化层对每个锚框生成固定长度特征
- 使用全连接层分类
和RCNN相比,Fast RCNN不用使用CNN对每个锚框提取特征了,它是对整个图片进行特征抽取,选出来的有重叠的锚框不需要多次计算。
Faster RCNN
- 使用一个区域提议网络来代替启发式搜索来获得更好的锚框。
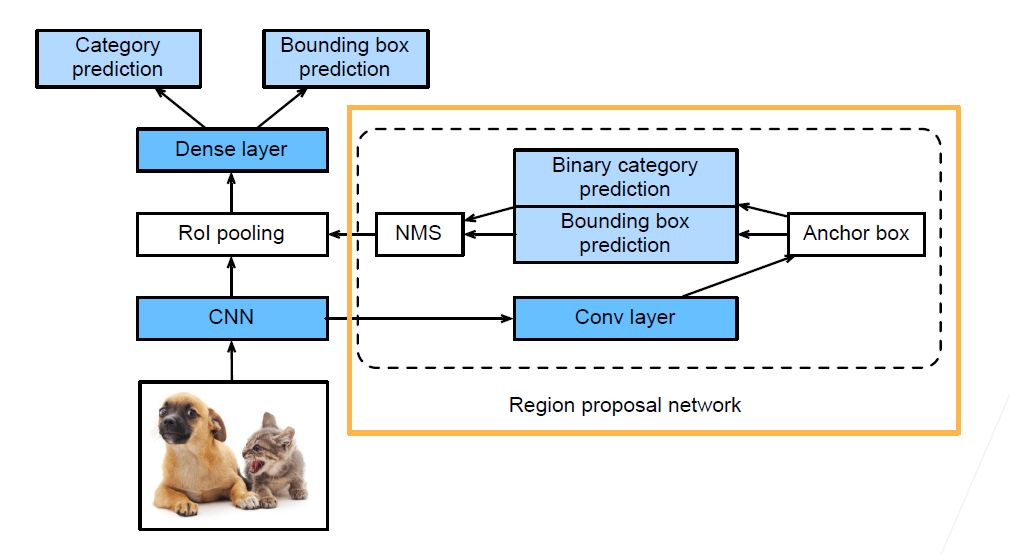
Faster RCNN和Fast RCNN不同的是之前的区域选择算法更换成了一个RPN(Region proposal network)。这个RPN可以理解为一个比较粗糙的目标检测网络,在下面这部分做了一个二分类,判断生成的锚框是否是高质量的锚框,这样一些低质量的锚框就会被过滤掉,然后在剩余的高质量锚框中,使用NMS(非极大值抑制)来渡桥模型预测后的多余框.

区域提议网络的计算步骤:

- 区域提议网络作为Faster R-CNN 模型的一部分,是和整个模型一起训练得到的(Faster R-CNN 的目标函数不仅包括目标检测中的类别和边界框预测,还包括区域提议网络中锚框的二元类别和边界框预测)
- 作为端到端训练的结果,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少了从数据中学习的提议区域的数量的情况下,仍然保持了目标检测的精度
NMS的思路如下:
- 选取这类box中scores最大的那一个,记为box_best,并保留它
- 计算box_best与其余的box的IOU
- 如果其IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保留分数高的哪一个)
- 从最后剩余的boxes中,再找出最大scores的哪一个,如此循环往复
经过NMS之后留下的锚框才会经过RoI Pooling以及后续阶段.
Mask R-CNN
如果在训练集中还标注了每个目标在图像上的像素级位置,Mask R-CNN 能够有效地利用这些相近地标注信息进一步提升目标检测地精度.
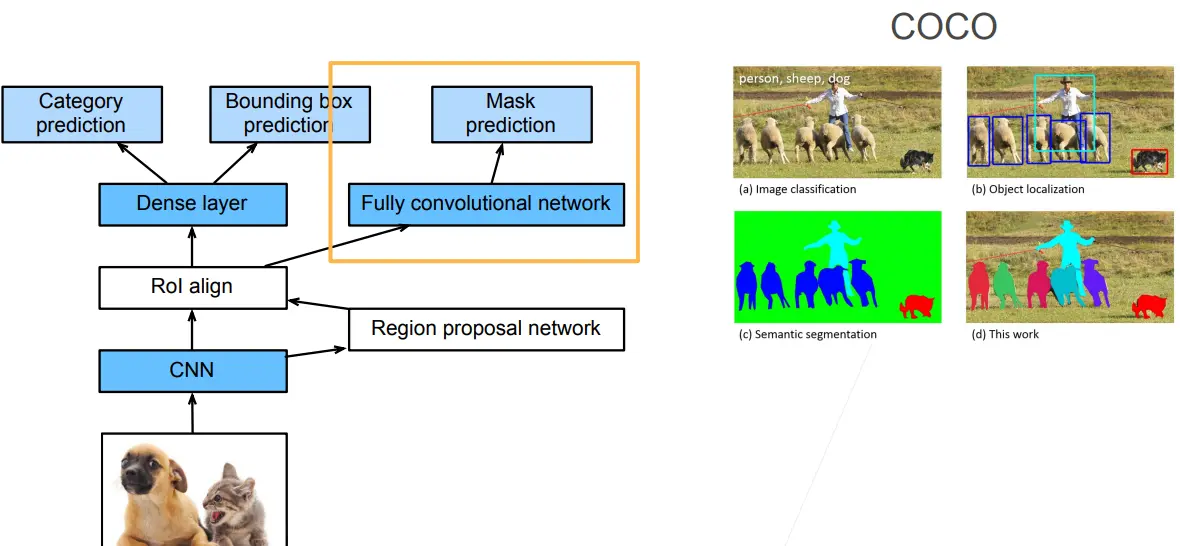
Mask R-CNN 是基于 Faster R-CNN 修改而来的,改进在于
- 假设有每个像素的标号的话,就可以对每个像素做预测(FCN)
- 将兴趣区域汇聚层替换成了兴趣区域对齐层(RoI pooling -> RoI align),使用双线性插值(bilinear interpolation)保留特征图上的空间信息,进而更适于像素级预测:对于pooling来说,假如有一个3 * 3的区域,需要对它进行2 * 2的RoI pooling操作,那么会进行取整从而切割成为不均匀的四个部分,然后进行 pooling 操作,这样切割成为不均匀的四部分的做法对于目标检测来说没有太大的问题,因为目标检测不是像素级别的,偏移几个像素对结果没有太大的影响。但是对于像素级别的标号来说,会产生极大的误差;RoI align 不管能不能整除,如果不能整除的话,会直接将像素切开,切开后的每一部分是原像素的加权(它的值是原像素的一部分)
- 兴趣区域对齐层的输出包含了所有与兴趣区域的形状相同的特征图,它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置
RoI Align:引入了一个插值过程,先通过双线性插值到1414,再 pooling到77,很大程度上解决了仅通过 Pooling 直接采样带来的 Misalignment 对齐问题。虽然 Misalignment 在分类问题上影响并不大,但在 Pixel 级别的 Mask 上会存在较大误差。
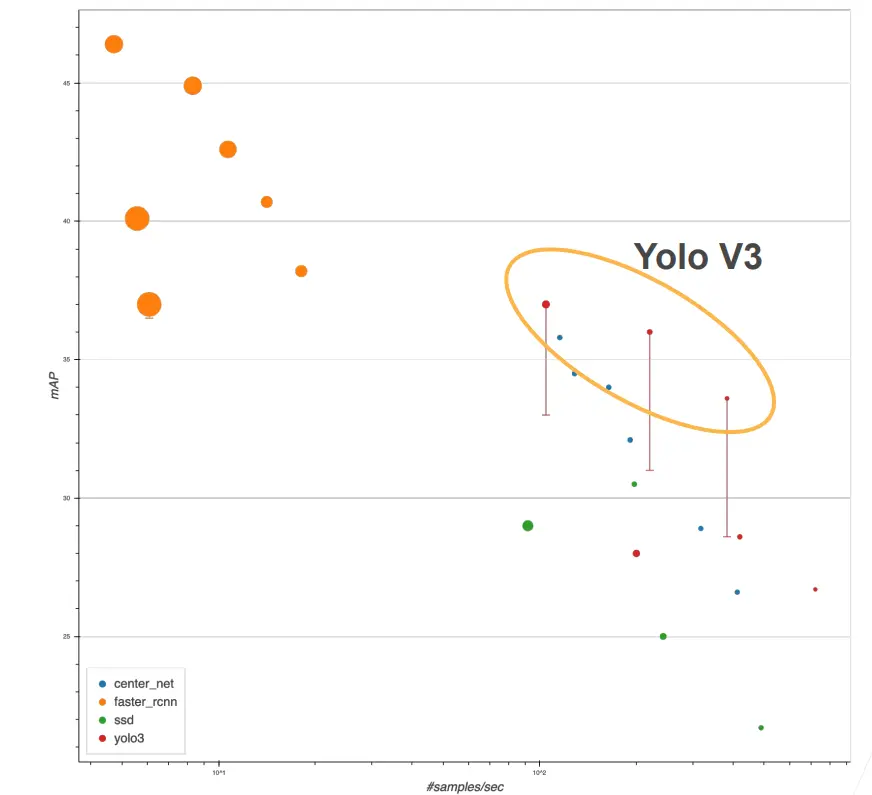
模型精度比较
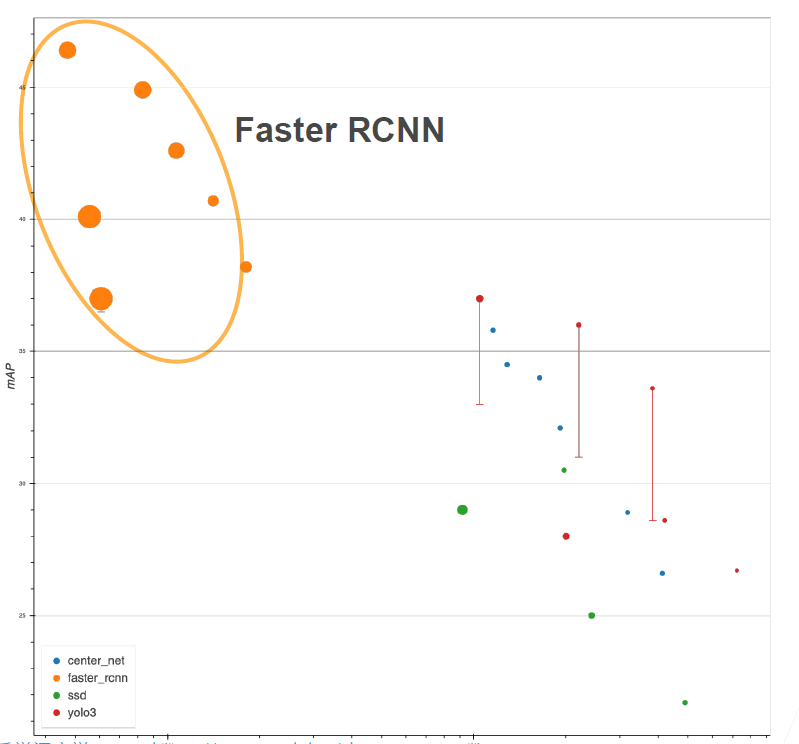
- x 轴表示模型的运行速度,越往右表示模型的速度越快,越往左越慢
- y 轴表示 mAP(可以简单认为是边界框的预测精度),越往上表示精度越高
- 图中圆圈的大小表示内存的使用
- Faster RCNN 相对来说精度比较高,但是它在精度提升的同时,样本的处理速度也在变慢(所以只有在对精度
小结
RCNN系列都是两阶段(Two-Stage)的算法,它们的思想都是先做一个粗糙一点的预测,然后做一个更精准的预测.不同的是Fast RCNN通过先对图片提取特征来减少重复计算,而Faster RCNN又在这个基础之上通过一个RPN来获得更好的锚框.
