面试问题
面试问题
C++
C++编译生成可执行文件的顺序
- 预处理:在编译之前,源代码会经过预处理器的处理。预处理器执行诸如宏替换、包含头文件等操作。预处理器生成一个经过预处理的源代码文件。
- 编译:预处理后的源代码会被编译器编译成汇编代码(Assembly code),汇编代码是与特定架构相关的低级代码。
- 汇编:汇编器将汇编代码转换为机器代码(Object code),这是由二进制表示的机器可执行代码。
- 链接:在链接阶段,编译器将所有的对象文件和库文件链接在一起,生成最终的可执行文件。这个过程包括解析符号引用、符号重定位和符号表的生成等操作。
- 生成可执行文件:最终,链接器生成可执行文件,该文件包含了所有必要的机器代码和元数据,可以在相应的操作系统上运行。
C语言,指针需要注意的地方(腾讯云)
- 要避免使用未初始化的指针
- 指针赋值时一定要保证类型匹配,由于指针类型确定指针所指向对象的类型,因此初始化或赋值时必须保证类型匹配,这样才能在指针上执行相应的操作。
- void *
类型的指针,其实这种形式只是记录了一个地址罢了,如上所说,由于不知道所指向的数据类型是什么所以不能进行相应的操作。其实void
* 指针仅仅支持几种有限的操作:
- 与另外的指针进行比较,因为void *类型里面就是存的一个地址,所以这点很好理解;
- 向函数传递void 指针或从函数返回void 指针,举个例子吧,我们平时常用的库函数qsort中的比较函数cmp(个人习惯于用这个名字)中传递的两个参数就是const void *类型的,用过的应该很熟了;
- 给另一个void * 类型的指针赋值。还是强调一下不能使用void * 指针操纵它所指向的对象。
- 在为一个指针再次分配内存之前要保证它原先没有指向其他内存,防止出现内存泄漏。
编译链接过程了解过吗(腾讯云)
多态怎样实现的(腾讯云)
字符串中变量的地址相差多少(腾讯云)
静态存储区的变量什么时候销毁(腾讯云)
类中同名对象地址相同吗(腾讯云)
类中不同类型对象地址相差多少(腾讯云)
listen、socket、accpet函数参数
C++ vector size/capacity 的区别,如何缩容?
- size():返回向量中当前存储的元素数量,即实际使用的元素个数。
- capacity():返回向量当前分配的内存空间大小,即向量的容量。容量可以大于或等于实际存储的元素数量。
如果需要手动缩减向量的容量,可以使用shrink_to_fit()方法。这个方法会释放多余的内存,使得向量的容量等于实际存储的元素数量。
.cpp -> 可执行文件的过程,追问:链接阶段的详细过程
- 预处理阶段:
- 预处理器会处理源文件,包括执行宏替换、包含头文件、去除注释等操作,生成预处理后的源文件。
- 编译阶段:
- 编译器会将预处理后的源文件编译成目标文件(object file),包括词法分析、语法分析、语义分析、优化等步骤。每个源文件对应一个目标文件。
- 汇编阶段:
- 汇编器将编译生成的目标文件转换成机器码,生成可重定位的机器代码文件。
- 链接阶段:
- 链接器将多个目标文件和库文件链接成可执行文件,包括以下步骤:
- 符号解析(Symbol Resolution):链接器会将目标文件中的符号与其定义关联起来,包括函数和全局变量的定义与引用。
- 地址重定位(Address Binding):链接器会将目标文件中的符号地址与实际内存地址关联起来,生成可执行文件中的地址映射表。
- 符号合并(Symbol Merging):如果多个目标文件中存在相同的符号,则链接器会将这些符号合并为一个,以避免重复定义。
- 链接器将多个目标文件和库文件链接成可执行文件,包括以下步骤:
- 生成可执行文件:
- 链接器根据符号解析、地址重定位和符号合并生成可执行文件,其中包含了所有的目标文件和库文件,并且解析了所有的符号引用。
有哪些键值型的存储结构
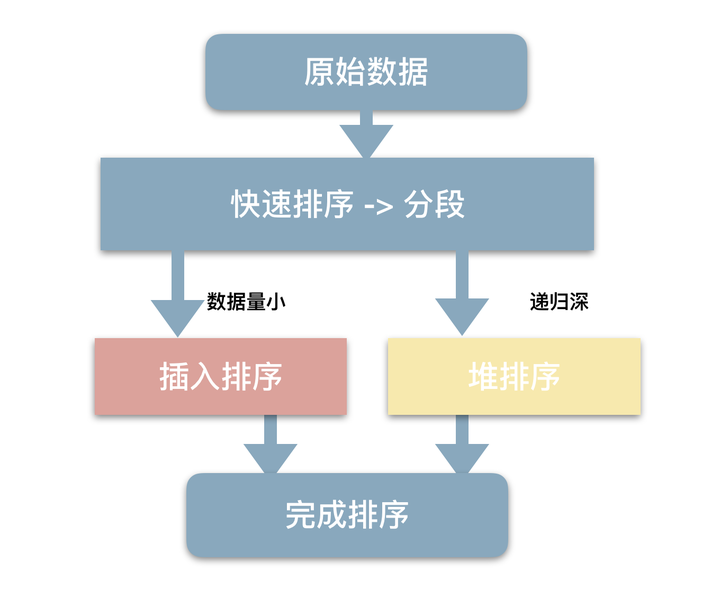
STL 的sort是怎么实现的?
STL的sort算法,数据量大时采用QuickSort快排算法,分段归并排序。一旦分段后的数据量小于某个门槛(16),为避免QuickSort快排的递归调用带来过大的额外负荷,就改用Insertion Sort插入排序。如果递归层次过深,还会改用HeapSort堆排序。
数据库存储为什么⽤ B+ 树,不⽤ AVL 树。
思路和不用B树一样,B+树方便遍历,方便范围查找,而且AVL树数据量大的时候可能会频繁旋转调整平衡。
int* 和const不同位置代表什么意思
- 当
const位于指针类型前面时,如const int* ptr,表示指针指向的数据是常量,不能通过指针修改所指向的数据,但指针本身可以修改,即指针是可变的,但指向的数据是不可变的。 - 当
const位于指针类型后面时,如int* const ptr,表示指针本身是常量,不能修改指针指向的内存地址,但指针所指向的数据可以修改。
为什么栈的速度比堆快
栈是操作系统提供的数据结构,计算机底层对他提供了一系列的支持:分配专门的寄存器存储寄存器地址,压栈和出栈都有相应的指令; 而堆是C/C++库函数提供的,机制复杂,需要一些分配内存,合并内存,释放内存的算法,所以效率低。
detach和join有什么区别
detach()方法将一个线程从原始线程中分离出来,使其独立运行;而join()方法用于等待一个线程执行完毕后再继续执行原始线程。
C++有哪些锁
线程之间的锁有: 互斥锁、条件锁、自旋锁、读写锁、递归锁。一般而言,锁的功能与性能成反比。
互斥锁(Mutex)
互斥锁用于控制多个线程对他们之间共享资源互斥访问的一个信号量。也就是说是为了避免多个线程在某一时刻同时操作一个共享资源。
mutex
对于 std::mutex
对象,任意时刻最多允许一个线程对其进行上锁
- mtx.lock():调用该函数的线程尝试加锁。如果上锁不成功,即:其它线程已经上锁且未释放,则当前线程
block。如果上锁成功,则执行后面的操作,操作完成后要调用mtx.unlock()释放锁,否则会导致死锁的产生 - mtx.unlock():释放锁,
std::mutex还有一个操作:mtx.try_lock(),字面意思就是:“尝试上锁”,与mtx.lock()的不同点在于:如果上锁不成功,当前线程不阻塞。
lock_guard
虽然 std::mutex
可以对多线程编程中的共享变量提供保护,但是直接使用
std::mutex 的情况并不多。因为仅使用 std::mutex
有时候会发生死锁。
考虑这样一个情况:假设线程1上锁成功,线程2上锁等待。但是线程1上锁成功后,抛出异常并退出,没有来得及释放锁,导致线程2“永久的等待下去”,此时就发生了死锁。
std::lock_guard
只有构造函数和析构函数。简单的来说:当调用构造函数时,会自动调用传入的对象的lock()函数,而当调用析构函数时,自动调用
unlock() 函数(这就是所谓的RAII)。
lock_guard 还有一个构造函数
lock_guard( mutex_type& m, std::adopt_lock_t t );
其中第二个参数类型为:std::adopt_lock_t。这个构造函数假定:当前线程已经上锁成功,所以不再调用lock()函数。
示例代码:
1 | |
条件锁
当需要死循环判断某个条件成立与否时【true or
false】,我们往往需要开一个线程死循环来判断,这样非常消耗CPU。使用条件变量,可以让当前线程
wait,释放CPU,如果条件改变时,我们再notify退出线程,再次进行判断。
条件锁就是所谓的条件变量,某一个线程因为某个条件未满足时可以使用条件变量使该程序处于阻塞状态。一旦条件满足以“信号量”的方式唤醒一个因为该条件而被阻塞的线程(常和互斥锁配合使用),唤醒后,需要检查变量,避免虚假唤醒。
最为常见就是在线程池中,起初没有任务时任务队列为空,此时线程池中的线程因为“任务队列为空”这个条件处于阻塞状态。一旦有任务进来,就会以信号量的方式唤醒一个线程来处理这个任务。
c++用法:
任意要等待 std::condition_variable 的线程必须获取
std::unique_lock<std::mutex>,这个 mutex
正是用来保护共享变量(即“条件”)的。执行 wait ,
wait_for 或者
wait_until。这些等待动作原子性地释放
mutex,并使得线程的执行暂停。
当前线程调用 wait()
后将被阻塞(此时当前线程应该获得了锁(mutex),不妨设获得锁
lck),直到另外某个线程调用 notify_* 唤醒了当前线程。
在线程被阻塞时,该函数会自动调用 lck.unlock()
释放锁,使得其他被阻塞在锁竞争上的线程得以继续执行。另外,一旦当前线程获得通知(notified,通常是另外某个线程调用
notify_* 唤醒了当前线程),wait() 函数也是自动调用
lck.lock(),使得 lck 的状态和 wait 函数被调用时相同。
1 | |
自旋锁
假设我们有一个两个处理器core1和core2计算机,现在在这台计算机上运行的程序中有两个线程:T1和T2分别在处理器core1和core2上运行,两个线程之间共享着一个资源。
首先我们说明互斥锁的工作原理,互斥锁是是一种
sleep-waiting
的锁。假设线程T1获取互斥锁并且正在core1上运行时,此时线程T2也想要获取互斥锁(pthread_mutex_lock),但是由于T1正在使用互斥锁使得T2被阻塞。当T2处于阻塞状态时,T2被放入到等待队列中去,处理器core2会去处理其他任务而不必一直等待(忙等)。也就是说处理器不会因为线程阻塞而空闲着,它去处理其他事务去了。
而自旋锁就不同了,自旋锁是一种 busy-waiting
的锁。也就是说,如果T1正在使用自旋锁,而T2也去申请这个自旋锁,此时T2肯定得不到这个自旋锁。与互斥锁相反的是,此时运行T2的处理器core2会一直不断地循环检查锁是否可用(自旋锁请求),直到获取到这个自旋锁为止。
从“自旋锁”的名字也可以看出来,如果一个线程想要获取一个被使用的自旋锁,那么它会一致占用CPU请求这个自旋锁使得CPU不能去做其他的事情,直到获取这个锁为止,这就是“自旋”的含义。
当发生阻塞时,互斥锁可以让CPU去处理其他的任务;而自旋锁让CPU一直不断循环请求获取这个锁。 通过两个含义的对比可以我们知道“自旋锁”是比较耗费CPU的。
示例代码:
1 | |
atomic 是C标准程序库中的一个头文件,定义了 C11
标准中的一些表示线程、并发控制时原子操作的类与方法等。此头文件主要声明了两大类原子对象:std::atomic和std::atomic_flag。
atomic_flag类是一种简单的原子布尔类型,只支持两种操作:
test_and_set(flag=true)和clear(flag=false)。std::atomic类模板std::atomic既不可复制亦不可移动。atomic对int、char、bool等数据结构进行了原子性封装,在多线程环境中,对std::atomic对象的访问不会造成竞争-冒险。利用std::atomic可实现数据结构的无锁设计。
所谓的原子操作,取的就是“原子是最小的、不可分割的最小个体”的意义,它表示在多个线程访问同一个全局资源的时候,能够确保所有其他的线程都不在同一时间内访问相同的资源。也就是他确保了在同一时刻只有唯一的线程对这个资源进行访问。这有点类似互斥对象对共享资源的访问的保护,但是原子操作更加接近底层,因而效率更高。使用原子操作能大大的提高程序的运行效率。
读写锁
先看互斥锁,它只有两个状态,要么是加锁状态,要么是不加锁状态。假如现在一个线程
a 只是想读一个共享变量
i,因为不确定是否会有线程去写它,所以我们还是要对它进行加锁。但是这时又有一个线程b试图去读共享变量
i,发现被锁定了,那么b不得不等到a释放了锁后才能获得锁并读取
i
的值,但是两个读取操作即使是同时发生的,也并不会像写操作那样造成竞争,因为它们不修改变量的值。所以我们期望在多个线程试图读取共享变量的时候,它们可以立刻获取因为读而加的锁,而不是需要等待前一个线程释放。
读写锁可以解决上面的问题。它提供了比互斥锁更好的并行性。因为以读模式加锁后,当有多个线程试图再以读模式加锁时,并不会造成这些线程阻塞在等待锁的释放上。
读写锁是多线程同步的另外一个机制。在一些程序中存在读操作和写操作问题,对某些资源的访问会存在两种可能情况,一种情况是访问必须是排他的,就是独占的意思,这种操作称作写操作,另外一种情况是访问方式是可以共享的,就是可以有多个线程同时去访问某个资源,这种操作称为读操作。这个问题模型是从对文件的读写操作中引申出来的。把对资源的访问细分为读和写两种操作模式,这样可以大大增加并发效率。读写锁比互斥锁适用性更高,并行性也更高。
需要注意的是,这里只是说并行效率比互斥高,并不是速度一定比互斥锁快,读写锁更复杂,系统开销更大。并发性好对于用户体验非常重要,假设互斥锁需要0.5秒,使用读写锁需要0.8秒,在类似学生管理系统的软件中,可能90%的操作都是查询操作。如果突然有20个查询请求,使用的是互斥锁,则最后的查询请求被满足需要10秒,估计没人能接受。使用读写锁时,因为读锁能多次获得,所以20个请求中,每个请求都能在1秒左右被满足,用户体验好的多。
特点:
- 如果一个线程用读锁锁定了临界区,那么其他线程也可以用读锁来进入临界区,这样可以有多个线程并行操作。这个时候如果再用写锁加锁就会发生阻塞。写锁请求阻塞后,后面继续有读锁来请求时,这些后来的读锁都将会被阻塞。这样避免读锁长期占有资源,防止写锁饥饿。
- 如果一个线程用写锁锁住了临界区,那么其他线程无论是读锁还是写锁都会发生阻塞。
c++用法:
STL本身并没有提供读写锁(Read-Write
Lock)的实现。Boost中的boost::shared_mutex和unique_lock提供了读写锁的实现,可以用于实现多读单写的并发控制。
简单的说:
shared_lock是read_lock。被锁后仍允许其他线程执行同样被shared_lock的代码。这是一般做读操作时的需要。unique_lock是write_lock。被锁后不允许其他线程执行被shared_lock或unique_lock的代码。在写操作时,一般用这个,可以同时限制unique_lock的写和share_lock的读。
注:C++ 11
中提供了unique_lock且功能和用法与boost::unique_lock一直,但是C++
11并没有提供shared_lock。
递归锁
std::recursive_mutex 与 std::mutex
一样,也是一种可以被上锁的对象,但是和 std::mutex
不同的是,std::recursive_mutex
允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,std::recursive_mutex
释放互斥量时需要调用与该锁层次深度相同次数的
unlock(),可理解为 lock() 次数和
unlock()
次数相同,除此之外,std::recursive_mutex 的特性和
std::mutex 大致相同。
例如函数 a 需要获取锁 mutex,函数
b 也需要获取锁 mutex,同时函数 a
中还会调用函数 b。如果使用std::mutex
必然会造成死锁。但是使用 std::recursive_mutex
就可以解决这个问题。
了解哪些C++ 11 的新特性
- 自动类型推断(auto):可以使用
auto关键字来声明变量,让编译器根据初始化表达式的类型推断变量的类型。 - 范围-based for
循环:使用
for循环可以遍历容器中的元素,语法更简洁直观。 - nullptr:引入了空指针常量
nullptr,用于表示空指针。 - Lambda 表达式:可以使用Lambda表达式来创建匿名函数,使得在函数式编程风格中更方便地使用。
- 移动语义和右值引用:引入了右值引用和移动语义,可以通过移动而不是复制来提高程序的性能。
- 智能指针:引入了
std::unique_ptr和std::shared_ptr等智能指针,用于管理动态分配的内存,避免内存泄漏和悬空指针问题。 - 初始化列表:引入了初始化列表语法,可以通过
{}来初始化数组、容器、结构体等。
weakPtr如何获得sharedPtr
weak_ptr对象不能直接被用于获取指向的对象,因为其不拥有所指向对象的所有权。但是可以通过weak_ptr对象的lock()成员函数获得一个指向所指对象的shared_ptr对象,前提是该对象还存在,如果对象不存在,lock()返回空.