- R-CNN 是最早、也是最有名的一类基于锚框和 CNN 的目标检测算法(R-CNN 可以认为是使用神经网络来做目标检测工作的奠基工作之一),它对图像选取若干提议区域,使用卷积神经网络对每个提议区域执行前向传播以抽取其特征,然后再用这些特征来预测提议区域的类别和边框
- Fast/Faster R-CNN持续提升性能:Fast R-CNN 只对整个图像做卷积神经网络的前向传播,还引入了兴趣区域汇聚层(RoI pooling),从而为具有不同形状的兴趣区域抽取相同形状的特征;Faster R-CNN 将 Fast R-CNN 中使用的选择性搜索替换为参与训练的区域提议网络,这样可以在减少提议区域数量的情况下仍然保持目标检测的精度;Mask R-CNN 在 Faster R-CNN 的基础上引入了一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度
- Faster R-CNN 和 Mask R-CNN 是在追求高精度场景下的常用算法(Mask R-CNN 需要有像素级别的标号,所以相对来讲局限性会大一点,在无人车领域使用的比较多)
单发多框检测(SSD)
R-CNN系列都是要两阶段(如先过一遍RPN然后再做预测),而下面的一类算法只需要过一遍就可以完成检测.
对每个像素生成多个以它为中心的多个锚框:


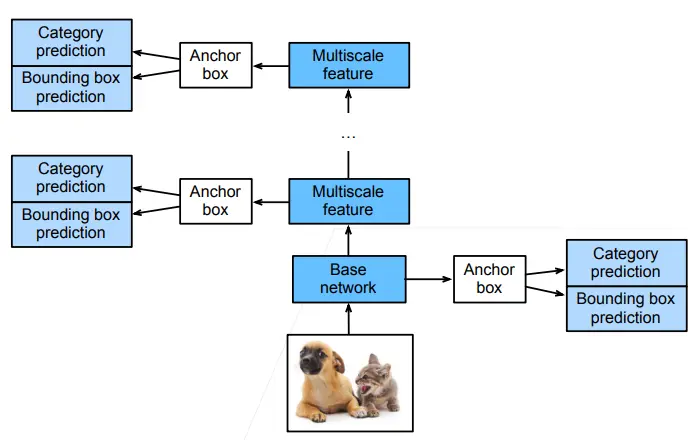
- 输入图像之后,首先进入一个基础网络来抽取特征,抽取完特征之后对每个像素生成大量的锚框(每个锚框就是一个样本,然后预测锚框的类别以及到真实边界框的偏移)
- SSD 在给定锚框之后直接对锚框进行预测,而不需要做两阶段(为什么 Faster RCNN 需要做两次,而 SSD 只需要做一次?SSD 通过做不同分辨率下的预测来提升最终的效果,越到底层的 feature map,就越大,越往上,feature map 越少,因此底层更加有利于小物体的检测,而上层更有利于大物体的检测)
- SSD 不再使用 RPN 网络,而是直接在生成的大量样本(锚框)上做预测,看是否包含目标物体;如果包含目标物体,再预测该样本到真实边缘框的偏移
模型精度:
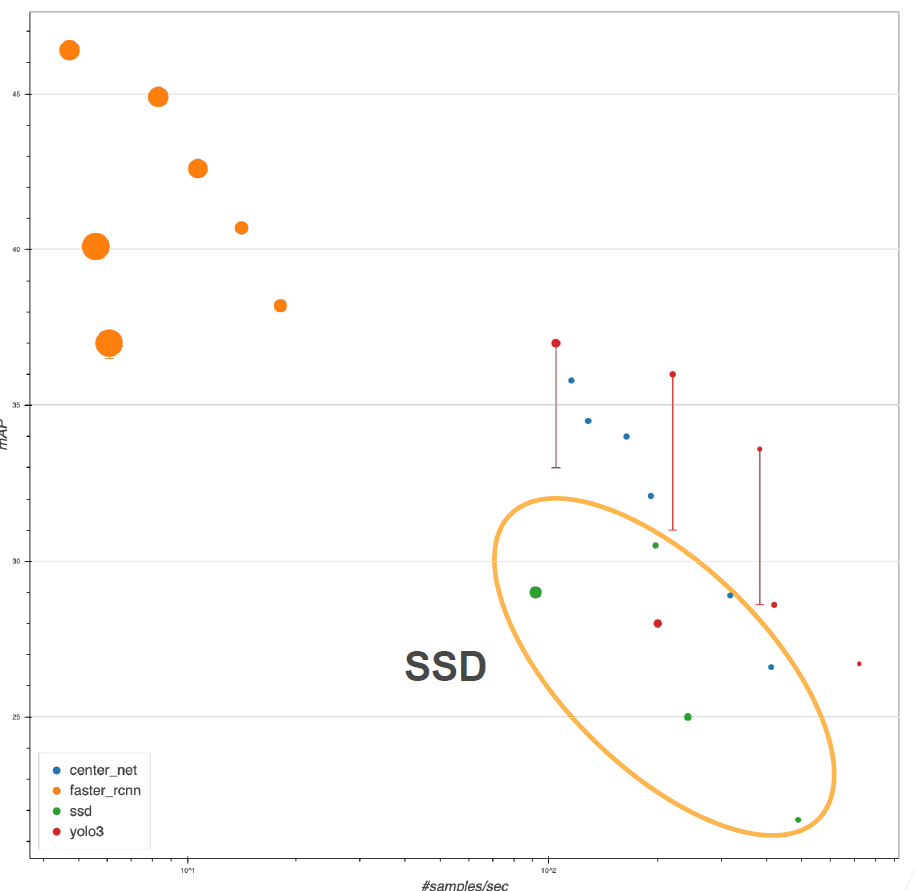
- 上图中绿色的点表示 SSD
- 从图中可以看出,SSD 相对于Faster RCNN 来讲速度快很多,但是精度不是太好
- SSD 的实现相对来讲比较简单,R-CNN 系列代码的实现非常困难
小结
- SSD通过单神经网络来检测模型
- 以每个像素为中心产生多个锚框
- 在多个段的输出上进行多尺度的检测(底层检测小物体,上层检测大物体)
YOLO
- yolo 也是一个 single-stage 的算法,只有一个单神经网络来做预测
- yolo 也需要锚框,这点和 SSD 相同,但是 SSD 是对每个像素点生成多个锚框,所以在绝大部分情况下两个相邻像素的所生成的锚框的重叠率是相当高的,这样就会导致很大的重复计算量。
- yolo 的想法是尽量让锚框不重叠:首先将图片均匀地分成 S * S 块,每一块就是一个锚框,每一个锚框预测 B 个边缘框(考虑到一个锚框中可能包含多个物体),所以最终就会产生 S ^ 2 * B 个样本,因此速度会远远快于 SSD
- yolo 在后续的版本(V2,V3,V4...)中有持续的改进,但是核心思想没有变,真实的边缘框不会随机的出现,真实的边缘框的比例、大小在每个数据集上的出现是有一定的规律的,在知道有一定的规律的时候就可以使用聚类算法将这个规律找出来(给定一个数据集,先分析数据集中的统计信息,然后找出边缘框出现的规律,这样之后在生成锚框的时候就会有先验知识,从而进一步做出优化)
模型精度
- 上图中表示 yolo v3 的直线底端表示论文中的原始精度,顶端表示通过改进之后所能达到的最大精度
center net
- 基于非锚框的目标检测
- center net 的优点在于简单
- center net 会对每个像素做预测,用 FCN 对每个像素做预测(类似于图像分割中用 FCN 对每个像素标号),预测该像素点是不是真实边缘框的中心点(将目标检测的边缘框换算成基于每个像素的标号,然后对每个像素做预测,就免去了一些锚框相关的操作)
YOLO详解
YOLOv1
step1:
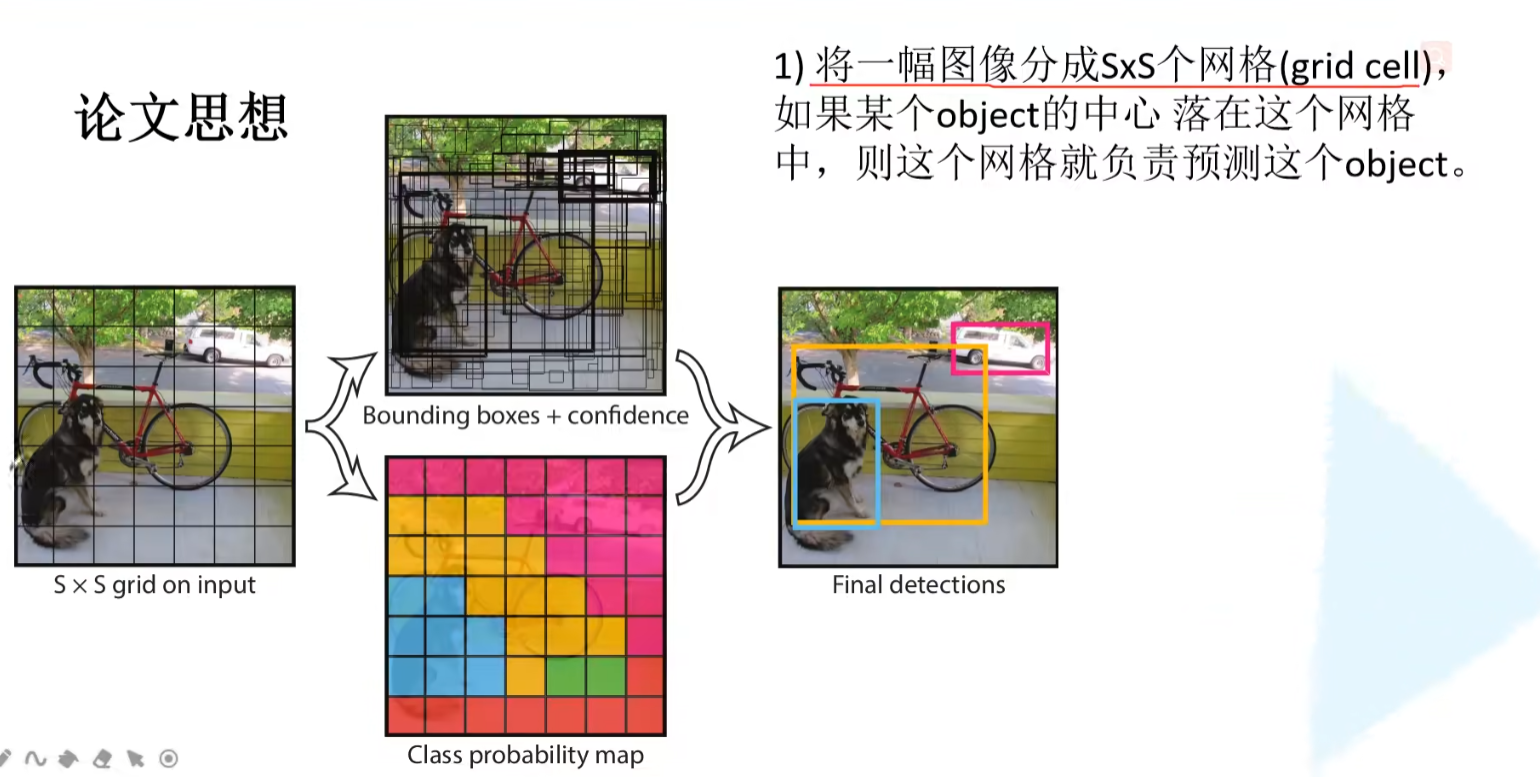
step2:
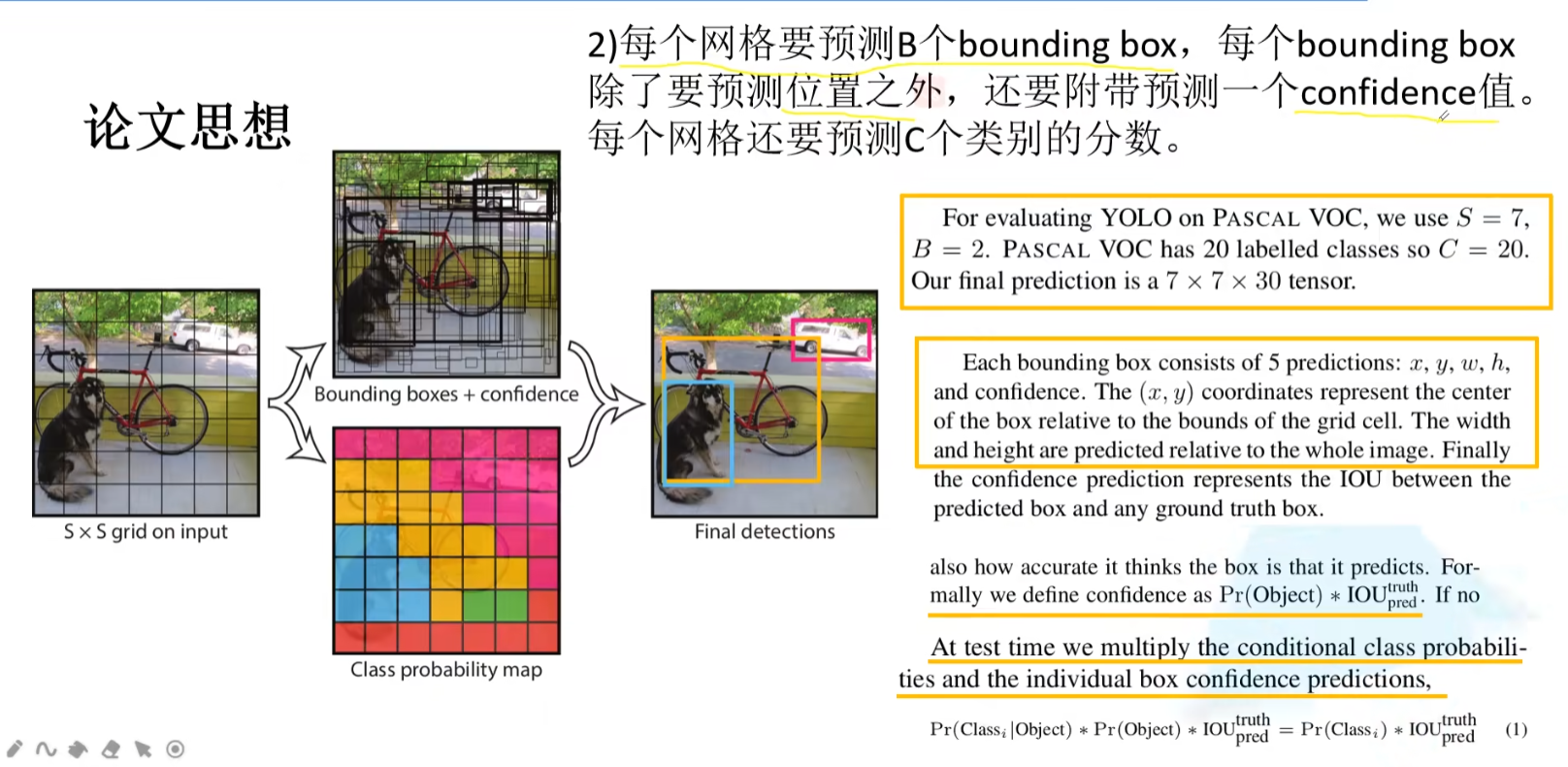
每一个grid需要预测2个bounding box。每个bounding
box有5个值,分别是4个位置(x,y,w,h),和一个yolo系列独有的置信度confidence。confidence简单理解为预测边界框与标注边界框的IOU * 是否有目标,即预测边界框与标注边界框的重合程度。
以VOC数据集为例,20个类别,每个grid cell需要预测一个长度为30的tensor(2组x,y,w,h,confidence和20个类别分数).
每个类别分数如下图:
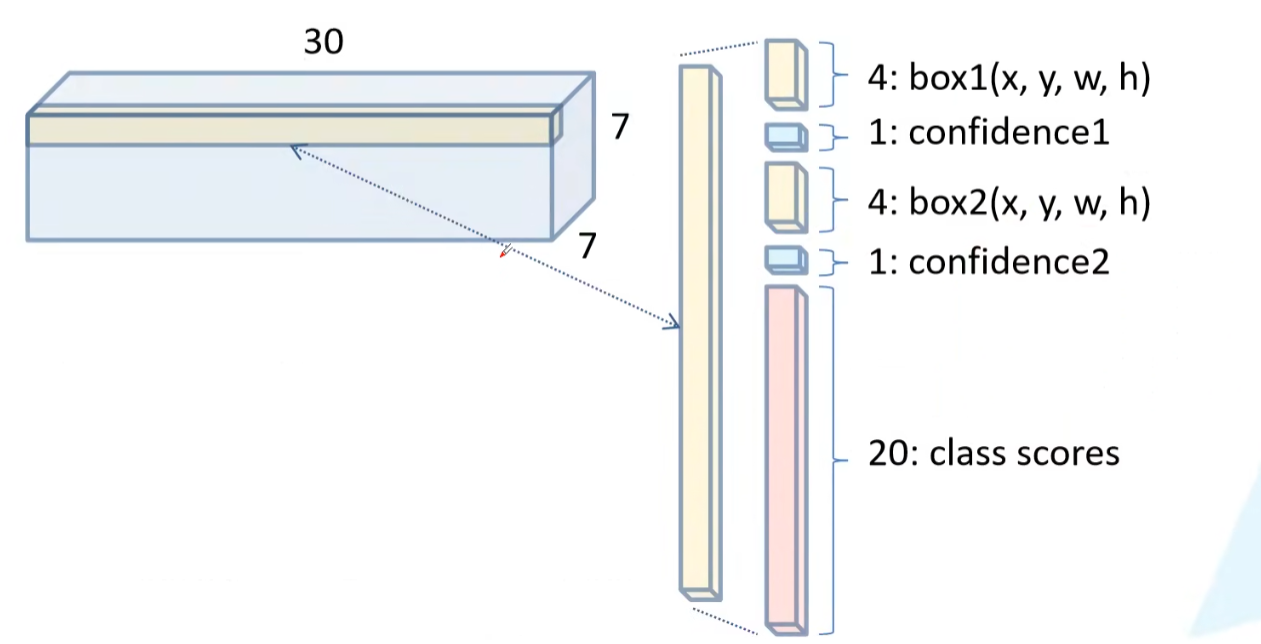
- 最终预测目标概率为:目标类别分数*confidece
网络结构
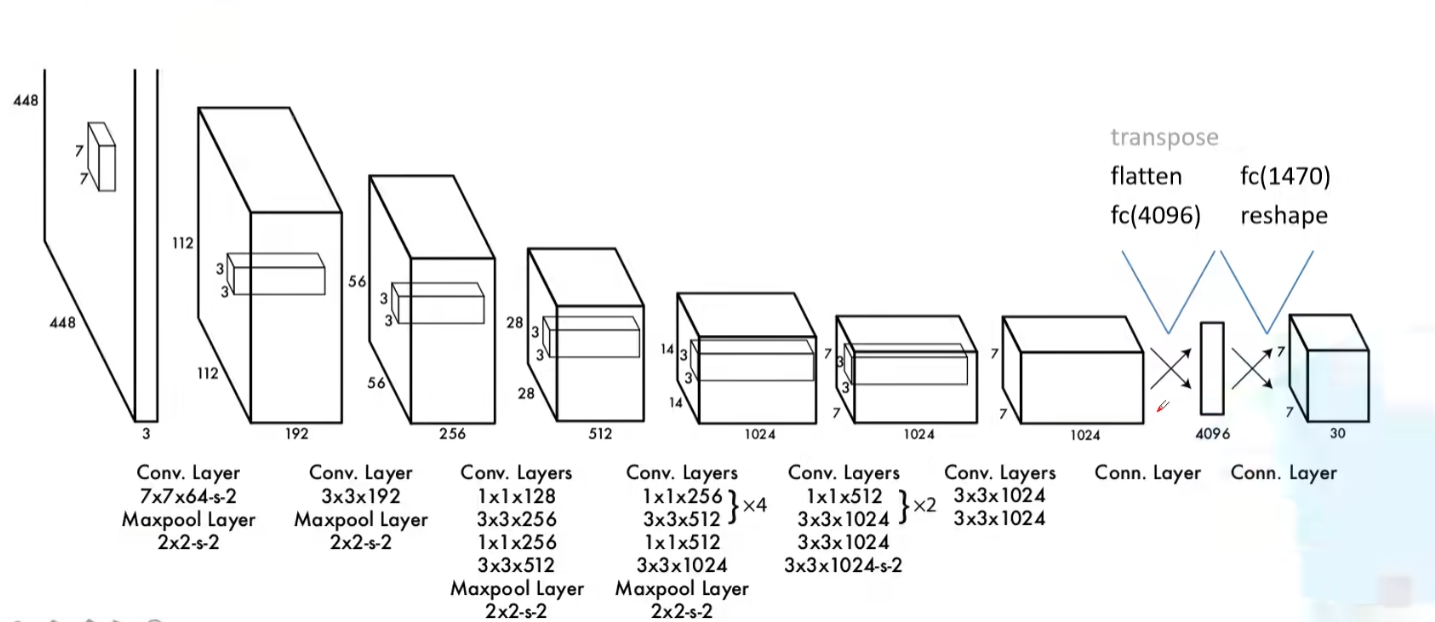
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
损失函数

不足之处
- 对于群体型的小目标,检测能力很差。
- 对于未训练过的新尺寸目标,检测能力很差。
- 主要错误原因来自于定位不准确。
YOLOv2

Batch Normalization
- BN的本质原理:在网络的每一层输入的时候,又插入了一个归一化层,也就是先做一个归一化处理(归一化至:均值0、方差为1),它是一个可学习、有参数(γ、β)的网络层。
- 作用:解决在训练过程中,中间层数据分布发生改变的问题,以防止梯度消失或爆炸、加快训练速度,加快算法收敛速度。
检测系列的网络结构中,BN逐渐变成了标配。在Yolo的每个卷积层中加入BN之后,mAP提升了2%,并且去除了Dropout。
BN大体可以分为四步:
- 计算出均值
- 计算出方差
- 归一化处理到均值为0,方差为1
- 变化重构,恢复出这一层网络所要学到的分布
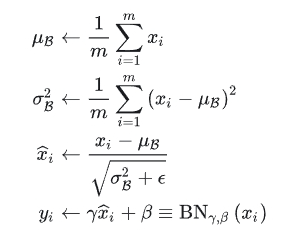
High Resolution Classifier(分类网络高分辨率预训练)
- 这里引入迁移学习(Transfer learning)的概念:把已训练好的模型(预训练模型)参数迁移到新的模型帮助新模型训练。
迁移学习有三种方式 Transfer Learning:冻结预训练模型的全部卷积层,只训练自己定制的全连接层。 Extract Feature Vector:先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。 Fine-tuning:冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层,因为这些层保留了大量底层信息)甚至不冻结任何网络层,训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
- Fine-tuning原理:利用已知网络结构和已知网络的参数,修改output层为我们自己的层,微调最后一层前的若干层的训练参数,这样就有效利用了深度神经网络强大的泛化能力,又免去了设计复杂的模型以及耗时良久的训练。
- YOLOv1在采用 224×224 分类模型预训练后将分辨率增加到 448×448 ,并使用这个高分辨率在检测数据集上finetune。但是直接切换分辨率,检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用448×448输入来finetune分类网络这一中间过程(10 epochs).YOLOv2将预训练分成两步:先用224×224的输入从头开始训练网络,大概160个epoch(表示将所有训练数据循环跑160次),然后再将输入调整到448×448,再训练10个epoch,这可以使得模型在检测数据集上finetune之前已经适应高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP提升了约4%。
Convolutional With Anchor Boxes(使用先验框)
YOLOv1每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率略微有所下降,总体mAP略有下降。
v2中移除了v1最后的两层全连接层,全连接层计算量大,耗时久。文中没有详细描述全连接层的替换方案,这里猜测是利用1*1的卷积层代替.
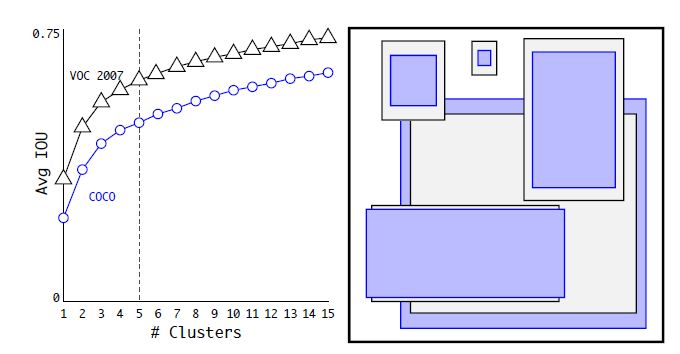
Dimension Clusters(Anchor Box的宽高由聚类产生)
这里算是作者的一个创新点。Faster R-CNN中的九个Anchor Box的宽高是事先设定好的比例大小,一共设定三个面积大小的矩形框,每个矩形框有三个宽高比:1:1,2:1,1:2,总共九个框。而在v2中,Anchor Box的宽高不经过人为获得,而是将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。例如使用5个Anchor Box,那么kmeans聚类的类别中心个数设置为5。加入了聚类操作之后,引入Anchor Box之后,mAP上升。
需要强调的是,聚类必须要定义聚类点(矩形框 (\(w\),ℎ))之间的距离函数,文中使用如下函数:
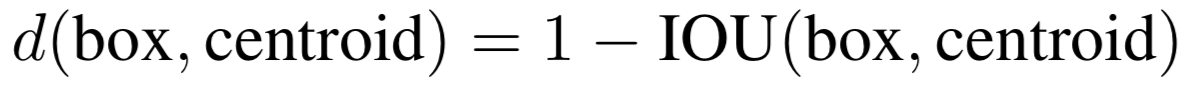
下图是在VOC和COCO数据集上的聚类分析结果,随着聚类中心数目的增加,平均IOU值(各个边界框与聚类中心的IOU的平均值)是增加的,但是综合考虑模型复杂度和召回率,作者最终选取5个聚类中心作为先验框,其相对于图片的大小如右边图所示。
Direct location prediction
引入anchor box的时候遇到的第二个问题:模型不稳定,尤其是在训练刚开始的时候。其位置预测公式为如下图所示: 其中 (x,y) 为边界框的实际中心位置,需要预测的坐标偏移值为 (\(t_x,t_y\)) ,先验框的尺寸为 (\(w_a,h_a\)) 以及中心坐标 (\(x_a,y_a\)) (特征图每个位置的中心点)。由于 (\(t_x,t_y\)) 取值没有任何约束,因此预测边框的中心可能出现在任何位置,训练早期不容易稳定。
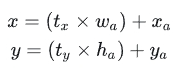
所以,YOLOv2弃用了这种预测方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。总结来看,根据边界框预测的4个offsets\(t_x,t_y,t_w,t_h\) ,可以按如下公式计算出边界框实际位置和大小:
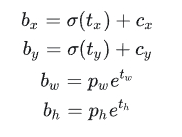
其中 (\(c_x, c_y\)) 为cell的左上角坐标,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为(1,1),由于sigmoid(\(\sigma(x)=\frac{1}{1 + e^{-x}}\))函数的处理,边界框的中心约束会在cell内部,防止偏移过多。 (\(p_w,p_h\)) 是先验框的宽度和长度,其值是相对于特征图大小的。在特征图中每个cell的长和宽均为1。这里记特征图的大小为 (W,H) ,(在文中是(13,13)),这样我们就可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间):
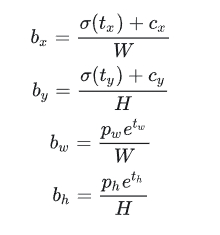
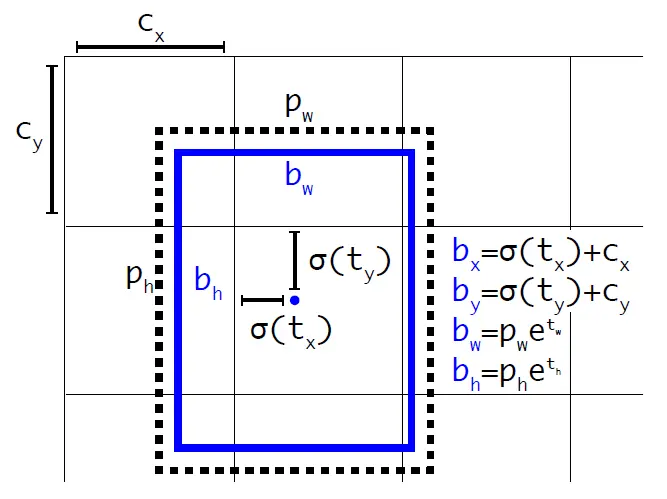
如果再将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。
Fine-Grained Features
YOLOv2的输入图片大小是416416,经过5次22 maxpooling之后得到13 * 13大小的特征图,并以此特征图采用卷积做预测。虽然13*13的feature map对于预测大的object以及足够了,但是对于预测小的object就不一定有效。这里主要是添加了一个层:passthrough layer。这个层的作用就是将前面一层的26*26的feature map和本层的13*13的feature map进行连接,有点像ResNet。
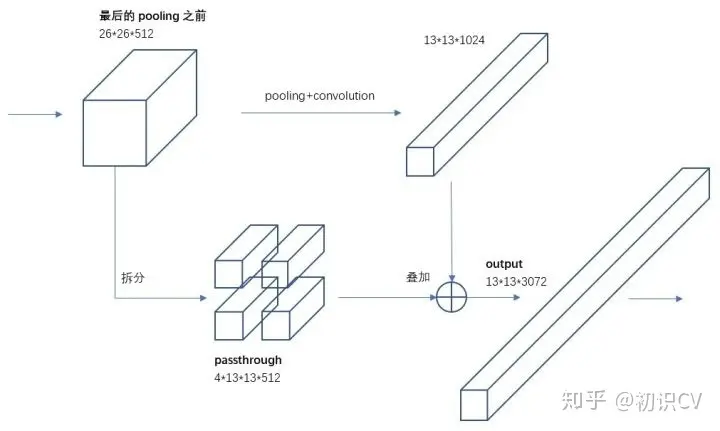
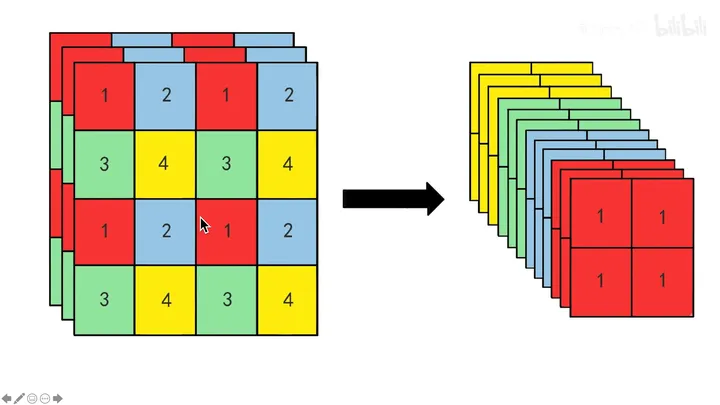
一拆四的方法如下:
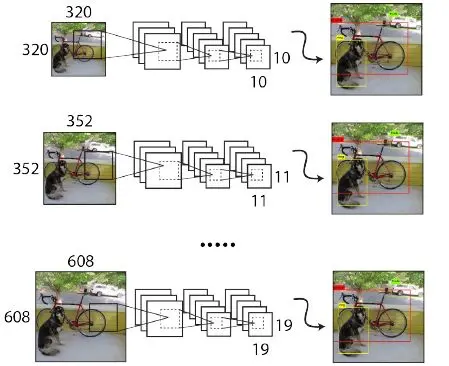
Multi-Scale Training(多尺度的图像训练)
为了让YOLOv2模型更加robust,作者引入了Muinti-Scale Training,简单讲就是在训练时输入图像的size是动态变化的,注意这一步是在检测数据集上fine tune时候采用的,不要跟前面在Imagenet数据集上的两步预训练分类模型混淆。
由于YOLOv2模型中只有卷积层和池化层,所以YOLOv2的输入可以不限于 416*416大小的图片。
具体来讲,在训练网络时,每训练10个batch(在一个epoch 中,batch数和迭代数是相等的,例如500个样本为1batch,总样本2000,则一个epoch包含4个batch或者说4个iteration),网络就会随机选择另一种size的输入,然后只需要修改对最后检测层的处理就可以重新训练。也就是说downsample的factor是32,因此采用32的倍数作为输入的size:{320,352,…,608}。