右值引用的用途
移动语义(Move Semantics): 右值引用使得移动语义成为可能。传统的复制操作会对资源进行深拷贝,而移动语义则允许将资源从一个对象“移动”到另一个对象,而不是进行昂贵的深拷贝操作。这在动态内存管理、容器类的元素操作以及返回临时对象等场景下都有很大的性能提升。
完美转发(Perfect Forwarding): 右值引用可以在函数模板中实现完美转发,即保持原始参数类型的引用类型。这使得函数模板可以将参数完全转发给其他函数,而不会对参数类型造成额外的包装或变化,保持了原始参数的准确性。
函数重载底层原理
首先C语言不支持函数重载,程序在预编译阶段会经历预处理、编译、汇编和链接生成可执行程序的过程,在汇编过程中编译器会收集全局符号并生成全局符号表(将符号和其相应地址一一对应的表格称为符号表)。C语言不支持函数重载的原因是符号表中的出现了两个具有有效地址的函数名,所以发生了冲突。
C++对写入符号表的函数具有一个修正的过程,Linux下的命名规则做如下总结:
**_Z + 函数名长度 + 函数名 + 类型首字母的小写**
C++ 编译器都做了哪些优化?
- 常量折叠(constant folding)。编译器将编译期能计算为常量的表达式直接替换为计算结果。
- 常量传播(constant propagation)。编译器追踪到一个值的源头,发现它是常量后,会将所有地方出现的这个值替换为常量。
- 公共子表达式消除(common subexpression elimination)。将重复的计算过程重写掉,只算一次,其它地方复制结果。
- 移除死代码(dead code removal)。用许多其它方法优化后,可能有些代码对输出不产生影响,就可以移除这些代码。这里包含了对没用到的值的读写操作,以及完全没用到的整个函数或表达式。
- 指令选择(instruction selection)。这个不算是通常意义的优化,但既然编译器会将程序转换为它的内部表示形式,并生成CPU指令,编译器通常有一个庞大的等效指令序列的集合可供选择。编译需要知道目标处理器架构的细节以作出正确选择。
- 移动循环中的不变代码(loop invariant code movement)。编译器能识别一块代码在循环过程中值不变,并将这块代码移出循环。其于此,编译器还能将循环中不变的条件检查移出循环外,再将循环体复制两次:一次针对条件为真,一次针对条件为假。之后还能做进一步优化。
- 窥孔优化(peephole optimization)。编译器取一小段指令序列并做局部优化。
- 尾调用移除(tail call removal)。一个在结尾处调用自身的递归函数通常可被重写为循环,从而降低函数调用开销,并减小栈溢出的可能。
大端小端
大端模式与小端模式
- 大端模式是指数据的低位保存在内存的高地址中,而数据的高位保存在内存的低地址中.
- 小端模式是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
例如:
一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122。那么0x11为数据高字节,0x22为数据低字节。
- 对于大端模式,就将0x11放在内存低地址中,即0x0010中;0x22放在内存高地址中,即0x0011中。
- 小端模式,就将0x11放在内存高地址中,即0x0011中;0x22放在内存低地址中,即0x0010中。
怎么判断大端小端?
1 | |
如何让哈希表按插入的顺序有序
设置一个哈希表和一个双向链表
1 | |
取值可以使用umap[key]->val做到O(1),同时l中也按照插入顺序有序。
make_shared与直接创建shared_ptr的区别
make_shared 只需要分配一次内存,而直接创建 shared_ptr 需要分配两次内存。
make_shared也存在缺陷,只有当 _Weaks 为 0 时,控制块才会调用 _Delete_this() 释放自己,weak_ptr会拖延整块内存释放时间。
dynamic_cast把父类指针转为void*会怎么样
在C++中,dynamic_cast
用于在运行时进行安全的类型转换,通常用于将基类指针或引用转换为派生类指针或引用。如果将父类指针转换为
void*,会丢失类型信息,因此无法在后续代码中准确地确定其类型。具体表现如下:
1 | |
在上述示例中,dynamic_cast 无法将 void*
转换回指针类型,因为在将 Base* 转换为 void*
时,类型信息已经丢失。因此,将父类指针转换为 void*
后,再转换回去是不可行的。通常情况下,不建议将指针转换为
void*,除非有特殊的需求。如果你需要从void*转换回具体的类类型指针,应该使用static_cast或reinterpret_cast,但这需要你确保转换的安全性。
什么样的数据类型需要关注大小端字节序?
只有超过一个字节的基本数据类型才需要考虑字节序
free释放内存的时候是怎么知道释放内存的大小的?
glibc:空间的大小记录在参数指针指向地址的前面,free的时候通过这个记录即可知道要释放的内存有多大。
utf-8知道吗?了解utf-8与gbk有什么不一样吗?
- ASCII:ASCII 只有127个字符,表示英文字母的大小写、数字和一些符号,但由于其他语言用ASCII 编码表示字节不够,例如:常用中文需要两个字节,且不能和ASCII冲突,中国定制了GB2312编码格式,相同的,其他国家的语言也有属于自己的编码格式。
- Unicode:由于每个国家的语言都有属于自己的编码格式,在多语言编辑文本中会出现乱码,这样Unicode应运而生,Unicode就是将这些语言统一到一套编码格式中,通常两个字节表示一个字符,而ASCII是一个字节表示一个字符,这样如果你编译的文本是全英文的,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
- UTF-8:为了解决上述问题,又出现了把Unicode编码转化为“可变长编码”UTF-8编码,UTF-8编码将Unicode字符按数字大小编码为1-6个字节,英文字母被编码成一个字节,常用汉字被编码成三个字节,如果你编译的文本是纯英文的,那么用UTF-8就会非常节省空间,并且ASCII码也是UTF-8的一部分。
- UTF-8是一种Unicode字符集的变长字符编码方式,支持包括英文、拉丁文、中文、日文、韩文等在内的几乎所有字符。
- GBK是一种针对汉字的字符编码方式,它是在GB2312字符集的基础上扩展而来,支持汉字和一些常用的符号、数字等。
static局部变量与普通局部变量区别?
- static局部变量只被初始化一次,自从第一次被初始化直到程序运行结束都一直存在。普通局部变量,只在函数执行期间存在,函数的一次调用执行结束后,变量被撤销,其所占用的内存也被收回。
- 静态局部变量在静态存储区分配空间,局部变量在栈里分配空间。
socket写过吗?tcp三次握手发生在哪个函数?
- 客户端调用connect()函数,此时客户端会向服务端发送SYN
- 服务端收到SYN后,会从listen()函数返回SYN+ACK
- 客户端收到connect()函数的返回,之后向服务端发送最后一个ACK
- 服务端收到最后一个ACK以后,将该连接请求从未完成连接队列放入已完成连接队列中,等待accept()从该队列中取出
半连接队列和全连接队列
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
- 半连接队列,也称 SYN 队列;
- 全连接队列,也称 accept 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
内存对齐的好处/坏处
C++浮点数存储方式
float:大小为4字节,即32位
- 最高位 31 位 ,保存符号位 S,“0”表示正数 ,“1”表示负数
- 第30 位~23 位 ,共 8 位 ,保存指数部分(指数值加上偏移量127) ,称为阶码
- 第22 位~0 位 ,共 23 位 ,保存系数部分 (整数位的1不保存),称为尾数
double:大小为8字节,即64位
- 最高位 63 位 ,保存符号位 S,“0”表示正数 ,“1”表示负数
- 第 62 位~52 位 ,共 11 位 ,保存指数部分(指数值加上偏移量1023) ,称为阶码
- 第 51 位~0 位 ,共 52 位 ,保存系数部分 (整数位的1不保存),称为尾数
动态链接库和静态链接库的区别?都是有多份拷贝吗?
静态链接库用来和所有的目标文件一起组织成可执行文件,生成的可执行文件可以独立运行。存在诸多缺点:
- 首先,可执行文件内部拷贝了所有目标文件和静态链接库的指令和数据,文件本身的体积会很大。当系统中存在多个链接同一个静态库的可执行文件时,每个可执行文件中都存有一份静态库的指令和数据,就会造成内存空间的极大浪费。
- 此外,一旦程序中有模块更新,整个程序就必须重新链接后才能运行。假设一个程序有 20 个模块构成,每个模块的大小为 1 MB,那么每次更新任何一个模块,用户就必须重新获取 20 MB 的程序,对用户很不友好。
动态链接,指的是将链接的时机推迟到程序运行时再进行。具体来讲,对于一个以动态链接方式运行的项目,:
- 首先由静态链接器将所有的目标文件组织成一个可执行文件
- 运行时将所需的动态链接库全部载入内存,由动态链接器完成可执行文件和动态库文件的链接工作。
和静态链接库相比,动态链接库可以很好地解决空间浪费和更新困难的问题。
- 动态链接库和可执行文件是分别载入内存的,因此动态链接库的体积通常会小一些。当有多个程序使用同一个动态链接库时,所有程序可以共享一份动态链接库的指令和数据,避免了空间的浪费。
- 采用动态链接的方式也可以方便程序的更新和升级,当程序的某个模块更新后,只需要将旧的模块替换掉,程序运行时会自动将所有模板载入内存并动态地链接在一起。
动态绑定和静态绑定
说起静态绑定和动态绑定,我们⾸先要知道静态类型和动态类型,静态类型就是它在程序中被声明时所采用的类型,在编译期间确定。动态类型则是指“目前所指对象的实际类型”,在运行期间确定。
静态绑定,⼜名早绑定,绑定的是静态类型,所对应的函数或属性依赖于对象的静态类型,发生在编译期间。
动态绑定,⼜名晚绑定,绑定的是动态类型,所对应的函数或属性依赖于动态类型,发生在运行期间。
⽐如说,virtual 函数是动态绑定的,⾮虚函数是静态绑定的,缺省参数值也是静态绑定的。这⾥呢,就需要注意,我们不应该重新定义继承而来的缺省参数,因为即使我们重定义了,也不会起到效果。因为一个基类的指针指向一个派生类对象,在派生类的对象中针对虚函数的参数缺省值进行了重定义, 但是缺省参数值是静态绑定的,静态绑定绑定的是静态类型相关的内容,所以会出现一种派生类的虚函数实现方式结合了基类的缺省参数值的调用效果,这个与所期望的效果不同。
虚函数的额外开销
- 空间开销 首先,由于需要为每一个包含虚函数的类生成一个虚函数表,所以程序的二进制文件大小会相应的增大;其次,对于包含虚函数的类的实例来说,每个实例都包含一个虚函数表指针用于指向对应的虚函数表,所以每个实例的空间占用都增加一个指针大小(32位系统4字节,64位系统8字节)。这些空间开销可能会造成缓存的不友好,在一定程度上影响程序性能。
- 时间开销 虚函数的时间开销主要是增加了一次内存寻址,通过虚函数表指针找到虚函数表,虽对程序性能有一些影响,但是影响并不大。
上述虚函数表面上的开销其实是微不足道的,真正影响虚函数性能的是隐藏在背后的,关键点在于分支预测器,对于直接调用而言,是不存在分支跳转的,因为跳转地址是编译器确定的,CPU直接去跳转地址取后面的指令即可,不存在分支预测,这样可以保证CPU流水线不被打断。而对于间接寻址,由于跳转地址不确定,所以此处会有多个分支可能,这个时候需要分支预测器进行预测,如果分支预测失败,则会导致流水线冲刷,重新进行取指、译码等操作,对程序性能有很大的影响。
如何避免虚函数额外开销
使用模板泛型编程,但是这样会导致代码膨胀.
New operator和operator new的区别
operator new
operate new 是一个分配原始内存的函数——至少在概念上,它与 malloc() 没有太大区别。例如:
1 | |
它的函数原型为:
1 | |
当然,重载operator new(全局或类),还需要/需要重载匹配的operator delete。
new operator
new operate通常用于创建对象:
1 | |
总结
两者的区别在于 operator new 只分配原始内存,没有别的。new operator首先使用 operator new 分配内存,然后它调用正确类型的对象的构造函数,因此结果是在该内存中创建的真实活动对象。如果该对象包含任何其他对象(嵌入的或作为基类),则这些构造函数也会被调用。
new operator:它先调用operator new分配内存,然后调用构造函数初始化那段内存。
operator new:可以重载,用于实现不同的内存分配行为。
C++的exception机制底层原理
主要是在栈框架中添加了一些东西:
- piPrev 成员指向链表的上一个节点,它主要用于在函数调用栈中逐级向上寻找匹配的 catch 块,并完成栈回退工作。
- piHandler 成员指向完成异常捕获和栈回退所必须的数据结构(主要是两张记载着关键数据的表:“try”块表:tblTryBlocks 及“栈回退表”:tblUnwind)。
- nStep 成员用来定位 try 块,以及在栈回退表中寻找正确的入口。
C++有哪些可重入锁
std::recursive_mutex,同一个线程可以多次对std::recursive_mutex进行加锁。
智能指针是线程安全的吗
总结:不是
情况一:多线程代码操作的是同一个shared_ptr的对象,这时候不是线程安全的;
情况二:多线程代码操作的不是同一个shared_ptr的对象,这时候是线程安全的.但是这只是说对shared_ptr对象来说是线程安全的,但是这并不意味着shared_ptr所管理的对象是线程安全的.
C与C++指针的区别
C++和C语言对空指针的定义不同,c++11引入了nullptr
什么情况下需要重载new
比如内存泄露检测,重载operator new就可以记录下内存申请的具体位置。
shared_ptr怎么实现引用计数
hared_ptr通过一个引用计数机制来管理对象的生命周期。每个shared_ptr都包含两个指针:一个指向对象,另一个指向控制块(control
block)。控制块包含两个计数器:一个用于shared_ptr实例(_M_use_count),另一个用于weak_ptr实例(_M_weak_count)。
unique_ptr怎么实现独占
把拷贝构造函数和赋值操作符都声明为delete或private,这样每一个智能指针要指向一个对象时只能是指向一个新实例化的对象而不能通过“=”或者拷贝去指向前面已经创建了的对象。
vector.push_back时间复杂度
平均O(1),但是在某些情况下是O(n),因为可能插入的时候涉及到vector扩容。
static可以修饰虚函数吗
虚函数是用于实现多态性的关键概念,在继承体系中,派生类可以重写(覆盖)基类中的虚函数,从而实现特定的行为。当你声明一个函数为虚函数时,编译器将会创建一个虚函数表(vtable),用于存储各个虚函数的地址,以便在运行时进行动态分派。
而 static
关键字会使成员变量或成员函数与类的实例独立,与类本身关联。因此,将
static
关键字用于虚函数是没有意义的,因为虚函数的调用是动态的,而
static 成员函数在编译时就确定了调用的目标。
所以不能。
weak_ptr指向的对象可能不存在,怎么处理这种情况
为了安全地使用weak_ptr指向的对象,你应该先将它转换为shared_ptr,这样可以确保在使用对象时对象是存在的。你可以使用weak_ptr的lock()方法来实现这一点。如果weak_ptr指向的对象已经不存在了,lock()会返回一个空的shared_ptr。
C++四种类型转换
static_cast
没有运行时类型检查来保证转换的安全性,进行上行转换(把派生类指针或引用转为基类表示)是安全的;进行下行转换(把基类的指针或引用转换为派生类表示),由于没有动态类型检查,所以是不安全的。
dynamic_cast
在进行下行转换的时候具有类型检查(信息在虚函数中)的功能,比static_cast安全。
dynamic_cast本身只能用于存在虚函数的父子关系的强制类型转换;对于指针,转换失败则返回nullptr;对于引用,转换失败会抛出异常。
reinterpret_cast
可以将整形转换为指针,也可以把指针转为数组;可以在指针和引用里进行肆无忌惮的转换,平台一致性比较差。
const_cast
常量指针转换为非常量指针,并且仍然指向原来的对象。常量引用转换为非常量引用,并且仍然指向原来的对象。去掉类型的const或volatile属性。
哪些场景会遇到悬空指针?