总结来看,虽然YOLOv2做了很多改进,但是大部分都是借鉴其它论文的一些技巧,如Faster R-CNN的anchor boxes,YOLOv2采用anchor boxes和卷积做预测,这基本上与SSD模型(单尺度特征图的SSD)非常类似了,而且SSD也是借鉴了Faster R-CNN的RPN网络。从某种意义上来说,YOLOv2和SSD这两个one-stage模型与RPN网络本质上无异,只不过RPN不做类别的预测,只是简单地区分物体与背景。在two-stage方法中,RPN起到的作用是给出region proposals,其实就是作出粗糙的检测,所以另外增加了一个stage,即采用R-CNN网络来进一步提升检测的准确度(包括给出类别预测)。而对于one-stage方法,它们想要一步到位,直接采用“RPN”网络作出精确的预测,要因此要在网络设计上做很多的tricks。YOLOv2的一大创新是采用Multi-Scale Training策略,这样同一个模型其实就可以适应多种大小的图片了。
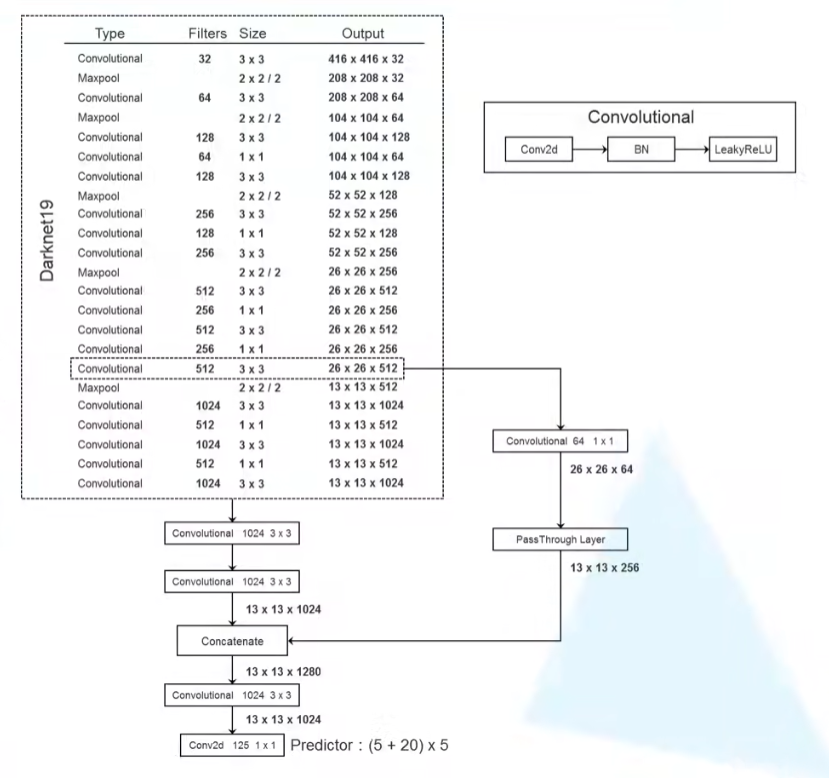
Faster:new Network:Darknet-19
在YOLO v1中,作者采用的训练网络是基于GooleNet,YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层.
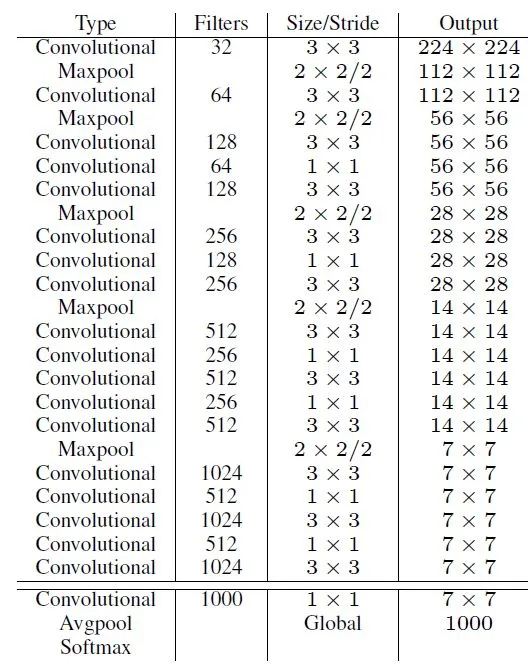
Darknet-19与VGG16模型设计原则是一致的,主要采用 3×3 卷积,采用 2×2 的maxpooling层,特征图维度降低2倍,同时特征图的channles增加两倍。与NIN类似,Darknet-19最终采用global avgpooling做预测,并且在 3×3 卷积之间使用 1×1 卷积来压缩特征图channles以降低模型计算量和参数。Darknet-19每个卷积层后面使用了batch norm层以加快收敛速度,降低模型过拟合。
整体网络结构:
YOLOv3
详细见YOLO v3网络结构分析_yolov3网络结构-CSDN博客.
网络结构:
YOLOv3 SPP
改进见YOLO-V3-SPP详细解析_yolov3-spp-CSDN博客.
YOLOv4
见YOLOv4网络详解_yolov4网络结构图-CSDN博客.
Fermi、Kepler架构
- Fermi架构:
- Fermi架构是NVIDIA的第一代统一架构,推出于2010年。
- 它引入了CUDA(Compute Unified Device Architecture)计算架构,使GPU不仅仅用于图形处理,还能进行通用计算。
- Fermi架构支持双精度浮点运算,这对于科学计算和一些专业应用来说是至关重要的。
- Fermi GPU的代表产品包括GTX 400和500系列。
- Kepler架构:
- Kepler架构是NVIDIA的第二代统一架构,推出于2012年。
- 它进一步提升了CUDA计算性能,并引入了一些新技术,如GPU Boost(动态超频)和NVENC(NVIDIA视频编码器)。
- Kepler架构在能效方面有所改进,使得GPU在相同功耗下能提供更高的性能。
- Kepler GPU的代表产品包括GTX 600和700系列。
SM
GPU实际上是一个SM的阵列,每个SM包含N个计算核,现在我们的常用GPU中这个数量一般为128或192。一个GPU设备中包含一个或多个SM,这是处理器具有可扩展性的关键因素。如果向设备中增加更多的SM,GPU就可以在同一时刻处理更多的任务,或者对于同一任务,如果有足够的并行性的话,GPU可以更快完成它。
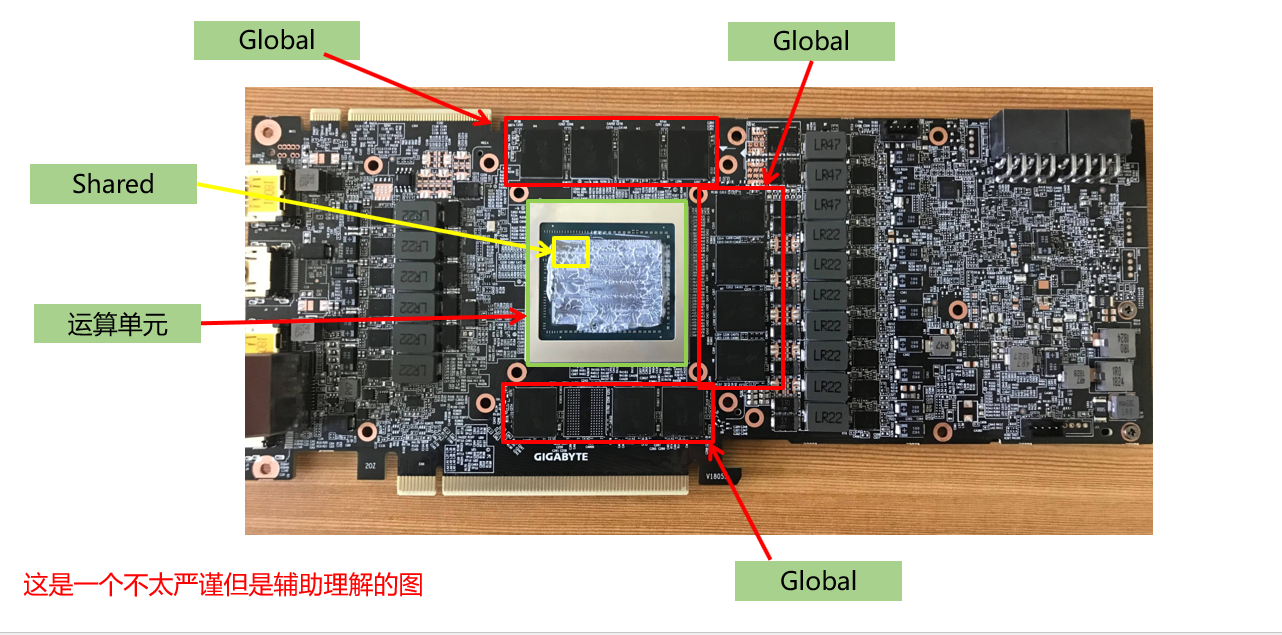
具体而言,以Fermi架构的GPU为例,其结构如下图。
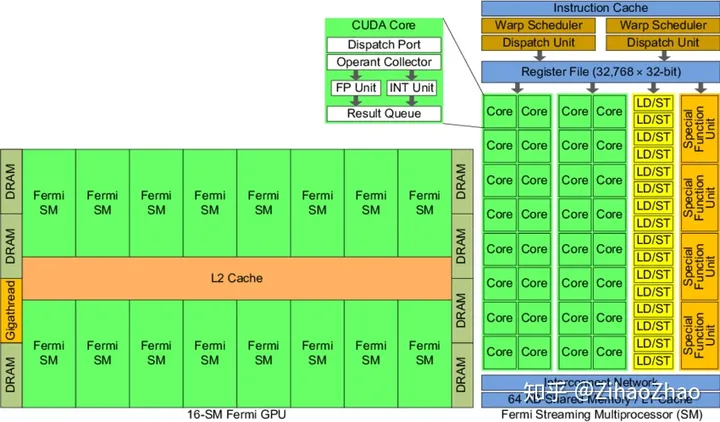
左边是GPU的整体结构,其主要是由大量的SM(Streaming-Multiprocessor)和DRAM存储等构成的。右图是对单个SM进行放大,可以看到SM由大量计算核(有时也称SP或CUDA核)、LDU(Load-Store Units)、SFU(Special-Function Units)、寄存器、共享内存等构成。这种结构正是GPU具有高并行度计算能力的基础。通过一定的层级结构组织大量计算核,并给各级都配有相应的内存系统,GPU获得了出色的计算能力。
其中流式多处理器(SM)是GPU架构的核心。GPU中的每一个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,所以在一个GPU上并发执行数千个线程是有可能的。当启动一个内核网络时,它的线程块会被分布在可用的SM上来执行。当线程块一旦被调度到一个SM上,其中的线程只会在那个指定的SM上并发执行。多个线程块可能会被分配到同一个SM上,而且是根据SM资源的可用性进行调度的。
再多提一嘴,稍微说说计算核以外的部分。线程束调度器(Warp Scheduler)顾名思义是进行线程束的调度,负责将软件线程分配到计算核上;LDU(Load-Store Units)负责将值加载到内存或从内存中加载值;SFU(Special-Function Units)用来处理sin、cos、求倒数、开平方特殊函数。