- 在函数中返回指向局部变量的指针。
1 | |
要避免这种情况,可以使用动态内存分配。
在函数中定义局部容器变量,然后返回容器中元素的指针
1
2
3
4
5int* func()
{
vetcor<int> vec = {1, 2, 3, 4, 5, 6};
return &vec[2]; // 函数返回后vec会被销毁,所以返回的指针会成为选空指针
}
C++的union
1 | |
unoin的多个变量共用一块内存,如果是多个变量的话,union的大小就是站内存最大的那个。
虚函数表是在什么时候建立的?
虚函数表是在编译的过程中创建。 对于虚函数指针来说,由于虚函数指针是基于对象的,所以对象在实例化的时候,虚函数指针就会创建,所以是在运行时创建。
C++ 什么情况下会出现堆栈溢出的情况?
- 递归调用过深
- 局部变量空间所需大小超过栈的大小
栈溢出问题怎么解决
- 使用迭代算法
- 适用动态内存分配
C++ 栈空间大小是多少?
Linux下默认是1MB,注意把C++栈空间大小和Linux线程栈大小区分开,Linux线程栈大小默认是8MB.
怎么获取虚函数表指针
- 同一个类的对象虚表的地址是一样的
- 对象地址的前八个字节(64位下,32位是4字节)存放虚表地址
1 | |
静态多态和动态多态
多态其实一般就是指继承加虚函数实现的多态,对于重载来说,实际上基于的原理是,编译器为函数生成符号表时的不同规则,重载只是一种语⾔特性,与多态无关,与面向对象也无关,但这⼜是 C++中增加的新规则,所以也算属于 C++,所以如果⾮要说重载算是多态的一种,那就可以说:多态可以分为静态多态和动态多态。
静态多态其实就是重载,因为静态多态是指在编译时期就决定了调用哪个函数,根据参数列表来决定;
动态多态是指通过子类重写父类的虚函数来实现的,因为是在运行期间决定调用的函数,所以称为动态多态,一般情况下我们不区分这两个时所说的多态就是指动态多态。动态多态的实现与虚函数表,虚函数指针相关。
扩展:子类是否要重写父类的虚函数?子类继承父类时,父类的纯虚函数必须重写,否则子类也是一个虚类不可实例化。 定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函数。
C++类成员变量的初始化顺序
- 成员变量在使用初始化列表初始化时,与构造函数中初始化成员列表的顺序无关,只与定义成员变量的顺序有关。
- 如果不使用初始化列表初始化,在构造函数内初始化时,此时与成员变量在构造函数中的位置有关。
- 类中 const 成员常量必须在构造函数初始化列表中初始化。
- 类中 static 成员变量,只能在类外初始化(同一类的所有实例共享静态成员变量)。
存在派生类时的初始化顺序
- 基类的静态变量或全局变量
- 派生类的静态变量或全局变量
- 基类的成员变量
- 派生类的成员变量
Go
go内存管理
- 自动垃圾回收
- 概述:Go 语言采用了自动垃圾回收(Garbage Collection,GC)机制。这意味着内存的分配和释放是自动进行的,开发者不需要手动管理内存。
- 垃圾回收算法:Go 使用标记-清除(Mark-and-Sweep)算法的变种,即三色标记法。该算法将对象分为三种颜色(白、灰、黑),并通过遍历根节点开始标记所有可达对象,最后清除不可达的白色对象。
- GC 的优化:自 Go 1.5 版本以来,Go 的垃圾回收器有了显著的改进,特别是在减少 STW(Stop-The-World)时间方面。Go 的垃圾回收器现在采用并发的方式运行,以尽量减少对程序性能的影响。
- 内存分配
- 栈内存和堆内存:
- 栈内存:用于存储函数调用的局部变量,栈的分配和释放速度非常快,因为它是按照 LIFO(后进先出)原则进行管理的。
- 堆内存:用于动态分配的对象,通常生命周期较长且在函数返回后依然有效的对象会分配到堆上。
- 逃逸分析:Go 编译器在编译时会进行逃逸分析,以决定变量是分配在栈上还是堆上。如果变量在函数外被引用,它会“逃逸”到堆上。通过优化代码以减少逃逸,可以降低堆内存的使用,从而减少 GC 压力。
- 内存管理的优化工具
- sync.Pool:Go 提供了
sync.Pool作为对象的临时缓存池,适用于需要频繁创建和销毁的短生命周期对象。使用sync.Pool可以减少内存分配和垃圾回收的开销。 - 内存剖析工具:Go 提供了
pprof和memstat等工具,用于分析程序的内存使用情况和性能瓶颈。这些工具可以帮助开发者识别出内存泄漏和高频分配等问题。
- 内存泄漏和管理的最佳实践
- 避免内存泄漏:虽然 Go 有垃圾回收,但不当的编程习惯(如全局变量持有引用、未关闭的 Goroutine)仍然可能导致内存泄漏。因此,开发者应当保持良好的编码习惯,如及时释放资源和避免不必要的全局状态。
- 代码优化:通过减少内存分配、复用对象和优化数据结构,可以进一步提高程序的性能并降低内存占用。
- 垃圾回收的挑战
- STW(Stop-The-World)问题:虽然 Go 在不断优化 GC 的 STW 时间,但在高并发场景下,仍然可能出现因 GC 而导致的短暂性能下降。理解并调优 GC 的触发频率、分配速率等参数对于优化高性能 Go 程序非常重要。
三色标记法
Go 语言中的垃圾回收器使用的是三色标记清除法(Tri-color Mark and Sweep),这是标记-清除垃圾回收算法的一种改进。三色标记法将对象分为三种颜色:白色、灰色和黑色。
在这个算法中,根节点(Root Set)是垃圾回收的起点,它决定了哪些对象是活跃的(即在使用中的),这些对象是垃圾回收过程中首先被标记的对象。
根节点包括:
- 全局变量:任何在全局作用域中声明的变量。
- 当前活跃的栈帧中的局部变量:函数调用中当前活跃的栈帧中存储的局部变量。
- CPU 寄存器中的变量:当前正在被使用的变量,如果它们在寄存器中保存状态,它们也被视为根节点的一部分。
- 内存中的其他显式的根节点:包括一些内部的、由 Go 运行时管理的结构。
三色标记的过程:
- 初始阶段:所有对象最初都是白色的,表示未被访问。垃圾回收器从根节点开始,将根节点中的所有对象标记为灰色,表示这些对象是可达的并且需要进一步检查。
- 扫描阶段:垃圾回收器扫描灰色对象,将它们的直接引用(子对象)标记为灰色,并将已经扫描过的对象标记为黑色,表示它们已经完全处理过了,且不会再被扫描。
- 清除阶段:当没有灰色对象时,表示所有可达的对象都已经标记为黑色,而白色对象即为不可达对象。这些白色对象就是垃圾,将被回收。
更加细分的过程
三色标记法在垃圾回收过程中主要分为以下几个阶段,每个阶段都针对特定的内存管理任务:
- 初始标记阶段(Initial Marking)
- 目标:标记根集合(Root Set),即程序中直接可达的对象。根集合包括全局变量、当前活跃的栈帧中的局部变量,以及 CPU 寄存器中的变量等。
- 操作:所有根集合中的对象被标记为灰色,表示这些对象是可达的,并需要进一步扫描其引用的对象。
- STW:由于需要确保所有根集合都已标记,这个阶段会暂停程序的执行(Stop-The-World,STW)。
- 并发标记阶段(Concurrent Marking)
- 目标:遍历所有灰色对象,并标记它们引用的其他对象。
- 操作:在这个阶段,垃圾回收器会并发地与应用程序一起运行。每当找到一个灰色对象时,它会被扫描,所有它引用的对象会被标记为灰色,然后该对象本身被标记为黑色,表示它已经完全处理过了。
- 并发:此阶段是并发进行的,尽量减少对应用程序运行的影响。
- 重新标记阶段(Re-marking)
- 目标:处理并发标记过程中可能出现的新引用,以确保标记阶段的完整性。
- 操作:由于在并发标记期间,应用程序仍然在运行,可能会产生新的引用关系,这些需要被重新标记。此阶段会再次暂停应用程序,确保所有的灰色对象都被正确处理并标记为黑色。
- STW:这一阶段也会短暂暂停程序执行,以完成对所有未处理引用的标记。
- 并发清除阶段(Concurrent Sweeping)
- 目标:清除未被标记为黑色的对象,即那些在标记阶段未被访问到的白色对象。
- 操作:垃圾回收器在这个阶段将并发清除所有的白色对象,回收它们占用的内存空间。
- 并发:此阶段同样是并发进行的,不会对程序的正常运行产生较大影响。
- 清除完成(Sweep Termination)
- 目标:确认所有可回收的内存已经被释放,垃圾回收的整个过程即告完成。
- 操作:在这一阶段,垃圾回收器做最后的收尾工作,确保所有白色对象的内存都已经被释放。
- STW:此阶段通常是快速完成的,不会显著影响程序的执行。
- 后台清理(Background Sweeping)
- 目标:进一步优化垃圾回收性能,回收并发清理阶段未能及时处理的内存。
- 操作:在垃圾回收器完成主要工作后,它会在后台继续处理剩余的未清理对象。这个阶段完全在后台运行,不会对程序的执行造成影响。
Golang的GC
GoV1.3- 普通标记清除法,整体过程需要启动STW,效率极低。
GoV1.5- 三色标记法, 堆空间启动写屏障,栈空间不启动,全部扫描之后,需要重新扫描一次栈(需要STW),效率普通
强三色不变式:不存在黑色对象引用到白色对象的指针。
弱三色不变式:所有被黑色对象引用的白色对象都处于灰色保护状态.
插入屏障:
具体操作: 在A对象引用B对象的时候,B对象被标记为灰色。(将B挂在A下游,B必须被标记为灰色)
满足: 强三色不变式. (不存在黑色对象引用白色对象的情况了, 因为白色会强制变成灰色)
删除屏障:
具体操作: 被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。
满足: 弱三色不变式. (保护灰色对象到白色对象的路径不会断)
- GoV1.8-三色标记法,混合写屏障机制, 栈空间不启动,堆空间启动。整个过程几乎不需要STW,效率较高。
混合写屏障规则:
具体操作:
1、GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW),
2、GC期间,任何在栈上创建的新对象,均为黑色。
3、被删除的对象标记为灰色。
4、被添加的对象标记为灰色。
满足: 变形的弱三色不变式.
有缓冲通道和无缓冲通道的区别
1. 无缓冲通道(Unbuffered Channel)
无缓冲通道的发送和接收操作是同步的,即发送者和接收者必须同时准备好,消息才能传递。
- 发送:发送者会阻塞,直到有接收者准备好接收数据。
- 接收:接收者会阻塞,直到有发送者发送数据。
示例:
1 | |
在无缓冲通道中,发送和接收是严格的同步行为,这确保了消息的传递是实时的。
2. 缓冲通道(Buffered Channel)
缓冲通道允许指定一个缓冲区大小,发送者在缓冲区未满的情况下可以发送数据而不阻塞。只有当缓冲区满时,发送者才会阻塞。而接收者在缓冲区为空时会阻塞,等待数据被发送。
- 发送:发送者只有在缓冲区满时才会阻塞,缓冲区未满时可以直接写入数据。
- 接收:接收者会阻塞,直到缓冲区有数据可读。
示例:
1 | |
在缓冲通道中,发送和接收之间的时机不必严格同步,因为通道可以存储一定数量的消息。
总结:
- 无缓冲通道:严格同步,发送和接收必须同时进行,适用于需要确保发送和接收一一对应的场景。
- 缓冲通道:异步,允许一定数量的消息存储,适用于发送方和接收方速率不匹配的场景。
channel什么情况下会出现panic
- 关闭为nil的channel
- 关闭一个已经关闭的通道
- 向一个已经关闭的通道写数据
- 从 nil channel 接收数据
Gin框架里的中间件是什么意思?
在Gin框架中,中间件是一种处理请求和响应的函数,可以在请求被处理之前或之后执行某些操作。中间件通常用于实现日志记录、认证、错误处理、跨域资源共享(CORS)、请求限流等功能。
具体来说,中间件的工作流程如下:
- 请求进入:当请求到达服务器时,中间件会在请求处理之前执行。
- 调用下一个处理函数:中间件可以选择在处理完自己的逻辑后,调用下一个处理函数(通常是路由的处理函数)。
- 响应返回:在请求处理完成后,中间件可以在响应发送之前执行一些操作,例如记录响应日志。
在Gin中,可以通过Use方法来注册中间件,示例如下:
1 | |
go里的Context是什么?
在Go语言中,Context是一个用于传递请求范围的值、取消信号以及截止时间的类型。它主要用于在处理多个goroutine时管理生命周期和状态,尤其是在网络请求和并发操作中非常有用。
Context的主要功能包括:
- 取消信号:允许发出信号以取消正在进行的操作。例如,当一个请求被取消时,相关的处理可以及时停止。
- 超时和截止时间:可以设置一个截止时间,当达到这个时间后,相关的操作应当停止。这在处理长时间运行的请求时特别有用。
- 传递值:可以在不同的处理函数或goroutine之间传递请求范围的数据。例如,可以传递用户身份信息或请求ID。
Context通常有几个常用的方法:
Value(key):获取与给定键相关联的值。Done():返回一个通道,当上下文被取消或超时时,会向该通道发送信号。Err():返回一个错误,指示上下文是否被取消或超时。
1 | |
go互斥锁正常模式和饥饿模式有什么区别 ?
在Go语言的sync.Mutex中,有两种模式:正常模式和饥饿模式。
正常模式:在正常模式下,等待队列中的goroutine不会直接从持有锁的goroutine中接过锁,而是将锁放回到队列中,所有等待的goroutine都有机会获取到锁。这种方式是公平的,但会导致频繁的goroutine切换,进而导致性能开销。
饥饿模式:在饥饿模式下,锁会直接从持有锁的goroutine传递给等待队列中的下一个goroutine。如果有goroutine等待了超过1ms并且还没能获取锁,那么锁就会进入饥饿模式。在饥饿模式下,新来的goroutine即使看到锁是解锁的,也不会去尝试获取锁,而是放在等待队列的尾部。
这两种模式在Go的sync.Mutex中是自动切换的。当锁处于饥饿模式,且有goroutine等待了超过1ms,或者等待队列中没有goroutine时,锁会切换回正常模式。
简单来说,正常模式更公平但可能引发性能问题,而饥饿模式可能导致某些goroutine等待时间过长,但可以避免频繁的goroutine切换,从而提高性能。
Go函数中发生内存泄露的原因?
在Go语言中,内存泄露通常是由于一些引用被错误地保留在内存中,使得垃圾回收器无法正确地回收它们。以下是一些可能导致内存泄露的常见原因:
- 长生命周期的对象持有短生命周期对象的引用:如果一个长生命周期的对象(例如全局变量或长生命周期的Goroutine)持有短生命周期对象的引用,那么即使短生命周期对象不再需要,它也无法被垃圾回收,因为还被长生命周期对象引用。
- Goroutine泄露:如果一个Goroutine在完成其工作后没有正确地退出,可能会导致内存泄露。例如,如果一个Goroutine在无限循环中,或者被阻塞并且没有机会退出。
- 未释放的Channel:如果一个Channel没有被正确关闭,并且没有任何Goroutine再从它接收数据,那么在这个Channel上的所有数据都不能被回收,这也会导致内存泄露。
- 闭包和延迟调用(defer):闭包可能会捕获并保存它们外部作用域的变量,如果这些变量的生命周期比闭包长,那么它们就可能会造成内存泄露。同时,延迟调用(defer)在函数退出之前不会被执行,如果函数长时间不退出,那么延迟调用也可能会导致内存泄露。
请说一下Go 原子操作有哪些?