Heatmap
CenterNet将目标当成一个点来检测,即用目标box的中心点来表示这个目标。预测目标中心的偏移量(offset),宽高size来得到物体实际box,而heatmap则是表示分类信息。每个类别都有一张heatmap,每一张heatmap上,若某个坐标处有物体目标的中心点,即在该坐标处产生一个keypoint(用高斯圆表示),如下图所示:

Focal Loss
Focal Loss(焦点损失)是一种用于解决类别不平衡问题的损失函数,特别是在目标检测任务中常常被使用。它由Lin et al.在2017年的论文《Focal Loss for Dense Object Detection》中提出。
在目标检测任务中,由于背景类别的样本数量远远超过目标类别的样本数量,导致了类别不平衡问题。传统的交叉熵损失函数在面对这种不平衡时可能会导致模型过度关注于容易分类的背景样本,而忽视了目标样本的分类。
Focal Loss通过引入一个可调节的参数,有效地降低了容易分类的样本(例如背景样本)的权重,从而更加关注难以分类的样本。具体来说,焦点损失函数通过降低易分类样本的权重来减少易分类样本对总体损失的贡献,并且对于错误分类的样本给予了更大的权重,这样可以使模型更加关注于难以分类的样本,从而提高了模型对于少数类别目标的检测能力。
loss
训练的时候应该控制loss的初始值,最好在10以内,才可以控制训练不会飞。
Driver API的层次
CUDA Driver是与GPU沟通的驱动级别底层API
对DriverAPI的理解,有利于理解后续的RuntimeAPI
CUDA Driver随显卡驱动发布,与cudatoolkit分开看
CUDA Driver对应于cuda.h和libcuda.so文件
主要知识点是Context的管理机制,以及CUDA系列接口的开发习惯(错误检查方法),还有内存模型
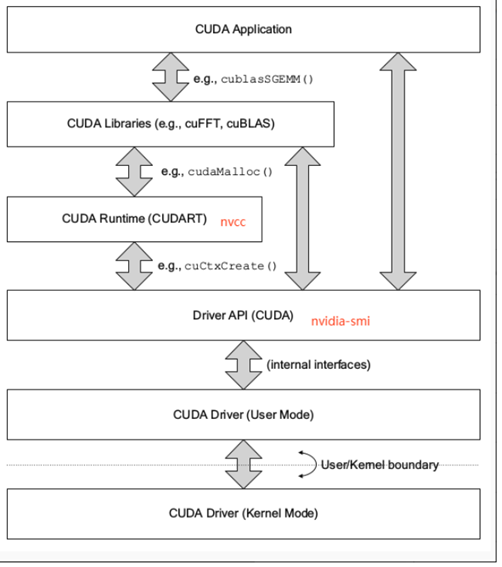
Context
有两种:
- 手动管理的context,cuCtxCreate(手动管理,以堆栈方式push/pop)
- 自动管理的context,cuDevicePrimaryCtxRetain(自动管理,runtime api以此为基础)
手动管理cuCtxCreate
context是一种上下文,关联对GPU的所有操作。context与一块显卡关联,一个显卡可以被多个context关联。每个线程都有一个栈结构储存context,栈顶是当前使用的context,对应有push、pop函数操作context的栈,所有api都以当前context为操作目标。
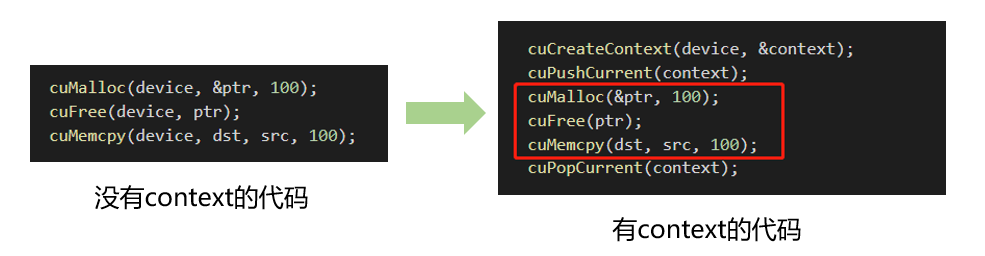
context只是为了方便控制device的一种手段而提出来的,栈的存在是为了方便控制多个设备。
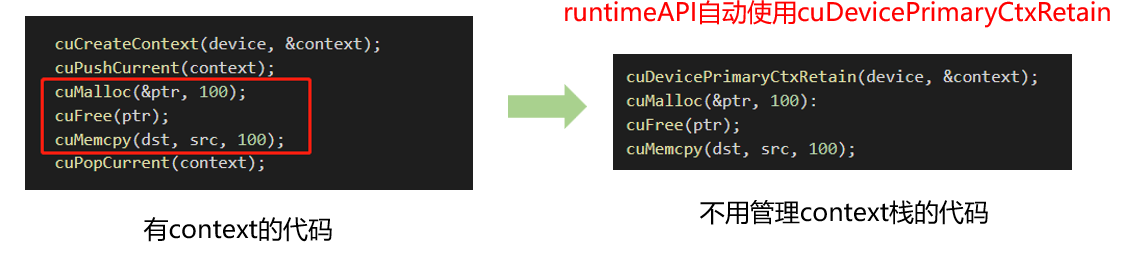
自动管理cuDevicePrimaryCtxRetain
由于高频操作,是一个线程基本固定访问一个显卡不变,且只使用一个context,很少会用到多context,这时候CreateContext、PushCurrent、PopCurrent这种多context管理就显得麻烦,还得再简单,因此推出了cuDevicePrimaryCtxRetain,为设备关联主context,分配、释放、设置、栈都不用你管。primaryContext:给我设备id,给你context并设置好,此时一个显卡对应一个primary context。不同线程,只要设备id一样,primary context就一样。context是线程安全的。
内存
有两大类:
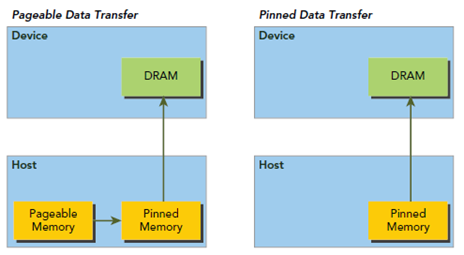
CPU内存,称之为Host Memory
- Pageable Memory:可分页内存
- Page-Locked Memory/pinned memory:页锁定内存
可以理解为Page lock memory是vip房间,锁定给你一个人用。而Pageable memory是普通房间,
在酒店房间不够的时候,选择性的把你的房间腾出来给其他人交换用,这就可以容纳更多人了。造成房
间很多的假象,代价是性能降低。
pageable memory没有锁定特性,对于第三方设备(比如GPU),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据(每次去房间找,说不准 你的房间被人交换了)。所以GPU可以直接访问pinned memory而不能访问pageable memory。
GPU内存,称之为Device Memory
- 全局内存(3):Global Memory
- 速度:普通
- 读写
- 显存大小(11GB etc.)