Go语言中的原子操作主要由sync/atomic包提供,它包含了一系列的函数,可以在多线程环境中安全地操作一些基本的数据类型。以下列出了一些主要的原子操作函数:
AddInt32、AddInt64、AddUint32、AddUint64、AddUintptr:这些函数可以安全地将一个值加到一个整数或者指针。CompareAndSwapInt32、CompareAndSwapInt64、CompareAndSwapUint32、CompareAndSwapUint64、CompareAndSwapUintptr、CompareAndSwapPointer:这些函数实现了Compare And Swap(CAS)操作。CAS是一种无锁的技术,当多个线程尝试使用共享数据时,CAS能够检测到其他线程是否已经改变了这个数据。LoadInt32、LoadInt64、LoadUint32、LoadUint64、LoadUintptr、LoadPointer:这些函数可以安全地读取一个整数或者指针的值。StoreInt32、StoreInt64、StoreUint32、StoreUint64、StoreUintptr、StorePointer:这些函数可以安全地设置一个整数或者指针的值。SwapInt32、SwapInt64、SwapUint32、SwapUint64、SwapUintptr、SwapPointer:这些函数可以安全地交换一个整数或者指针的值。
以上的所有函数都是并发安全的,可以在多线程环境中使用。这些原子操作在实现无锁数据结构,比如计数器、循环队列等场景中非常有用。
Go 原子操作和锁的区别有哪些 ?
Go 中的原子操作和锁主要用于解决并发问题,但它们在使用方式和适用场景上有所不同:
- 操作方式:
- 原子操作:使用
sync/atomic包提供的原子函数,如AddInt32或CompareAndSwap,直接对变量进行原子性操作,避免了显式锁的使用。 - 锁:通过互斥锁(
sync.Mutex)来保护共享数据,确保同一时刻只有一个 goroutine 可以访问被保护的代码块。
- 原子操作:使用
- 性能:
- 原子操作:通常性能更高,因为它们不涉及上下文切换和线程调度,适合频繁的简单数据更新。
- 锁:在高竞争情况下可能导致性能下降,因为锁会引入等待和上下文切换的开销。
- 复杂性:
- 原子操作:适用于简单的整型或指针操作,适合简单状态的更新。
- 锁:可以保护更复杂的结构和逻辑,适用于需要多个操作原子性保障的场景。
- 使用场景:
- 原子操作:适合简单计数器、标志位等场景。
- 锁:适合需要访问复杂数据结构或多个变量的场景。
选择使用原子操作还是锁,通常取决于具体需求的复杂性和性能要求。
解释一下 Go hand off 机制 ?
在Go语言的并发模型中,”hand off”是指一个goroutine将控制权交给另一个goroutine的过程。这通常在以下几种情况下发生:
- 系统调用:当一个goroutine执行一个会阻塞的系统调用时,Go运行时会切换到另一个goroutine,让它在当前的线程上运行。这样可以保证线程不会因为一个阻塞的系统调用而被挂起,从而提高系统的并发性能。
- 通道操作:当一个goroutine在一个通道(channel)上执行发送或接收操作,并且该操作不能立即完成时(例如,通道已满或者为空),Go运行时会切换到另一个goroutine。这样可以避免当前的goroutine长时间等待,提高系统的响应性。
- 调度点:Go运行时有一套自己的调度器,它会在一些特定的点,例如函数调用、循环的开始等,检查是否需要切换到另一个goroutine。这可以保证每个goroutine都有运行的机会,从而避免某个goroutine长时间占用CPU。
在Go中,这个“hand off”机制是由Go的运行时系统自动管理的,程序员通常不需要直接处理。这使得写并发程序变得更简单,因为我们不需要关心线程管理和上下文切换等复杂的细节。
解释一下Go recover的执行时机 ?
Go语言中的recover函数是一个内建函数,它可以被用来捕获和处理panic。recover只在延迟函数(deferred
functions)中有效。如果在延迟函数中调用recover,并且在该goroutine中发生了panic,那么recover会捕获panic的值并恢复正常执行。如果在非延迟函数中调用recover,或者没有发生panic,那么recover将返回nil。
以下是一个使用recover的例子:
1 | |
Go在循环内部执行defer语句会发生什么 ?
在Go语言中,当你在循环内部执行defer语句时,每次循环迭代的defer都会被注册,但不会立即执行,而是等待包含该defer语句的函数结束时执行。这些defer调用会按照先进后出(LIFO)的顺序执行,即最后注册的defer语句会最先执行。
这是一个例子:
1 | |
在以上的例子中,输出结果会是:
1 | |
注意下面的代码和上面代码的区别:
1 | |
这段代码会输出:
1 | |
说一说Go语言触发异常的场景有哪些 ?
访问 nil 指针:
- 尝试对未初始化的指针进行解引用会导致 panic。
数组越界:
- 访问数组或切片时索引超出范围会触发 panic。
调用 panic 函数:
- 显式调用
panic()函数会立即触发异常。
类型断言失败:
- 当执行类型断言时,如果断言的类型不匹配,会导致 panic。
调用不存在的方法:
- 调用 nil 接口上的方法会引发 panic。
使用无效的格式化字符串:
- 在格式化输出中使用不匹配的占位符可能会导致 panic。
递归调用超出栈深度:
- 过深的递归会导致栈溢出,引发 panic。
如何解决Data Race问题?
在Go语言中,Data
Race(数据竞态)问题通常出现在多个goroutine同时读写共享数据时。以下是一些解决Data
Race问题的方法:
- 使用同步原语:Go提供了多种同步原语如
sync.Mutex、sync.RWMutex等,可以通过加锁的方式保证同一时间只有一个goroutine可以访问共享数据。 - 使用Channel:在Go中,通道(Channel)是一种特殊的类型,可以用来传递类型化的数据。我们可以使用Channel来实现
goroutine之间的同步,避免数据竞态。通常我们会遵循“不要通过共享内存来通信,而应通过通信来共享内存”的原则。 - 使用原子操作:
sync/atomic包提供了低级的原子内存操作支持。原子操作可以保证任何时刻只有一个goroutine可以操作数据。 - 使用
sync.Map:对于map类型,Go提供了并发安全的sync.Map。如果在多个goroutine中同时读写同一个map,可以考虑使用sync.Map。 - 使用Race
Detector:Go提供了数据竞态检测器,可以在运行时检测并报告数据竞态问题。使用
go run -race或go test -race等命令可以启动Race Detector。
怎么在Golang中实现协程池?
Go语言并没有内置的协程池(goroutine
pool)实现,但我们可以通过通道(channel)和sync包中的工具来实现一个。以下是一个简单的协程池实现的例子:
1 | |
解释一下Golang中的sync.Once?
在Go语言中,sync.Once是一个同步原语,可以确保某个操作(例如初始化)只执行一次,即使在并发环境中也是安全的。
sync.Once有一个Do方法,接受一个函数作为参数。无论Do方法被调用多少次,这个函数都只会被执行一次。
以下是一个sync.Once的使用示例:
1 | |
在这个示例中,即使有10个goroutine并发调用once.Do(doSomething),doSomething函数也只会被执行一次。
sync.Once在初始化全局变量或只需要执行一次的设置操作等场景中非常有用。例如,你可能要创建一个单例对象,但在并发环境中,你需要确保对象只被创建一次。在这种情况下,你可以使用sync.Once来实现这个功能。
简述一下内存逃逸?什么情况下会发生内存逃逸 ?
内存逃逸(Memory Escape)是Go语言中的一个概念,涉及到Go的内存管理和垃圾收集机制。当我们说一个对象发生了内存逃逸,意味着这个对象的生命周期不仅限于它被创建的函数,而且在函数返回后,这个对象依然可以被访问。这样的对象不能被分配在栈上,而是要在堆上进行分配。
以下是几种可能导致内存逃逸的情况:
1. 返回局部变量的指针:如果函数返回其局部变量的指针,那么这个局部变量就不能在栈上分配,因为栈空间会在函数返回后被回收。
2. 将局部变量赋值给全局变量:同样,如果函数将其局部变量的引用赋值给一个全局变量,那么这个局部变量就不能在栈上分配。
3. 将局部变量的引用放入到接口值、切片或者地图等数据结构中:如果函数将局部变量的引用放入到这些数据结构中,那么这个局部变量就不能在栈上分配。
Linux
linux系统查看cpu占用的命令(腾讯云)
top命令可以看到总体的系统运行状态和cpu的使用率
1
2
3top
# 或
top -u roothtop命令是top命令的增强版(默认情况htop没有安装在linux上,所以要先安装)
1
htop使用ps命令来查看cpu使用率
1
ps aux | sort -nrk 3,3 | head -n 5
gdb如何调试
编译程序时加上调试信息: 在使用GDB进行调试之前,需要确保编译程序时包含调试信息。通常可以通过在编译命令中添加
-g选项来生成调试信息,例如:1
gcc -g -o my_program my_program.c启动GDB: 在命令行中输入
gdb命令,然后在GDB提示符下输入要调试的可执行文件的名称,例如:1
gdb my_program设置断点: 在GDB中设置断点,以便在程序执行到指定位置时停止执行。可以通过以下命令设置断点:
break function_name:在指定函数的入口处设置断点。break line_number:在指定行号处设置断点。break file_name:line_number:在指定文件的指定行号处设置断点。
gdb运行报错如何通过core⽂件找到错误
编译程序时包含调试信息: 在编译程序时确保包含了调试信息,以便在后续调试时能够查看到源代码的信息。使用编译器选项
-g来生成调试信息。使用GDB调试core文件: 在命令行中输入以下命令:
1 | |
其中,<executable_file>是你编译的可执行文件的名称,<core_file>是core文件的名称。
分析core文件:
在GDB中加载core文件后,可以使用bt命令查看堆栈回溯信息,以确定程序崩溃时的函数调用栈。例如:
- 分析core文件:
在GDB中加载core文件后,可以使用
bt命令查看堆栈回溯信息,以确定程序崩溃时的函数调用栈。例如:
1 | |
- 查看变量值: 在确定了程序崩溃的位置后,可以使用GDB中的命令查看局部变量、全局变量等的值,以帮助分析错误。例如:
1 | |
- 分析源代码: 使用GDB中的命令在源代码中查看程序崩溃的位置以及附近的代码,帮助理解问题所在。例如:
1 | |
如何加断点,具体api调⽤
使用break命令
1 | |
调用api不会
gdb如何查看函数调用栈
在终端中启动 GDB 并加载你的可执行文件:
1
gdb your_executable运行程序,直到你想要查看函数调用栈的地方。
在 GDB 提示符下,输入
bt或backtrace命令:1
(gdb) bt
epoll函数参数
在使用 Linux 中的 epoll API 进行事件驱动编程时,主要使用的函数是
epoll_create、epoll_ctl 和
epoll_wait。下面是它们的基本参数:
- epoll_create(int size):
size:指定需要监听的文件描述符的数量的估计值。这个参数在 epoll 实例被内核创建时用于分配内部数据结构的大小。通常情况下,你可以将其设置为大于 0 的任意值,因为内核会根据需要调整大小。但是,对于 Linux 2.6.8 及更早版本的内核,这个参数被忽略,可以设置为任意值。
- epoll_ctl(int epfd, int op, int fd, struct epoll_event
*event):
epfd:epoll 实例的文件描述符,由epoll_create返回。op:表示要执行的操作,可以是以下值之一:EPOLL_CTL_ADD:向 epoll 实例中添加一个要监听的文件描述符。EPOLL_CTL_MOD:修改 epoll 实例中某个文件描述符的监听事件。EPOLL_CTL_DEL:从 epoll 实例中删除一个不再需要监听的文件描述符。
fd:要添加、修改或删除的文件描述符。event:指向struct epoll_event结构的指针,描述了要监听的事件类型。
- epoll_wait(int epfd, struct epoll_event *events, int
maxevents, int timeout):
epfd:epoll 实例的文件描述符,由epoll_create返回。events:用于存储发生事件的文件描述符和事件类型的数组。maxevents:events数组的大小,表示最多可以存储多少个事件。timeout:等待事件的超时时间,以毫秒为单位。可以有以下几种取值:-1:无限等待,直到有事件发生。0:立即返回,不等待事件。>0:等待指定的毫秒数后返回,即使没有事件发生。
⼀个⽂件,有⼏千万⾏,有IP地址、访问时间、url,访问topk出现频率的IP或url的命令
假设文件名为 access.log,文件内容类似于:
1 | |
统计 IP 地址的频率:
1 | |
这个命令的含义是:
- 使用
awk '{print $1}'提取每行的第一个字段(即 IP 地址)。 - 使用
sort对 IP 地址进行排序。 - 使用
uniq -c对排序后的 IP 地址进行统计,并输出每个 IP 地址出现的次数。 - 使用
sort -nr对统计结果进行逆序排序。 - 使用
head -n K只输出前 K 个结果,即 Top K 出现频率的 IP 地址。
awk命令
awk
是一种文本处理工具,通常用于对文本文件进行行处理和字段处理。它以行为单位逐行读取输入文件,并根据用户指定的模式和动作对每行进行处理。awk
的语法比较灵活,可以用于过滤、转换和格式化文本数据。
例如,以下是一个简单的 awk
命令示例,用于提取文本文件中的第二列:
1 | |
这个命令会读取 filename.txt
文件的每一行,并将每行的第二列打印输出。
Linux的进程调度(腾讯云)
GDB 调试遇到stackovlerflow怎么办?
如果按照一般的方式编译:
gcc –o stackoverflow stackoverflow.c
linux系统能够探测到程序中的stack overflow,从而终止程序,如下图所示:

那有没有办法让系统不探测到stack overflow,此处可以在编译时,禁用堆栈保护,具体命令如下:
gcc –fno-stack-protector –o stackoverflow stackoverflow.c
然后采用gdb调试stackoverflow。
fork函数
fork就会复制一份原来的进程即就是创建一个新进程,我们称子进程,而原来的进程我们称为父进程,此时父子进程是共存的,他们一起向下执行代码。
fork的返回值问题:
在父进程中,fork返回新创建子进程的进程ID;
在子进程中,fork返回0;
如果出现错误,fork返回一个负值;
getppid():得到一个进程的父进程的PID;
getpid():得到当前进程的PID;
linux查看现在运行的所有进程
ps aux
linux日志查询
cat /var/log/syslog
linux如何在日志中查找某个数据
grep "keyword" /var/log/syslog
fork() 的原理,哪里体现了fork分配资源?
复制堆栈段,数据段,栈段等内存布局,但是代码段是映射的父进程的代码段以节省空间
fork()是把进程从1个变成2个,那么最初的进程是从哪里来的?
系统启动时先加载内核,然后通过引导程序启动初始进程init或者叫systemd进程,是整个进程树的根节点
启动进程是用户态还是内核态?
systemd进程是内核直接创建的,因此是内核态进程
栈和堆大小是多少,堆动态开辟的话能和内存一样大吗
Linux下进程栈的默认大小是10M,可以通过ulimit -s查看并修改默认栈大小。 默认一个线程要预留1M左右的栈大小,所以进程中有N个线程时,Windows下大概有N*M的栈大小。 堆的大小理论上大概等于进程虚拟空间大小-内核虚拟内存大小。
多线程的线程栈分配在哪里?
什么是协程?
协程是另一种轻量级的执行单元。协程不是进程或线程,协程的调度完全由用户控制(也就是在用户态执行)。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到线程的堆区,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
协程最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和线程切换相比,线程数量越多,协程的性能优势就越明显。不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。此外,一个线程的内存在MB级别,而协程只需要KB级别。
磁盘空间使用情况可以
通过df -h命令查看
linux如何让程序后台运行,又如何让后台的程序来到前台
将程序后台运行
使用
&符号: 在运行程序的命令行末尾添加&符号可以将程序放入后台运行,例如:1
./my_program &使用
nohup命令: 使用nohup命令可以让程序在后台运行,并且在用户退出登录时仍然保持运行。示例:1
2bashCopy code
nohup ./my_program &使用
screen或tmux: 使用screen或tmux可以创建一个会话,并在其中运行程序,然后可以断开终端连接而不中断程序执行。示例:1
2bashCopy codescreen -S session_name
./my_program
将后台的程序切换到前台
使用
fg命令:fg命令用于将最近放入后台的作业切换到前台。示例:1
fg使用
jobs和fg命令:jobs命令用于列出后台运行的作业,然后使用fg %job_number将特定的作业切换到前台。示例:1
2jobs
fg %1使用
screen或tmux: 如果使用了screen或tmux,可以重新连接到会话并恢复程序运行。使用screen -r或tmux attach命令来重新连接到会话。
Linux下rm正在写入的文件会发生什么
只会删除文件名,并不会删除文件内容,只有所有打开此文件的进程都关闭此文件后(注意当进程退出时,会自动关闭所有打开的文件),文件内容才会被真正删除。
Linux开机过程
Linux的开机过程大致可以分为以下几个步骤:
- BIOS/UEFI阶段:
- 计算机开机后,BIOS或UEFI会进行自检(POST),并初始化硬件。
- 之后,它会查找启动设备(如硬盘、USB等)并加载引导程序。
- 引导加载程序(Bootloader):
- 引导程序(如GRUB)被加载到内存中。它负责选择并加载操作系统内核。
- 用户可以选择不同的内核或操作系统(如果安装了多个)。
- 内核加载:
- 引导程序将Linux内核加载到内存,并传递控制权给内核。
- 内核初始化硬件,挂载根文件系统,并启动init进程。
- init进程启动:
init是第一个用户空间进程(PID为1),负责启动其他进程。- 根据系统的运行级别或目标(如
systemd或传统的SysVinit),它会启动相应的服务和守护进程。
- 系统服务启动:
- 根据配置文件(如
/etc/systemd/system或/etc/init.d/),启动网络、日志、用户会话等服务。 - 这一步骤可能包括运行脚本来初始化环境。
- 根据配置文件(如
- 登录界面:
- 最后,系统会显示登录提示(CLI或图形界面),用户可以输入凭据登录。
整个过程从硬件初始化到用户登录,涉及多个组件的协同工作,确保系统能够顺利启动并提供服务。
linux文件描述符的范围是多少?
在Linux中,文件描述符(file descriptor)的范围通常是从0开始到一个最大值。默认情况下,文件描述符的最大值通常为1024,但这个值可以根据系统的设置和具体应用进行调整。
具体而言:
- 标准文件描述符:
- 0: 标准输入(stdin)
- 1: 标准输出(stdout)
- 2: 标准错误(stderr)
- 最大文件描述符数:
- 可以通过命令
ulimit -n查看当前用户的最大文件描述符数。 - 系统级别的限制可以在
/etc/security/limits.conf中进行设置。
- 可以通过命令
go内存泄漏如何排查
- 使用Go内置的内存分析工具:
可以使用
go tool pprof来分析内存使用情况。首先,在代码中导入net/http/pprof包,并启动一个HTTP服务器:1
2
3
4import _ "net/http/pprof"
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()然后,运行程序并访问
http://localhost:6060/debug/pprof/heap下载堆内存的分析数据。
计算机网络
http协议里 301 304啥用处(腾讯云)
301永久重定向;302临时重定向;304未修改,重定向到已存在的缓存文件
http请求过程(腾讯云)
- ⾸先,我们在浏览器地址栏中,输⼊要查找⻚⾯的URL,按下Enter
- 浏览器依次在 浏览器缓存 -->>系统缓存 -->>路由器缓存中去寻找匹配的URL,若有,就会直接在屏幕中显示出⻚⾯内容。若没有,则跳到第三步操作
- 发送HTTP请求前,浏览器需要先进⾏域名解析(即DNS解析),以获取相应的IP地址;(浏览器DNS缓存、路由器缓存、DNS缓存)
- 获取到IP地址之后,浏览器向服务器发起TCP连接,与浏览器建⽴TCP三次握⼿
- 握⼿成功之后,浏览器就会向服务器发送HTTP请求,来请求服务器端的数据包
- 服务器处理从浏览器端收到的请求,接着将数据返回给浏览器
- 浏览器收到HTTP响应
- 查询状态,状态成功则进⾏下⼀步,不成功则弹出相应指示
- 再读取⻚⾯内容、进⾏浏览器渲染、解析HTML源码;(⽣成DOM树、解析CCS样式、处理JS交互,客户端和 服务器交互)进⾏展示
- 关闭TCP连接(四次挥⼿)
TCP一二三次握手报文丢失分别会发生什么?
第一次握手丢失
客户端发送SYN请求连接报文,如果迟迟等不到服务器的请求确认报文段,那么就会进行超时重传,具体重传几次,要看tcp_syn_retries内核参数,一般默认是5次。要注意的是,重传的请求连接报文的seq序列号字段还是之前的seq,不会重新生成哦。
note
如果seq一样,那么客户端如何区分服务器端的回复是已经过期的syn包的回复呢?TCP有一个时间戳选项,客户端可以根据时间戳来判断包是否过期,如果过期就回复rst重置连接,避免服务器资源浪费。
第二次握手丢失
第二次握手丢失就有意思了,因为服务器发送的第二次握手是连接确认报文段,既包括对第一次握手的ACK确认,同时还有SYN字段表示要建立连接,所以第二次握手也可以成为SYN-ACK报文。所以当第二次握手丢失,客户端迟迟等不到第一次握手的确认,就会触发超时重传机制,进行超时重传;服务器等不到自己SYN连接的确认,也会进行超时重传。客户端和服务器具体的超时重传次数还是由内核参数决定。
第三次握手丢失
第三次握手丢失,此时客户端已经处于established状态了,因为它通过两次握手已经验证了自己的发送和接收能力嘛。但是此时第三次握手丢失,服务器迟迟得不到ACK报文,但是ACK报文丢失,ACK 报文是不会有重传的,当 ACK 丢失了,就由对方重传对应的报文。所以当到达服务器的超时重传时间后,服务器会超时重传第二次报文,当达到最大超时重传次数还没得到ACK报文,服务器就会断开连接。
Tcp三次握手过程,为什么不是两次(腾讯云)
TCP为什么四次挥手(腾讯云)
TCP的稳定性机制
TCP协议通过以下几种机制来确保数据的可靠传输和接收:
三次握手四次挥手保证建立和断开连接的有效性
序列号和确认应答:发送方将每个数据包进行编号,并且接收方要对每个数据包进行确认应答。这样可以确保数据包的顺序和完整性。
超时重传:如果发送方在一定时间内没有收到接收方的确认应答,就会重新发送数据包,以确保数据的可靠传输。
流量控制:TCP协议使用滑动窗口机制来控制发送方和接收方之间的数据流量,避免发送过多的数据导致接收方无法处理。
拥塞控制:TCP协议通过拥塞窗口机制来避免网络拥塞,当网络出现拥塞时,发送方会减小发送窗口的大小,以减缓数据包的发送速度。
综合上述机制,TCP协议能够确保数据的可靠传输和接收,从而保证了网络通信的稳定性和可靠性。
关键字:序列号,确认应答,超时重传,流量控制,拥塞控制
服务端出现大量close_wait 的原因可能是什么?
close_wait
按照正常操作的话应该很短暂的一个状态,接收到客户端的fin包并且回复客户端ack之后,会继续发送FIN包告知客户端关闭关闭连接,之后迁移到Last_ACK状态。但是close_wait过多只能说明没有迁移到Last_ACK,也就是服务端是否发送FIN包,只有发送FIN包才会发生迁移,所以问题定位在是否发送FIN包。FIN包的底层实现其实就是调用socket的close方法,这里的问题出在没有执行close方法。说明服务器CPU处理不过来(CPU太忙)或者服务器端忘记调用close函数或者应用程序一直睡眠得不到调度。
解释一下time_wait作用(腾讯云)
- 可靠地实现TCP全双工连接的终止
在进行关闭连接四次挥手协议时,最后的ACK是由主动关闭端发出的,如果这个最终的ACK丢失,服务器将重发最终的FIN,因此客户端必须维护状态信息允许它重发最终的ACK。如果不维持这个状态信息,那么客户端将响应RST分节,服务器将此分节解释成一个错误(在java中会抛出connection reset的SocketException)。
因而,要实现TCP全双工连接的正常终止,必须处理终止序列四个分节中任何一个分节的丢失情况,主动关闭的客户端必须维持状态信息进入TIME_WAIT状态。
- 允许老的重复分节在网络中消逝
TCP分节可能由于路由器异常而“迷途”,在迷途期间,TCP发送端可能因确认超时而重发这个分节,迷途的分节在路由器修复后也会被送到最终目的地,这个原来的迷途分节就称为lost duplicate。
在关闭一个TCP连接后,马上又重新建立起一个相同的IP地址和端口之间的TCP连接,后一个连接被称为前一个连接的化身(incarnation),那么有可能出现这种情况,前一个连接的迷途重复分组在前一个连接终止后出现,从而被误解成从属于新的化身。
为了避免这个情况,TCP不允许处于TIME_WAIT状态的连接启动一个新的化身,因为TIME_WAIT状态持续2MSL,就可以保证当成功建立一个TCP连接的时候,来自连接先前化身的重复分组已经在网络中消逝。
TCP为什么会粘包(腾讯云)
由于Nagle算法的优化会将多个小数据合成大数据发送
粘包的包是在哪合成的
TCP粘包的包是在发送方的操作系统合成的。当应用程序通过TCP发送数据时,数据首先会被放入缓冲区。操作系统根据网络条件和其他因素决定何时发送这些缓冲区中的数据。如果一段时间内多个小数据包被放入缓冲区,而发送方的操作系统认为可以发送数据时,它可能会将这些小数据包合并成一个较大的数据包,然后发送到网络中。
Nagle算法开启有什么好处和坏处
好处:
- 减少网络流量: 通过合并小数据包,减少了网络传输中的数据包数量,降低了网络拥塞的可能性,提高了网络的利用率。
- 减轻网络负载: 减少了发送小数据包的频率,降低了网络设备的负载,有助于提高网络的性能。
坏处:
- 引入延迟: Nagle算法会等待一小段时间,尝试合并多个小数据包成一个大的数据包再进行发送。这样会导致数据的传输延迟增加,尤其是在对实时性要求较高的应用中,如在线游戏或实时视频流。
- 小消息传输受阻: 在某些情况下,如果有一些小数据包需要立即发送,启用Nagle算法可能导致这些小数据包被延迟发送,影响了实时性。
拆包的原因
如果发送端缓冲区的长度大于网卡的MTU时,TCP会将这次发送的数据拆成几个数据包发送出去。也就是说,发送端可能只发送了一次数据,接收端却要分好几次才能收到完整的数据。
粘包问题怎么解决?
发送方:通过关闭Nagle算法来解决,使用TCP_NODELAY选项来关闭算法。
接收方:没有办法直接处理粘包问题,只能交给应用层解决.
- 格式化数据:每条数据有固定的格式(开始符,结束符),这种方法简单易行,但是选择开始符和结束符时一定要确保每条数据的内部不包含开始符和结束符。
- 发送长度:发送每条数据时,将数据的长度一并发送,例如规定数据的前4位是数据的长度,应用层在处理时可以根据长度来判断每个分组的开始和结束位置。
- 将包封装为固定长度,不够长度的用0填充。
注意:TCP头部字段是头部长度,并没有标识数据长度的字段.
TCP的重传机制(腾讯云)
数据发送之后会等待对方的确认,如果定时器超时而没有收到确认,发送方就假设数据丢失,触发重传机制。
TCP还采用了一种称为快速重传的机制。如果发送方连续收到三个相同序列号的确认,它会认为在这个序列号之前的数据段已经丢失,会立即重传该数据段,而不等待定时器超时。
拥塞窗口与流量窗口有什么区别(腾讯云)
拥塞窗口(Congestion Window)和流量窗口(Window Size)是TCP协议中的两个概念,它们用于控制和调整数据的传输速率,但有一些关键的区别。
- 拥塞控制是指根据网络的拥塞程度来调节发送数据的速率,以避免网络拥塞导致丢包和网络性能下降。
- 流量控制是指接收方通知发送方自己的缓冲区大小,发送方根据接收方的缓冲区大小来控制发送数据的速率,以防止接收方的缓冲区溢出。
HTTP状态码
SSL/TLS建立的时候和域名绑定还是ip绑定
SSL/TLS 建立时是与域名绑定的,而不是 IP 绑定。
DNS和域名绑定还是ip绑定
域名
HTTP多个TCP连接怎么实现
HTTP一定要用TCP实现吗
不一定,HTTP3就是用UDP实现的。QUIC是谷歌开发的基于UDP的传输协议,旨在提供更快的连接建立和更低的延迟。HTTP/3标准使用了QUIC作为传输层协议,因此可以说HTTP/3是基于QUIC实现的。与TCP相比,QUIC具有更快的连接建立速度和更好的拥塞控制,但也存在部署和兼容性等方面的挑战。
HTTPs建立连接的过程
- 客户端发起连接请求:
- 客户端向服务器发起连接请求,请求建立安全连接。客户端会发送一个HTTPS请求,其中包含了一些与SSL/TLS相关的信息,如支持的加密算法和SSL/TLS版本等。
- 服务器返回证书:
- 服务器收到客户端的连接请求后,会向客户端发送服务器的数字证书,证书中包含了服务器的公钥、服务器的身份信息和证书的有效期等信息。服务器的证书是由可信任的证书颁发机构(Certificate Authority,CA)签发的,客户端可以通过CA证书来验证服务器的证书的真实性和合法性。
- 客户端验证证书:
- 客户端收到服务器发送的证书后,会进行证书的验证。客户端会检查证书的有效性、是否由可信任的CA签发、证书的有效期等信息,以确保服务器的身份和证书的合法性。如果证书验证失败,客户端会中断连接,否则继续连接。
- 客户端生成随机密钥:
- 客户端生成一个随机数作为对称密钥,并使用服务器的公钥加密该密钥,然后发送给服务器。对称密钥是用于对数据进行加密和解密的密钥,这样可以保证数据的机密性。
- 服务器使用私钥解密密钥:
- 服务器收到客户端发送的加密后的对称密钥后,使用自己的私钥进行解密,得到对称密钥。
- 建立安全通道:
- 客户端和服务器都使用协商好的对称密钥来加密和解密通信中的数据,从而建立安全的通信通道。此后,客户端和服务器之间的所有数据传输都会通过这个加密通道进行加密和解密,保证了数据的机密性和完整性。
HTTPS客户端是怎么验证CA证书的有效性的
首先 CA 会把持有者的公钥、用途、颁发者、有效时间等信息打成一个包,然后对这些信息进行 Hash 计算,得到一个 Hash 值;
然后 CA 会使用自己的私钥将该 Hash 值加密,生成 Certificate Signature,也就是 CA 对证书做了签名;
最后将 Certificate Signature 添加在文件证书上,形成数字证书;
客户端会使用同样的 Hash 算法获取该证书的 Hash 值 H1;
通常浏览器和操作系统中集成了 CA 的公钥信息,浏览器收到证书后可以使用 CA 的公钥解密 Certificate Signature 内容,得到一个 Hash 值 H2 ;
最后比较 H1 和 H2,如果值相同,则为可信赖的证书,否则则认为证书不可信。
很多closewait状态是什么原因
服务端的程序没有调用close 函数关闭连接。
客户端close了服务端发送数据会发⽣什么
根据TCP协议,客户端会向服务器发送一个RST(重置)报文,表明这是一个不再有效的连接。服务器端在收到RST报文后,应该意识到连接已经被客户端关闭,并停止尝试发送数据。
VPN在哪⼀层⽹络模型实现的
VPN(虚拟专用网络)可以在不同的网络层次上实现,具体取决于它使用的技术和协议。以下是VPN的一些常见实现层次:
- 应用层:例如SSL VPN
- 网络层:例如IPSEC VPN、GRE VPN
- 数据链路层:例如L2TP VPN、PPTP VPN
王者荣耀是Tcp还是Udp链接?
王者荣耀游戏的启动和登录采用TCP连接,客户端操作与界面显示是通过UDP数据流与服务器进行交互的。
如何判断tcp还是udp呢?