- 寄存器内存(1):Register Memory
- 速度:最快
- 读写
- 纹理内存(2):Texture Memory
- 速度:快
- 只读
- 共享内存(2):Shared Memory
- 速度快
- 读写
- 大小:2080Ti有48kb
- 常量内存(2):Constant Memory
- 速度:快
- 只读不能写
- 大小:一般64kb,16bit寻址
- 通常放一些不修改的东西,速度很快
- 本地内存(3):Local Memory,其实是全局内存,
- 速度普通
- 读写
- 大小:可用内存 / (SM数量 * SM最大常驻线程数),动态计算的,可用越少值越小
- C++中分配的栈空间变量就存在这里,local memory可以认为是栈空间,为什么说其实是全局内存,因为它和全局内存用的是同一块内存,在cuda核定义一个变量就是在这的
- 全局内存(3):Global Memory
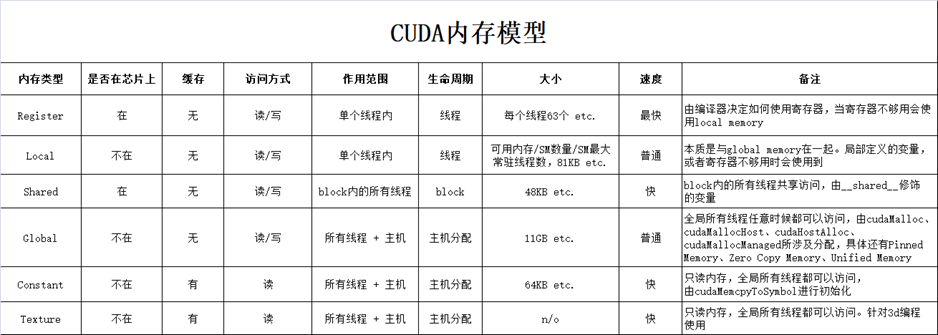
内存方面总结
- GPU可以直接访问pinned memory,称之为(DMA Direct Memory Access)
- 对于GPU访问而言,距离计算单元越近,效率越高,所以PinnedMemory<GlobalMemory<SharedMemory
- 代码中,由new、malloc分配的,是pageable memory,由cudaMallocHost分配的是PinnedMemory,由cudaMalloc分配的是GlobalMemory
- 尽量多用PinnedMemory储存host数据,或者显式处理Host到Device时,用PinnedMemory做缓存,都是提高性能的关键
各函数申请的内存类型
通过cudaMalloc分配GPU内存,分配到setDevice指定的当前设备上
通过cudaMallocHost分配page locked memory,即pinned memory,页锁定内存
- 页锁定内存是主机内存,CPU可以直接访问
- 页锁定内存也可以被GPU直接访问,使用DMA(Direct Memory Access)技术
- 注意这么做的性能会比较差,因为主机内存距离GPU太远,隔着PCIE等,不适合大量数据传输
- 页锁定内存是物理内存,过度使用会导致系统性能低下(导致虚拟内存等一系列技术变慢)
cudaMemcpy
如果host不是页锁定内存,则:
- Device To Host的过程,等价于
- pinned = cudaMallocHost
- copy Device to pinned
- copy pinned to Host
- free pinned
- Host To Device的过程,等价于
- pinned = cudaMallocHost
- copy Host to pinned
- copy pinned to Device
- free pinned
- Device To Host的过程,等价于
如果host是页锁定内存,则:
- Device To Host的过程,等价于
- copy Device to Host
- Host To Device的过程,等价于
- copy Host to Device
- Device To Host的过程,等价于
culnit 驱动初始化
- cuInit的意义是,初始化驱动API,如果不执行,则所有API都将返回错误,全局执行一次即可
- 没有对应的cuDestroy,不需要释放,程序销毁自动释放
cuda-runtime
stream-流
- 流是一种基于context之上的任务管道抽象,一个context可以创建n个流
- 流是异步控制的主要方式
- nullptr表示默认流,每个线程都有自己的默认流
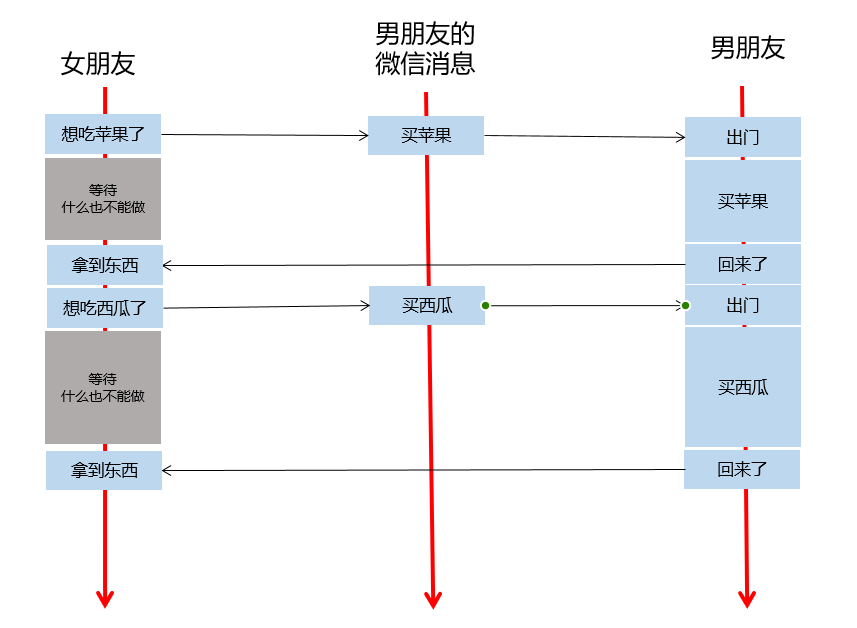
不用流:
用流:
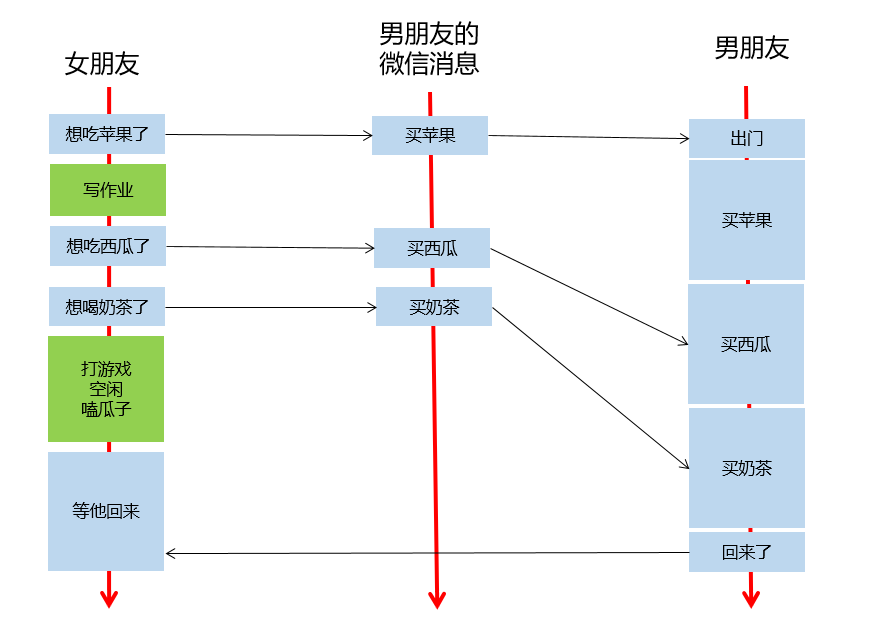
- 上面的例子中,男朋友的微信消息,就是任务队列,流的一种抽象
- 女朋友发出指令后,他可以做任何事情,无需等待指令执行完毕,(指令发出的耗时也是极短的)
- 即,异步操作,执行的代码,加入流的队列后,立即返回,不耽误时间
- 女朋友发的指令被送到流中排队,男朋友根据流的队列,顺序执行
- 女朋友选择性,在需要的时候等待所有的执行结果
- 新建一个流,就是新建一个男朋友,给他发指令就是给他发微信,你可以新建很多个男朋友
- 通过cudaEvent可以选择性等待任务队列中的部分任务是否就绪
注意事项
- 要十分注意,指令发出后,流队列中储存的是指令参数,不能加入队列后立即释放参数指针,这会导致流队列执行该指令时指针失效而出错
- 应当在十分肯定流已经不需要这个指针后,才进行修改或者释放,否则会有非预期结果出现
- 举个粒子:你给钱让男朋友买西瓜,他刚到店拿好西瓜,你把转的钱撤回去了。此时你无法预知他是否会跟店家闹起来矛盾,还是屁颠的回去。如果想得到预期结果,必须得让卖西瓜结束再处理钱的事情
核函数
核函数是cuda编程的关键,通过xxx.cu创建一个cudac程序文件,并把cu交给nvcc编译,才能识别cuda语法
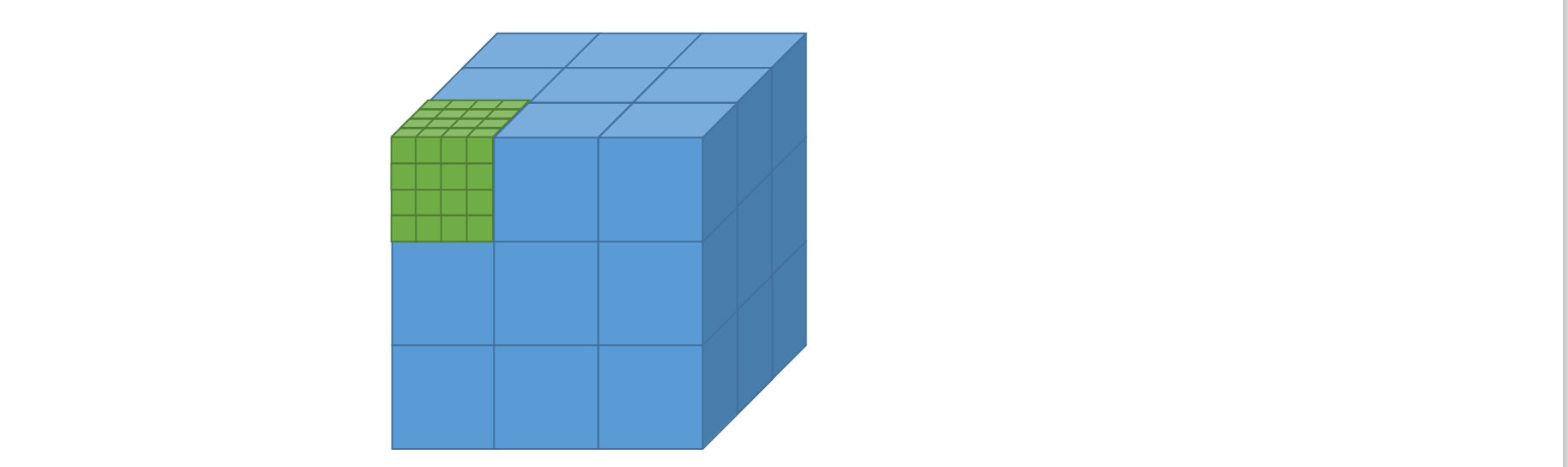
- 线程(Thread):一般通过GPU的一个核进行处理;
- 线程块(Block):由多个线程组成;各block是并行执行的,block间无法通信,也没有执行顺序。
- 线程格(Grid):由多个线程块组成。
- 核函数(Kernel):在GPU上执行的函数通常称为核函数;一般通过标识符__global__修饰,调用通过<<<参数1,参数2>>>,用于说明内核函数中的线程数量,以及线程是如何组织的。
- host调用核函数:function<<<gridDim, blockDim, sharedMemorySize, stream>>>(args…);
画个图直观理解一下,下图是1个线程格,里面包含了27块线程块(蓝色的格子),每个线程块里面又包含了64个线程(绿色的格子)。线程是最小的单位了,虽然这边我画的还是立方体,但通常是看做一个点。
threadIdx、blockIdx、blockDim和gridDim
gridDim、blockDim为维度,启动核函数后是固定的
gridDim.x、gridDim.y、gridDim.z分别表示线程格各个维度的大小,所以有
1 | |
blockDim.x、blockDim.y、blockDim.z分别表示线程块中各个维度的大小,所以有
1 | |
blockIdx、threadIdx为索引,启动核函数后,枚举每一个维度值,不同线程取值不同
blockIdx.x、blockIdx.y、blockIdx.z分别表示当前线程块所处的线程格的坐标位置,threadIdx.x、threadIdx.y、threadIdx.z分别表示当前线程所处的线程块的坐标位置。
线程格里面总的线程个数N即可通过下面的公式算出:
1 | |
还有一点要注意:blocksize的最大值是1024,即blockDim.x * blockDim.y * blockDim.z的最大值是1024.
dim和index之间也是有关系的
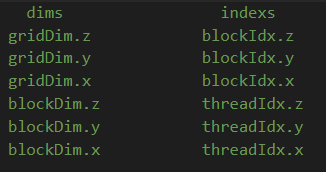
如果gridDim.x为n, 那么对应blockIdx.x的取值范围就是[0, n - 1],其他dim和idx的对应关系也是同理。
线程索引的计算
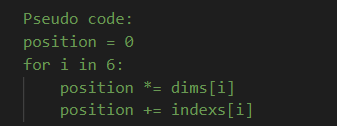
上面说了线程个数由下面的公式计算:
1 | |
那么如何计算每个线程对应的索引?对于这样的dim和index
口诀:左乘右加
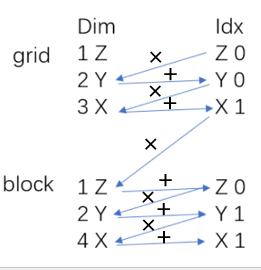
伪代码如下:
<<<>>>参数
通常的参数是这样的,function<<<gridDim, blockDim, sharedMemorySize, stream>>>(args…);
<<<>>>至少有两个参数,因为gridDim和blockDim是必须的,而后边两个参数是可选的。gridDim和blockDim都是一个三维的向量,有三个维度x,y,z,如果在传参的时候没有传递三维向量会怎么样?