- 端口号:一些常见的端口号被分配给了特定的协议,例如 HTTP 使用 TCP 的端口 80,DNS 使用 UDP 的端口 53。
- 包头标识:TCP 和 UDP 数据包的包头中包含了不同的字段和标识符。例如,TCP 的包头中有一个字节的标识符字段,用于指示该数据包是 TCP 数据包;而 UDP 的包头中没有类似的标识符字段。因此,可以通过解析数据包的包头来确定其所使用的协议。
- 协议类型字段:数据包的协议类型可能会被直接指定在 IP 包头中的协议字段中。TCP 使用值 6 表示,UDP 使用值 17 表示。
什么是网络地址转换(Network Address Translation,NAT)?请解释 NAT 的原理和应用场景。
网络地址转换(Network Address Translation,NAT)是一种网络技术,用于将私有网络中的 IP 地址映射到公共网络中的 IP 地址,以便实现私有网络中的多个主机共享一个或多个公共 IP 地址的功能。
NAT 的工作原理如下:
- 内部网络:在私有网络(如家庭网络、企业网络)中,主机通常使用私有 IP 地址(例如 192.168.x.x、10.x.x.x、172.16.x.x 等)来进行通信,这些地址在全球范围内并不唯一。
- NAT 设备:在私有网络和公共网络之间,存在一个 NAT 设备(通常是路由器或防火墙),它负责管理私有网络和公共网络之间的数据传输。
- 地址映射:当内部网络中的主机尝试与外部网络通信时,NAT 设备会将内部主机的私有 IP 地址转换成路由器的公共 IP 地址,然后将数据包发送到外部网络。在数据包返回时,NAT 设备会将公共 IP 地址转换回相应的私有 IP 地址,然后将数据包传递给内部主机。
- 端口转换:除了进行 IP 地址的转换之外,NAT 设备还可以进行端口转换,通过修改数据包中的端口号来实现多个内部主机共享一个公共 IP 地址的功能。
NAT 的应用场景包括但不限于以下几个方面:
- 节省 IP 地址:NAT 允许多个内部主机共享一个公共 IP 地址,从而节省了公共 IP 地址的使用,特别是在 IPv4 地址资源日益枯竭的情况下,NAT 可以有效地延长 IPv4 地址的使用寿命。
- 网络隔离:NAT 设备可以将内部网络与外部网络隔离开来,从而提高了网络的安全性和隐私保护。
- 访问控制:NAT 设备可以实现端口转发和端口过滤等功能,对内部网络的访问进行控制和管理。
- 动态地址分配:NAT 设备可以为内部主机动态分配公共 IP 地址,从而实现了灵活的网络配置和管理。
什么是虚拟专用网络(Virtual Private Network,VPN)?请解释 VPN 的原理和使用场景。
虚拟专用网络(VPN)是一种通过公共网络(通常是互联网)在远程位置之间创建安全连接的技术。它允许用户通过加密通道安全地传输数据,就像在私有网络中一样。
原理:
- 隧道协议:虚拟专用网络本质上是在您的本地设备和位置远隔千里的另一台 VPN 服务器之间创建一个安全数据隧道。当您联机时,此 VPN 服务器将成为您接收所有数据的来源。您的网络服务提供商(ISP)和其他第三方将无法再看到您的互联网流量的内容。
- 加密:IPSec 等 VPN 协议会对数据进行加密,然后再通过数据隧道发送数据。IPsec 是一个协议套件,通过验证和加密数据流的每个 IP 数据包来保护 Internet 协议(IP)通信。VPN 服务就好比一个筛选器,使您的数据在一端无法读取,并且只在另一端进行解码 – 这可防止个人数据滥用,即使您的网络连接被破坏时也是如此。网络流量不再容易受到攻击,您的互联网连接也是安全的。
使用场景:
- 远程访问: 允许用户通过互联网安全地访问公司内部网络资源。远程工作者可以通过 VPN 连接到公司网络,并访问文件、应用程序和其他资源,就像他们在办公室内一样。
- 绕过地理限制: 通过连接到不同地区的 VPN 服务器,用户可以绕过地理限制,访问被限制的内容,如特定国家或地区的网站、流媒体服务等。
- 保护隐私: 在连接到公共 Wi-Fi 热点时,使用 VPN 可以增加安全性和隐私保护,防止黑客窃取敏感信息。
长连接和短链接,以及他们各自的应用场景,如何实现一个长连接
长连接:长连接,指在一个连接上可以连续发送多个数据包,在连接保持期间,如果没有数据包发送,需要双方发链路检测包。
短连接:短连接(short connnection)是相对于长连接而言的概念,指的是在数据传送过程中,只在需要发送数据时,才去建立一个连接,数据发送完成后,则断开此连接,即每次连接只完成一项业务的发送。
应用场景
长连接:长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。
短连接:而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源。
http报文组成
HTTP报文分为请求报文和响应报文。
请求报文(Request Message)
请求行(Request Line):包括请求方法、请求的URL和HTTP协议版本。
1
请求方法 URL HTTP协议版本例如:
1
2code
GET /index.html HTTP/1.1请求头部(Request Headers):包括多个键值对,描述了请求的各种属性和参数。
1
2
3codeHeaderName1: HeaderValue1
HeaderName2: HeaderValue2
...例如:
1
2
3codeHost: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9空行(Blank Line):请求行和请求头部之后的一个空行,用于分隔请求头部和请求体。
请求体(Request Body):可选部分,用于传输请求相关的数据。在GET请求中通常为空,而在POST等请求中包含具体的数据。
响应报文
状态行(Status Line):包括HTTP协议版本、状态码和状态消息。
1
HTTP协议版本 状态码 状态消息例如:
1
HTTP/1.1 200 OK响应头部(Response Headers):与请求头部类似,包括多个键值对,描述了响应的各种属性和参数。
空行(Blank Line):状态行和响应头部之后的一个空行,用于分隔响应头部和响应体。
响应体(Response Body):包含实际的响应数据,例如HTML文档、JSON数据等。
HTTP报文的组成部分是根据HTTP协议规范定义的,它们共同构成了HTTP通信中传输的数据格式。
HTTP3和HTTP2的区别?QUIC协议原理?
QUIC:基于UDP,不需要握手和挥手,同时实现了类似TCP的流量控制、传输可靠性的功能,集成了TLS加密功能,使用TLS1.3,TLS1.2需要1-2RRT才可以建立连接,而1.3完全建立连接需要1个RTT,而恢复会话需要0个RTT;多路复用,彻底解决TCP中队头阻塞的问题.
你了解的网络攻击方式有哪些?SYN攻击的防范方法?
攻击方式:
- DDoS 攻击:分布式拒绝服务(DDoS)攻击旨在通过同时向目标系统发送大量请求来耗尽目标系统的资源,使其无法正常工作。
- SQL 注入攻击:SQL 注入攻击是通过向应用程序的输入字段插入恶意 SQL 代码来利用应用程序对数据库的不安全输入验证,从而执行未经授权的数据库操作。
SYN攻击是一种常见的DoS攻击,利用 TCP 协议中的三次握手过程的漏洞,向目标服务器发送大量的伪造 SYN 请求,使目标服务器资源耗尽,无法响应正常用户的请求。防范 SYN 攻击的常用方法包括:
- SYN 攻击检测与过滤:通过网络防火墙、入侵检测系统(IDS)等设备,对网络流量进行实时监控,识别并过滤掉恶意的 SYN 请求。
- SYN Cookie 技术:服务器端可以使用 SYN Cookie 技术来减轻 SYN 攻击带来的影响,该技术在处理 TCP 连接请求时不会为每个请求都创建一个完整的连接状态,而是根据请求信息生成一个特殊的 Cookie 值,只有当客户端发送 ACK 确认时,服务器才会创建真正的连接。
- 增加连接数限制:在服务器端配置最大连接数限制,防止单个 IP 地址同时建立过多的连接。
- 使用反向代理:通过将服务器后面添加反向代理,将真实的服务器地址隐藏起来,减轻攻击对服务器的直接影响。
- 增加系统资源:增加服务器的网络带宽、CPU 和内存等资源,提高服务器抵御 SYN 攻击的能力。
SYN Cookie技术
我们知道,TCP连接建立时,双方的起始报文序号是可以任意的。SYN cookies利用这一点,按照以下规则构造初始序列号:
- 设
t为一个缓慢增长的时间戳(典型实现是每64s递增一次) - 设
m为客户端发送的SYN报文中的MSS选项值 - 设
s是连接的元组信息(源IP,目的IP,源端口,目的端口)和t经过密码学运算后的Hash值,即s = hash(sip,dip,sport,dport,t),s的结果取低 24 位
则初始序列号n为:
- 高 5 位为
t mod 32 - 接下来3位为
m的编码值 - 低 24 位为
s
当客户端收到此SYN+ACK报文后,根据TCP标准,它会回复ACK报文,且报文中ack = n + 1,那么在服务器收到它时,将ack - 1就可以拿回当初发送的SYN+ACK报文中的序号了!服务器巧妙地通过这种方式间接保存了一部分SYN报文的信息。
接下来,服务器需要对ack - 1这个序号进行检查:
- 将高 5
位表示的
t与当前之间比较,看其到达地时间是否能接受。 - 根据
t和连接元组重新计算s,看是否和低 24 一致,若不一致,说明这个报文是被伪造的。 - 解码序号中隐藏的
mss信息
到此,连接就可以顺利建立了。
缺点:
MSS的编码只有3位,因此最多只能使用 8 种MSS值- 增加了密码学运算
- 服务器必须拒绝客户端
SYN报文中的其他只在SYN和SYN+ACK中协商的选项,原因是服务器没有地方可以保存这些选项,比如Wscale和SACK。
TIME_WAIT状态过多要怎么解决?
编辑内核文件/etc/sysctl.conf,加入以下内容:
1 | |
udp如何变得安全
- 实现多路径传输:通过利用多个网络路径同时进行文件传输,分散数据流量,避免单一路径的拥堵问题,提高UDP协议的传输速度和稳定性。
- 应用数据重传机制:当接收端收到不完整的数据时,可以请求发送端重新发送丢失的数据段,保证数据的完整性和可用性。
- 加入安全认证机制:通过使用加密算法和数字签名等技术,保证数据信息的机密性和完整性,防止黑客攻击和数据泄露。
为什么DNS协议不用TCP?
UDP更快,TCP还需要三次握手,四次挥手;三次握手的时间UDP已经传完了。
另外,如果本地查询没有查到,需要本地DNS服务器迭代向顶级域名DNS服务器、权威域名DNS服务器迭代查询,如果每次都需要TCP三次握手,四次挥手,那么跟UDP的差距就很大了。
TCP连接如果客户端拔掉网线会怎么样?
- 如果网线断开的时间短暂,在SO_KEEPALIVE设定的探测时间间隔内,并且两端在此期间没有任何针对此长连接的网络操作。当连上网线后此TCP连接可以自动恢复,继续进行正常的网络操作。
- 如果网线断开的时间很长,超出了SO_KEEPALIVE设定的探测时间间隔,或者两端期间在此有了任何针对此长连接的网络操作。当连上网线时就会出现ETIMEDOUT或者ECONNRESET的错误。你必须重新建立一个新的长连接进行网络操作。
客户端与服务器端建立连接,如果服务器端进程崩了会怎么样?
TCP 的连接信息是由内核维护的,所以当服务端的进程崩溃后,内核需要回收该进程的所有 TCP 连接资源,于是内核会发送第一次挥手 FIN 报文,后续的挥手过程也都是在内核完成,并不需要进程的参与,所以即使服务端的进程退出了,还是能与客户端完成 TCP四次挥手的过程。
服务端主机宕机后,客户端会发生什么?
分为客户端向服务器端发送数据和不发送数据两种情况:
服务端主机宕机后,如果客户端会发送数据
在服务端主机宕机后,客户端发送了数据报文,由于得不到响应,在等待一定时长后,客户端就会触发超时重传机制,重传未得到响应的数据报文。
当重传次数达到达到一定阈值后,内核就会判定出该 TCP 连接有问题,然后通过 Socket 接口告诉应用程序该 TCP 连接出问题了,于是客户端的 TCP 连接就会断开。
那 TCP 的数据报文具体重传几次呢?
在 Linux 系统中,提供了个叫 tcp_retries2 配置项,默认值是 15。
服务端主机宕机后,如果客户端一直不发数据
在服务端主机发送宕机后,如果客户端一直不发送数据,那么还得看是否开启了 TCP keepalive 机制 (TCP 保活机制)。
如果没有开启 TCP keepalive 机制,在服务端主机发送宕机后,如果客户端一直不发送数据,那么客户端的 TCP 连接将一直保持存在,所以我们可以得知一个点,在没有使用 TCP 保活机制,且双方不传输数据的情况下,一方的 TCP 连接处在 ESTABLISHED 状态时,并不代表另一方的 TCP 连接还一定是正常的。
而如果开启了 TCP keepalive 机制,在服务端主机发送宕机后,即使客户端一直不发送数据,在持续一段时间后,TCP 就会发送探测报文,探测服务端是否存活:
- 如果对端是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 如果对端主机崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
DNS缓存存在哪些问题?
- 缓存刷新不受控:当企业的域名发生变更时,并没有办法刷新全球各地的递归服务器缓存以及客户端上的DNS缓存,因此在每个缓存TTL值超时之前,客户发起请求仍然会按照缓存记录的原有映射关系发起请求,这就可能会出现站点不可达或者访问到错误的网站。只有等递归服务器和客户端上的DNS缓存失效后,才能重新发起请求,得到最新的映射关系。
HTTP怎么做断点续传
而所谓断点续传,也就是要从文件已经下载的地方开始继续下载。所以在客户端浏览器传给 Web 服务器的时候要多加一条信息 -- 从哪里开始。
请求包可以这样:
1 | |
QUIC协议
Quic 全称 quick udp internet connection [1],“快速 UDP 互联网连接”,(和英文 quick 谐音,简称“快”)是由 google 提出的使用 udp 进行多路并发传输的协议。
Quic 相比现在广泛应用的 http2+tcp+tls 协议有如下优势:
- 减少了 TCP 三次握手及 TLS 握手时间。
- 改进的拥塞控制。
- 避免队头阻塞的多路复用。
- 连接迁移。
- 前向冗余纠错。
0-RTT 握手
其实原理很简单:客户端缓存了 ServerConfig(B=b*G%P),下次建连直接使用缓存数据计算通信密钥:
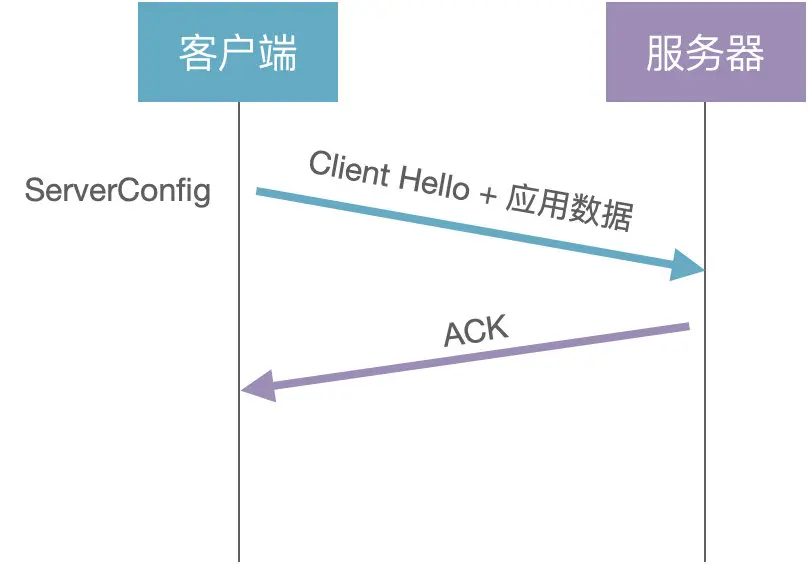
(1)客户端:生成随机数 c,选择公开的大数 G 和 P,计算 A=c * G % P,将 A 和 G 发送给服务器,也就是 Client Hello 消息
(2)客户端:客户端直接使用缓存的 ServerConfig 计算通信密钥 KEY = c * B = c * b * G%P,加密发送应用数据
(3)服务器:根据 Client Hello 消息计算通信密钥 KEY = bA = b c * G % P
也就是说,客户端不需要经过握手就可以发送应用数据,这就是 0-RTT 握手。再来思考一个问题:假设攻击者记录下所有的通信数据和公开参数(A1=a * G%P,A2=c * G%P,......),一旦服务器的随机数 b(私钥)泄漏了,那之前通信的所有数据就都可以破解了。
为了解决这个问题,需要为每次会话都创建一个新的通信密钥,来保证前向安全性
前向安全
前向安全:是指用来产生会话密钥的长期密钥泄露出去,不会泄漏以前的通讯内容。
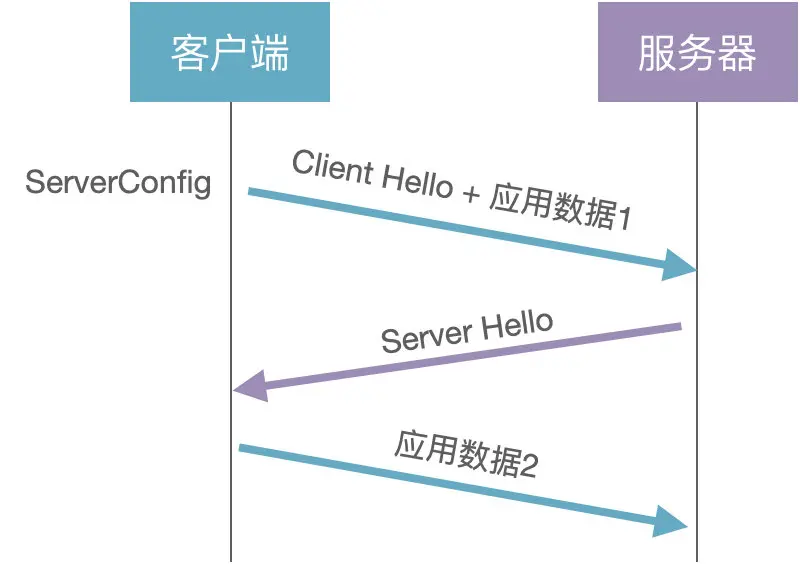
(1)客户端:生成随机数 a,选择公开的大数 G 和 P,计算 A=a*G%P,将 A 和 G 发送给服务器,也就是 Client Hello 消息
(2)客户端:客户端直接使用缓存的 ServerConfig 计算初始密钥 initKey = aB = ab*G%P,加密发送应用数据 1
(3)服务器:根据 Client Hello 消息计算初始密钥 initKey = b * A = b * a * G%P
(4)服务器:生成随机数 c,计算 C=c*G%P,使用 initKey 加密 C,发送给客户端,也就是 Server Hello 消息
(5)客户端:使用 initKey 解码获取 C,计算会话密钥 sessionKey = a * C = a * c * G%P,加密发送应用数据 2
(6)服务器:计算会话密钥 sessionKey = c * A = c * a*G%P,解密获取应用数据 2
客户端缓存的 ServerConfig 是服务器静态配置的,是可以长期使用的。客户端通过 ServerConfig 实现 0-RTT 握手,使用会话密钥 sessionKey 保证通信数据的前向安全。
可靠传输
QUIC 是基于 UDP 协议的,而 UDP 是不可靠传输协议,那 QUIC 是如何实现可靠传输的呢?
可靠传输有 2 个重要特点:
(1)完整性:发送端发出的数据包,接收端都能收到
(2)有序性:接收端能按序组装数据包,解码得到有效的数据
问题 1:发送端怎么知道发出的包是否被接收端收到了?
解决方案:通过包号(PKN)和确认应答(SACK)
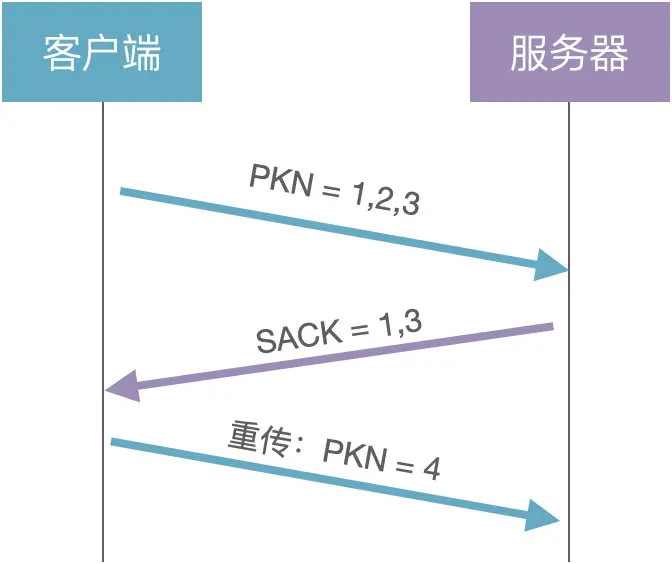
(1)客户端:发送 3 个数据包给服务器(PKN = 1,2,3)
(2)服务器:通过 SACK 告知客户端已经收到了 1 和 3,没有收到 2
(3)客户端:重传第 2 个数据包(PKN=4)
由此可以看出,QUIC 的数据包号是单调递增的。也就是说,之前发送的数据包(PKN=2)和重传的数据包(PKN=4),虽然数据一样,但包号不同。
问题 2:既然包号是单调递增的,那接收端怎么保证数据的有序性呢?
解决方案:通过数据偏移量 offset
每个数据包都有一个 offset 字段,表示在整个数据中的偏移量。
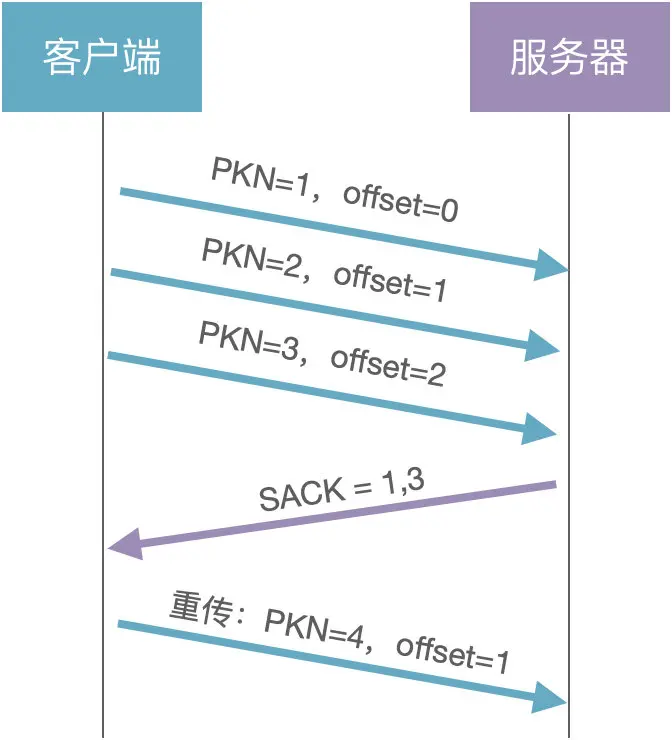
接收端根据 offset 字段就可以对异步到达的数据包进行排序了。为什么 QUIC 要将 PKN 设计为单调递增?解决 TCP 的重传歧义问题:
由于原始包和重传包的序列号是一样的,客户端不知道服务器返回的 ACK 包到底是原始包的,还是重传包的。但 QUIC 的原始包和重传包的序列号是不同的,也就可以判断 ACK 包的归属。
流量控制
和 TCP 一样,QUIC 也是利用滑动窗口机制实现流量控制,但是和 TCP 不同的是,QUIC 的滑动窗口分为 Connection 和 Stream 两种级别。Connection 流量控制:规定了所有数据流的总窗口大小;Stream 流量控制:规定了每个流的窗口大小。
假设现在有 3 个 Stream,滑动窗口分别如下:

则整个 Connection 的可用窗口大小为:20+30+10 = 60
拥塞控制
拥塞控制是通过拥塞窗口限制发送方的数据量,避免整个网络发生拥塞。那拥塞窗口(cwnd)和滑动窗口(发送窗口:swnd,接收窗口:rwnd)有什么关系呢?
swnd = min(cwnd,rwnd)
也就是说,发送窗口的大小是由接收窗口和拥塞窗口共同决定的。那拥塞窗口的大小是如何计算的?通过 4 个拥塞控制算法:慢启动、拥塞避免、拥塞发生、快速恢复
多路复用
多路复用是 HTTP/2 的主要特性之一。
概念:单条 TCP 连接上可以同时发送多个 HTTP 请求,解决了 HTTP1.1 中单个连接 1 次只能发送 1 个请求的性能瓶颈。HTTP/2 能实现多路复用的根本原因是采用了二进制帧格式的数据结构。
一个请求就对应一条流,通过 Stream ID 就可以判断该数据帧属于哪个请求,假设有 A 和 B 两个请求,对应的 Stream ID 分别为 1 和 2,那这个 TCP 连接上传输的数据大概如下:

HTTP/2 虽然通过多路复用解决了 HTTP 层的队头阻塞,但仍然存在 TCP 层的队头阻塞。那 QUIC 是如何解决 TCP 层的队头阻塞问题的呢?其实很简单,HTTP/2 之所以存在 TCP 层的队头阻塞,是因为所有请求流都共享一个滑动窗口,那如果给每个请求流都分配一个独立的滑动窗口,是不是就可以解决这个问题了?
QUIC 就是这么做的:
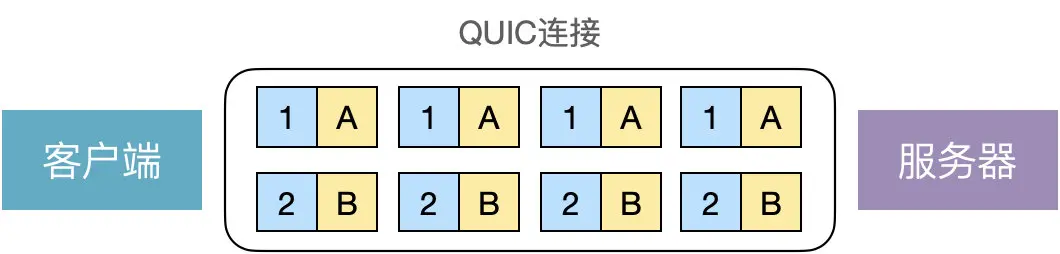
A 请求流上的丢包不会影响 B 请求流上的数据发送。但是,对于每个请求流而言,也是存在队头阻塞问题的,也就是说,虽然 QUIC 解决了 TCP 层的队头阻塞,但仍然存在单条流上的队头阻塞。这就是 QUIC 声明的无队头阻塞的多路复用。
连接迁移
连接迁移:当客户端切换网络时,和服务器的连接并不会断开,仍然可以正常通信,对于 TCP 协议而言,这是不可能做到的。因为 TCP 的连接基于 4 元组:源 IP、源端口、目的 IP、目的端口,只要其中 1 个发生变化,就需要重新建立连接。但 QUIC 的连接是基于 64 位的 Connection ID,网络切换并不会影响 Connection ID 的变化,连接在逻辑上仍然是通的。

假设客户端先使用 IP1 发送了 1 和 2 数据包,之后切换网络,IP 变更为 IP2,发送了 3 和 4 数据包,服务器根据数据包头部的 Connection ID 字段可以判断这 4 个包是来自于同一个客户端。QUIC 能实现连接迁移的根本原因是底层使用 UDP 协议就是面向无连接的。
socket服务端编程流程
- 客户端调用connect()函数,此时客户端会向服务端发送SYN
- 服务端收到SYN后,会从listen()函数返回SYN+ACK
- 客户端收到connect()函数的返回,之后向服务端发送最后一个ACK
- 服务端收到最后一个ACK以后,将该连接请求从未完成连接队列放入已完成连接队列中,等待accept()从该队列中取出
TCP连接复用
即多个客户端的HTTP请求复⽤到⼀个服务端的TCP连接上。具体做法如下:
采用TCP连接复用技术后,客户端(如:ClientA)与负载均衡设备之间进行三次握手并发送HTTP请求。负载均衡设备收到请求后,会检测服务器是否存在空闲的长连接,如果不存在,服务器将建立一个新连接。当HTTP请求响应完成后,客户端则与负载均衡设备协商关闭连接,而负载均衡则保持与服务器之间的这个连接。当有其它客户端(如:ClientB)需要发送HTTP请求时,负载均衡设备会直接向与服务器之间保持的这个空闲连接发送HTTP请求,避免了由于新建TCP连接造成的延时和服务器资源耗费。
TCP的MSS字段是在什么阶段协商的?
在TCP三次握手阶段,在TCP头部的选项里。
HTTPS有什么方法破解吗?
https安全通信分三个阶段:
1)认证服务器
2)交换加密key
3)https流量传输
如果想攻击https,可以分别从这三个阶段入手。
认证阶段—虚假证书欺骗
诱导用户安装根证书,一旦根证书(CA公钥)安装好,一个信任链就形成了,CA可以用自己的私钥给任何服务器签署证书,只要CA愿意。
举例:
一公司想监控用户的流量,包括https流量,只要预先给员工电脑里安装一个根证书,然后在公司网络出口有监控软件,有根证书的私钥。
当用户访问https服务器时,监控软件欺骗用户自己就是https服务器,与用户建立SSL连接。
然后监控软件再与真正的https服务器建立SSL连接。
用户与服务器的加密流量监控软件可以一览无余。
交换key阶段—攻击DH算法
采用超级计算机,离线计算DH算法素数对,经过常年累月的计算,形成一个庞大的素数对数据库,用这个数据库来比对捕获到的DH交换,一旦匹配到,用户的session key 就获得了,可以解密https流量。
斯诺登团队就是这么干的!
加密key暴力破解
目前加密算法使用AES256块式加密,如果不知道key,而使用暴力破解,理论上需要2^256 次才能破解,这个计算量是一个不可能完成的任务。
所以现实的做法是使用第一、第二种方法破解SSL流量。
Https只加密http报文,IP层完全是明文,所以谈不上任何的隐身。
Https安全注意事项
浏览器里的安全选项-SSL,只勾选TLS 1.2,其它统统不要。
不随意安装根证书,遇到可疑证书删掉为好!
DNS使用的是TCP还是UDP协议?
TCP和UDP。 DNS在进行区域传输的时候使用TCP协议,其它时候则使用UDP协议.
DNS的规范规定了2种类型的DNS服务器,一个叫主DNS服务器,一个叫辅助DNS服务器。
在一个区中主DNS服务器从自己本机的数据文件中读取该区的DNS数据信息,而辅助DNS服务器则从区的主DNS服务器中读取该区的DNS数据信息。当一个辅助DNS服务器启动时,它需要与主DNS服务器通信,并加载数据信息,这就叫做区域传输(zone transfer)。
为什么既使用TCP又使用UDP?
首先了解一下TCP与UDP传送字节的长度限制: UDP报文的最大长度为512字节,而TCP则允许报文长度超过512字节。当DNS查询超过512字节时,协议的TC标志出现删除标志,这时则使用TCP发送。通常传统的UDP报文一般不会大于512字节。 区域传送时使用TCP,主要有一下两点考虑:
- 辅助域名服务器会定时(一般是3小时)向主域名服务器进行查询以便了解数据是否有变动。如有变动,则会执行一次区域传送,进行数据同步。区域传送将使用TCP而不是UDP,因为数据同步传送的数据量比一个请求和应答的数据量要多得多。
- TCP是一种可靠的连接,保证了数据的准确性。
域名解析时使用UDP协议
客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可。不用经过TCP三次握手,这样DNS服务器负载更低,响应更快。
虽然从理论上说,客户端也可以指定向DNS服务器查询的时候使用TCP,但事实上,很多DNS服务器进行配置的时候,仅支持UDP查询包。
四次挥手的第二三次为什么不合并
- 服务器可能还有报文未发送
- ack和syn是不同时机触发的 ack是内核完成,会在收到fin的时候第一时间返回 而fin则是应用程序代码块控制,在调用到socket的close方法才会触发fin
Http想尽可能少的数据量发送
- 使用压缩:通过使用
gzip、brotli等压缩算法,服务器可以将响应体压缩后再发送给客户端。 - 使用 HTTP/2 或 HTTP/3:HTTP/2 和 HTTP/3 通过头部压缩(HPACK/ QPACK)可以显著减少重复的 HTTP 头部大小。
- 使用合适的 HTTP
方法:对于发送数据的场景,如果只需要传递少量数据或更新,可以选择
PATCH而非PUT,这样只需传输需要变更的部分数据,而不是整个资源。 - 利用缓存机制
知道哪些路由协议?