比如传递一个数值,那么会将其解释为x维度,而y和z维度被默认为1。同理,如果传递一个二维向量(1, 2),那么会将其解释为x和y维度,其中x为1,y为2,而z维度被默认为1。
最后一个参数steam传递nullptr则表示使用默认流。
注意事项
- 调用核函数是传值的,不能传引用,可以传递类、结构体等,核函数可以是模板
- __global__表示为核函数,由host调用。__device__表示为设备函数,由device调用
- __host__表示为主机函数,由host调用。__shared__表示变量为共享变量
- host调用核函数:function<<<gridDim, blockDim, sharedMemorySize, stream>>>(args…);
- 只有__global__修饰的函数才可以用<<<>>>的方式调用
- 调用核函数是传值的,不能传引用,可以传递类、结构体等,核函数可以是模板
- 核函数的执行,是异步的,也就是立即返回的
- 核函数内访问线程索引主要用到threadIdx、blockIdx、blockDim、gridDim这些内置变量
cudaGetDeviceProperties函数
cudaGetDeviceProperties得到的prop有很多属性,常见的有:
totalGlobalMem: 全局内存的总大小sharedMemPerBlock: 每个block的共享内存大小regsPerBlock: 每个block的寄存器数量warpSize: warp的大小memPitch: 内存中允许的最大间距字节数maxThreadsPerBlock: 每个block的最大线程数maxThreadsDim[3]: 块中每个维度的最大线程数maxGridSize[3]: 网格中每个维度的块数量totalConstMem: 可用的常量内存量
shared_memory共享内存
共享内存是片上内存,更靠近计算单元,因此比globalMem速度更快,通常可以充当缓存使用
定义方法:
1 | |
动态共享内存需要使用extern来声明,同时静态共享变量的地址会随着定义的变量个数而随之叠加,而动态共享变量无论定义多少个,地址都一样。
1 | |
可以看到以下输出:
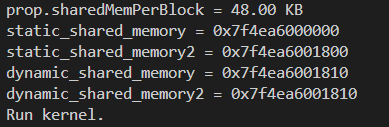
可以看到,定义的两个静态共享变量的地址是不一样的,而两个动态共享变量的地址是一样的。
指定共享内存大小
如上面代码所示:
1 | |
另外,如果配置的各类共享内存总和大于sharedMemPerBlock,则核函数执行出错,Invalid argument
- 不同类型的静态共享变量定义,其内存划分并不一定是连续的
- 中间会有内存对齐策略,使得第一个和第二个变量之间可能存在空隙
- 因此你的变量之间如果存在空隙,可能小于全部大小的共享内存就会报错
tensorRT基础
- TensorRT的核心在于对模型算子的优化(合并算子、利用GPU特性选择特定核函数等多种策略),通过tensorRT,能够在Nvidia系列GPU上获得最好的性能
- 因此tensorRT的模型,需要在目标GPU上实际运行的方式选择最优算法和配置
- 也因此tensorRT生成的模型只能在特定条件下运行(编译的trt版本、cuda版本、编译时的GPU型号)
- 主要知识点,是模型结构定义方式、编译过程配置、推理过程实现、插件实现、onnx理解
- 模型结构定义方式:我现在有一个模型我怎么去告诉tensorRT(权重是多少?)
- onnx是一个中间的结构,比如pytorch可以导出到onnx
tensorRT优化原理
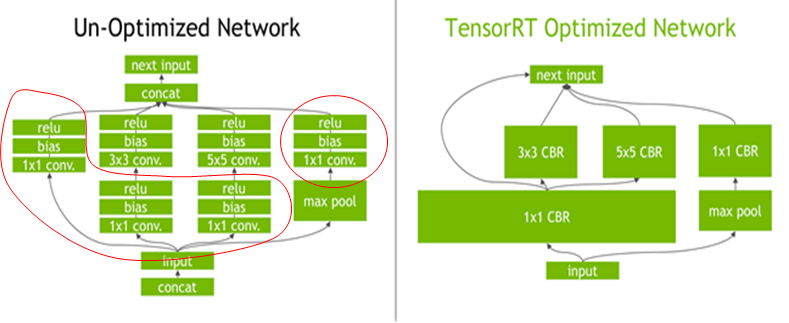 左侧是没有经过优化的网络,那么在tensorRT执行的时候发现有很多操作(左侧圆圈中的操作)可以简化。
左侧是没有经过优化的网络,那么在tensorRT执行的时候发现有很多操作(左侧圆圈中的操作)可以简化。
tensorRT提供了C++和python接口,可以通过这些接口定义模型结构(如权重参数)
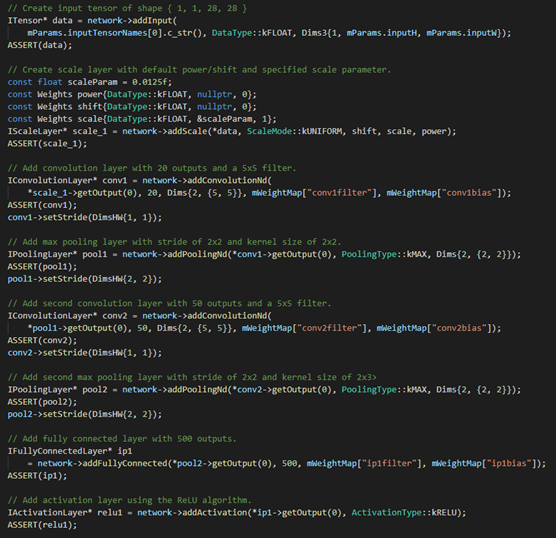
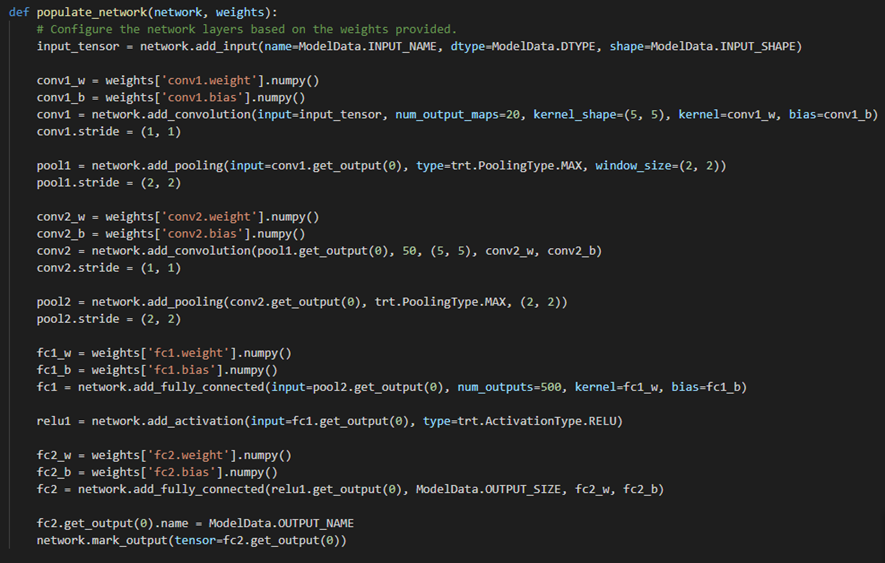
但是如果每次都这样那么需要修改的时候就很麻烦,而且不方便调试,因此就提出了几种高级的方式:
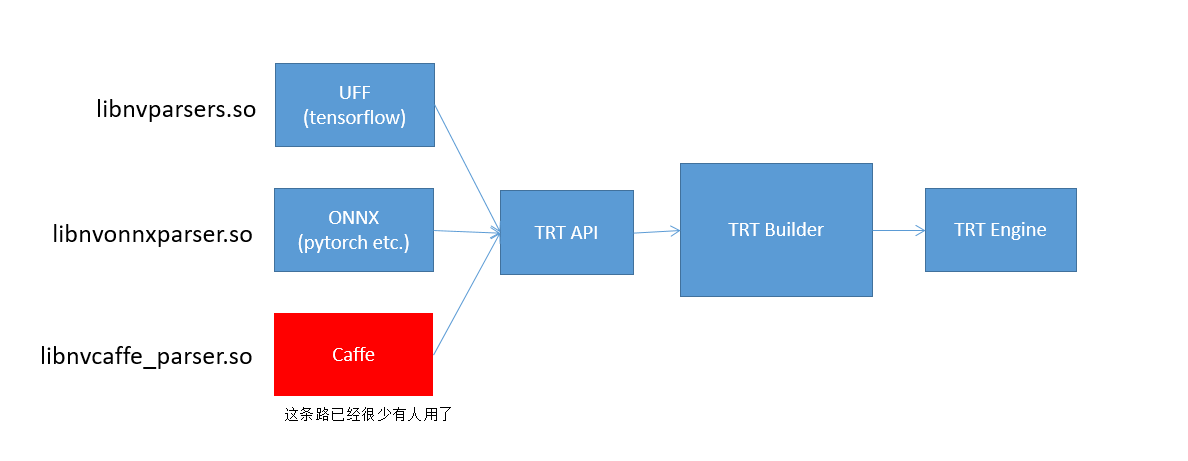
- UFF:tensorflow可以直接转出为UFF格式,UUF格式里边存储了该有的网络结构以及权重,tensorRT通过libnvparsers.so可以解析UFF格式,然后去调用刚才提到的C++接口去创建网络结构并设置权重,然后交给builder编译,最后得到engine
- ONNX:同样,pytorch可以转出为onnx格式,onnx格式存储了网络结构、数据流转以及权重参数,tensorRT通过libonnxparsers.so可以解析onnx模型,然后创建每个layer,设置权重参数,然后进一步编译得到engine
- caffe:同样如此,但是这条路用的人已经很少了。
常见方案
基于tensorRT的发布,又有人在之上做了工作https://github.com/wang-xinyu/tensorrtx。
tensorRT的api没有实现常见的模型,那么就需要每次自己去设置,所以有人在基础之上为每个模型写硬代码,并已写好了大量的常见模型代码。