- RIP(Routing Information Protocol,路由信息协议)
- 版本:RIPv1 和 RIPv2
- 类型:距离矢量路由协议
- 度量值:跳数(最大15跳,16跳表示不可达)
- 特点:简单易用,适用于小型网络,但由于跳数限制和慢收敛性,不适合大规模网络。
- OSPF(Open Shortest Path First,开放最短路径优先)
- 类型:链路状态路由协议
- 度量值:带宽
- 特点:通过链路状态算法(Dijkstra算法)选择最短路径,支持区域划分,适用于中大型网络。OSPFv2支持IPv4,OSPFv3支持IPv6。
- EIGRP(Enhanced Interior Gateway Routing
Protocol,增强型内部网关路由协议)
- 类型:混合路由协议(既有距离矢量特性,也有链路状态特性)
- 度量值:带宽、延迟、负载和可靠性等
- 特点:快速收敛,支持不等价负载均衡,主要由Cisco设备支持。
- IS-IS(Intermediate System to Intermediate
System,中间系统到中间系统)
- 类型:链路状态路由协议
- 度量值:路径开销(Cost)
- 特点:类似于OSPF,但设计上更简洁,广泛用于运营商网络,支持大规模拓扑。
数据库
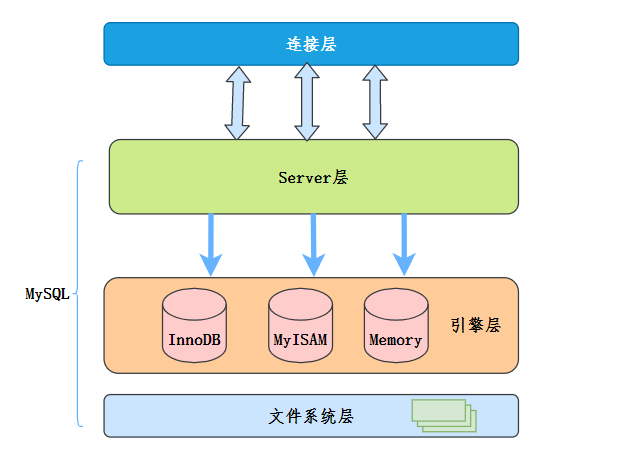
一条MySQL语句的执行过程(腾讯云)
连接器:连接器负责跟客户端建立 连接、获取权限、维持和管理连接。
查询缓存:MySQL拿到 个查询请求后,会先到查询缓存看看,之前是不是执 过这条语句。之前执 过的语句及其结果可能会以key-value对的形式,被直接缓存在内存中。
分析器:你输的是由多个字符串和空格组成的 条SQL语句,MySQL需要识别出的字符串分别是什么,代表什么。
优化器:优化器是在表有多个索引的时候,决定使哪个索引;或者在多个语句有多表关联(join)的时候,决定各个表的连接顺序。
执行器:MySQL通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进 了执器阶段,开始执行语句。
MySQL 中如果修改了⼀个 4kb 的⻚的内容,存⼊磁盘时修改的是完整的⻚还是⻚中的⼀段
在MySQL中,如果修改了一个4KB的页(Page)的内容,存入磁盘时通常是修改整个页而不是页中的一段。MySQL使用页作为存储数据的基本单位,通常是以固定大小的4KB为一页。当需要更新页中的数据时,MySQL通常会将整个页加载到内存中进行修改,然后再将整个页写回磁盘。
这样做的原因有几点:
- 简化管理:通过将整个页作为最小单位进行读取和写入,简化了数据管理和维护操作。
- 减少I/O开销:相比于仅写入一页中的一小部分数据,写入整个页可以减少磁盘I/O操作次数,提高性能。
- 保证数据一致性:通过整页写入,可以确保页的所有数据都是一致的,避免了部分数据更新而导致的数据不一致问题。
B树和B+树(腾讯云客户端)
LRU预读失效和缓存污染改进(腾讯云)
预读失效
什么是预读机制?
Linux 操作系统为基于 Page Cache 的读缓存机制提供预读机制,一个例子是:
- 应用程序只想读取磁盘上文件 A 的 offset 为 0-3KB 范围内的数据,由于磁盘的基本读写单位为 block(4KB),于是操作系统至少会读 0-4KB 的内容,这恰好可以在一个 page 中装下。
- 但是操作系统出于空间局部性原理(靠近当前被访问数据的数据,在未来很大概率会被访问到),会选择将磁盘块 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加载到内存,于是额外在内存中申请了 3 个 page;
预读失效会带来什么问题?
如果这些被提前加载进来的页,并没有被访问,相当于这个预读工作是白做了,这个就是预读失效。
解决方案
- Linux 操作系统和 MySQL Innodb 通过改进传统 LRU 链表来避免预读失效带来的影响,具体的改进分别如下:
- Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list);
- MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
Linux:
Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list)。
- active list活跃内存页链表,这里存放的是最近被访问过(活跃)的内存页;
- inactive list不活跃内存页链表,这里存放的是很少被访问(非活跃)的内存页;
有了这两个 LRU 链表后,预读页就只需要加入到 inactive list 区域的头部,当页被真正访问的时候,才将页插入 active list 的头部。如果预读的页一直没有被访问,就会从 inactive list 移除,这样就不会影响 active list 中的热点数据。
MySQL:
MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域,young 区域 和 old 区域。
young 区域在 LRU 链表的前半部分,old 区域则是在后半部分,这两个区域都有各自的头和尾节点,如下图:
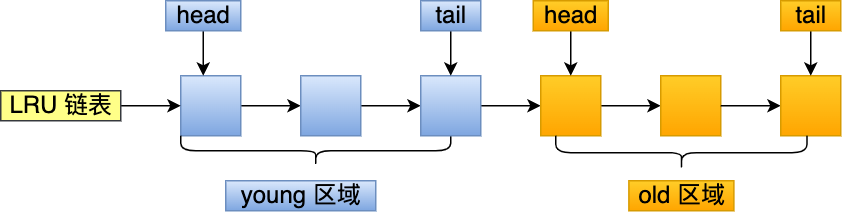
young 区域与 old 区域在 LRU 链表中的占比关系并不是一比一的关系,而是是 7 比 3 (默认比例)的关系。
划分这两个区域后,预读的页就只需要加入到 old 区域的头部,当页被真正访问的时候,才将页插入 young 区域的头部。如果预读的页一直没有被访问,就会从 old 区域移除,这样就不会影响 young 区域中的热点数据。
缓存污染
什么是缓存污染?
虽然 Linux (实现两个 LRU 链表)和 MySQL (划分两个区域)通过改进传统的 LRU 数据结构,避免了预读失效带来的影响。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
当我们在批量读取数据的时候,由于数据被访问了一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
解决方案
前面的 LRU 算法只要数据被访问一次,就将数据加入活跃 LRU 链表(或者 young 区域),这种 LRU 算法进入活跃 LRU 链表的门槛太低了!正式因为门槛太低,才导致在发生缓存污染的时候,很容就将原本在活跃 LRU 链表里的热点数据淘汰了。
所以,只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉。
Linux 操作系统和 MySQL Innodb 存储引擎分别是这样提高门槛的:
- Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
- MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
说说你了解的MVCC机制
- 事务ID:每个事务都有一个唯一的ID,用于标识事务的版本。
- 隐藏列:在支持MVCC的数据库表中,每行数据通常会有隐藏的列来存储事务ID和回滚指针。
- 回滚指针:指向该行数据的前一个版本,这样就形成了一个版本链。
- ReadView:在查询时,数据库会为事务创建一个ReadView,这是一个逻辑上的快照,包含了在查询时刻活跃的所有事务ID。
数据库是一阶段提交还是两阶段?为什么是两阶段?
数据库日志分为三种:
- undo log(回滚⽇志):是 Innodb 存储引擎层⽣成的⽇志,实现了事务中的原⼦性,主要⽤于事务回滚和MVCC。
- redo log(重做⽇志):是 Innodb 存储引擎层⽣成的⽇志,实现了事务中的持久性,主要⽤于掉电等故障恢复;
- binlog (归档⽇志):是 Server 层⽣成的⽇志,主要⽤于数据备份和主从复制;
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独⽴的逻辑,可能出现半成功的状态,造成两份⽇志之间的逻辑不⼀致。
- 如果在将 redo log 刷⼊到磁盘之后, MySQL 突然宕机了,⽽ binlog 还没有来得及写⼊。MySQL 重启后,通过 redo log 能将 Buffer Pool 恢复到新值,但是 binlog ⾥⾯没有记录这条更新语句,在主从架构中,binlog 会被复制到从库,由于 binlog 丢失了这条更新语句,从库的这⼀⾏是旧值,主从不⼀致。
- 如果在将 binlog 刷⼊到磁盘之后, MySQL 突然宕机了,⽽ redo log 还没有来得及写入。由于 redo log 还没写,崩溃恢复以后这个事务无效,数据是旧值,⽽ binlog ⾥⾯记录了这条更新语句,在主从架构中,binlog 会被复制到从库,从库执⾏了这条更新语句,这⼀行字段是新值,与主库的值不⼀致性。
所以会造成主从环境的数据不⼀致性。因为 redo log 影响主库的数据,binlog 影响从库的数据,redo log 和binlog 必须保持⼀致。
两阶段提交把单个事务的提交拆分成了 2 个阶段,分别是准备(Prepare)阶段和提交(Commit)阶段,每个阶段都由协调者(Coordinator)和参与者(Participant)共同完成。
两阶段提交的过程
在 MySQL 的 InnoDB 存储引擎中,开启 binlog 的情况下,MySQL 会同时维护 binlog ⽇志与 InnoDB 的 redo log,为了保证这两个⽇志的⼀致性,MySQL 使⽤了内部 XA 事务,内部 XA 事务由 binlog 作为协调者,存储引擎是参与者。
当客户端执⾏ commit 语句或者在⾃动提交的情况下,MySQL 内部开启⼀个 XA 事务,分两阶段来完成 XA 事务的提交。
事务的提交过程有两个阶段,将 redo log 的写⼊拆成了两个步骤:prepare 和 commit,中间再穿插写⼊binlog:
- prepare 阶段:将内部 XA 事务的 ID写⼊到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 持久化到磁盘。
- commit 阶段:把内部 XA 事务的 ID写⼊到 binlog,然后将 binlog 持久化到磁盘,接着调⽤引擎的提交事务接⼝,将 redo log 状态设置为 commit,此时该状态并不需要持久化到磁盘,只需要 write 到⽂件系统的page cache 成功,只要 binlog 写磁盘成功,redo log 的状态还是 prepare 也没有关系,⼀样会被认为事务已经执行成功。
MySQL调优
explain语句
EXPLAIN是MySQL中的一个关键字,用于分析查询语句的执行计划。通过EXPLAIN关键字,可以查看MySQL执行查询的方法和顺序,帮助优化查询性能。
使用EXPLAIN可以获取查询执行计划的相关信息,包括以下内容:
- type:显示查询使用了何种类型
- rows:预估搜索行数
- extra:
- using index:是否使用了覆盖索引
- using filesort:是否使用了外排序
- distinct:是否在select部分使用了distinc关键字
- Using index condition:使用索引下推
建立索引
- 为经常被查询的列建立索引,特别是在 WHERE 和 ORDER BY 子句中经常出现的列。
- 对于经常用于连接的列,考虑创建联合索引。
- 避免为稀疏列创建索引,因为这会增加索引维护的开销。
覆盖查询
尽量避免全表扫描,即使使用索引也需要访问数据行。如果查询只需要索引列的值,可以创建覆盖索引,这样就不需要额外访问数据行了,从而提高查询性能。
避免索引失效
见索引失效。
优化查询语句
- 使用 EXPLAIN 关键字分析查询执行计划,查看是否使用了索引,以及索引的选择器是否合理。
- 避免一次性返回大量数据,尽量限制查询返回的数据量。
- 使用合适的 JOIN 类型,避免不必要的笛卡尔积。
MySQL什么情况下不走索引
- 索引列参与表达式计算
- 索引列使用了函数
- 对索引隐式类型转换:如果索引字段是字符串类型,但是在条件查询中,输入的参数是整型的话,你会在执行计划的结果发现这条语句会走全表扫描。
- 不等号条件:当查询中包含不等号条件(<>)时。
- 表连接中的列类型不匹配: 如果在连接操作中涉及的两个表的列类型不匹配,索引可能会失效。例如, 一个表的列是整数,另一个表的列是字符,连接时可能会导致索引失效。
- 索引列使用了左右模糊匹配,
Like %xxx或者like %xx% - 字符串列与数字直接比较
- or条件:除非每个列都建立了索引才会走索引
- ORDER BY 操作:在ORDER BY操作中,排序的列同时也在WHERE中时,MYSQL将无法使用索引;
- 联合索引非最左匹配
- 使用了
select *
为什么要建立索引?索引为什么能够加快查询速度?
数据库索引能够加快查询的速度,主要是因为它提供了一种快速定位数据的方法,减少了数据库系统需要扫描的数据量。具体来说,数据库索引能够加快查询速度的原因包括以下几点:
- 减少数据扫描量:数据库索引可以将数据按照索引列的顺序进行组织,形成一种类似于字典的数据结构。当执行查询操作时,数据库系统可以利用索引快速定位到满足条件的记录,而不需要扫描整个表的数据。
- 快速定位数据:数据库索引通常采用树状结构(如B+树)或哈希表等高效的数据结构来组织索引数据,使得数据库系统能够以O(log n)或O(1)的时间复杂度快速定位到目标记录,而不受数据量的影响。
- 避免全表扫描:在没有索引的情况下,数据库系统可能需要对整个表进行扫描以寻找满足条件的记录,这样的全表扫描会消耗大量的时间和系统资源。而有了索引之后,数据库系统可以通过索引快速定位到符合条件的记录,避免了全表扫描,提高了查询效率。
- 支持排序和聚合操作:数据库索引不仅可以加速查询操作,还可以加速排序和聚合操作。例如,在有序索引的情况下,数据库系统可以利用索引的有序性进行高效的范围查询和排序操作;而在哈希索引的情况下,数据库系统可以利用哈希表的快速查找特性进行高效的聚合操作。
数据库的几大范式
数据库的三大范式(Normalization)是关系型数据库设计中的基本原则,旨在帮助设计者有效地组织数据库结构,减少数据冗余和插入、更新、删除异常,提高数据库的数据完整性和灵活性。三大范式包括:
- 第一范式(1NF):确保每个字段都是原子性的,即确保每个字段的值都是不可再分的基本单位,不包含多个值或重复的组合。换句话说,每个字段中不应该有多个值,而是单一的值。这样可以消除重复的数据,并确保每个字段具有唯一性和原子性。
- 第二范式(2NF):在满足第一范式的基础上,要求表中的非主键字段完全依赖于主键,而不是依赖于主键的一部分。简单来说,就是要保证表中的每个非主键字段都完全依赖于表的主键,而不是依赖于主键的某个子集。这样可以避免数据冗余和插入、更新、删除异常。
- 第三范式(3NF):在满足第二范式的基础上,要求表中的每个非主键字段之间不存在传递依赖关系。换句话说,就是要保证表中的每个非主键字段都直接依赖于主键,而不是依赖于其他非主键字段。这样可以进一步减少数据冗余,确保数据的更新操作不会导致数据不一致。
- BC范式(BCNF):在第三范式的基础上,如果关系模型R是第一范式,且每个属性都不传递依赖于R的候选键,那么称R为BCNF的模式。
- 第四范式(4NF):如果关系模式 R
中的每一个非平凡多值依赖 A ->> B 都满足以下条件之一,则关系模式 R
符合第四范式:
- A 是 R 的一个超码。
- B 是 R 的一个超码。
可重复读级别为什么还会有幻读
可重复读隔离级别通常只针对已有数据的读操作,而不是针对整个查询结果集的完整性。因此,如果其他事务在同一事务中执行了插入、删除等操作,可能会导致幻读的出现。
MySQL主从数据一致性怎么保持
- 异步复制:也是默认的主从同步方式。这种方式的优点是效率高。缺点是不能保证数据一定会到达slave。可能会受到网络等原因出现延迟,导致主从数据不一致。当前对master中的表进行数据操作,master将事务Binlog事件写入到Binlog文件中,此时主库只会通知一下Dump线程发送这些新的Binlog到slave(slave的 I/O 线程读取并将事件写入relay-log中)然后主库就会继续处理提交操作,而此时不会保证这些Binlog传到任何一个从库节点上。
- 全同步复制:优点是能够保证数据的强一致性,缺点是效率太低。当master上有提交事务之后,Dump线程发送这些新的Binlog到slave上,并且必须等待所有的slave回复成功(所有从库将事件写入中继日志,并将数据写入数据库)才能继续下一步操作。
- 半同步复制:优点是在耗费少量性能的基础上能在一定程度上保证数据的一致性。当master上有提交事务之后,Dump线程发送这些新的Binlog到slave上,并且必须等待其中一个slave回复成功(slave将事件写入relay-log)才能继续下一步操作。
乐观锁悲观锁使用场景
乐观锁:适用于读操作频繁、写操作少量的场景,如大部分情况下读操作不会被写操作影响的情况下。
悲观锁:适用于写操作频繁、读操作少量的场景,或者需要保证资源的排他性访问的场景。
数据库的四大隔离级别?分别是怎么实现的?
四大隔离级别
四大隔离级别:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
- 读未提交是指, 一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交是指, 一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读是指, 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
实现
- 对于「读未提交」隔离级别的事务来说,因为可以读到未提交事务修改的数据,所以直接读取最新的数据就好了;
- 对于「串行化」隔离级别的事务来说,通过加读写锁的方式来避免并行访问;
- 对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 **Read View * 来实现的,它们的区别在于创建 Read View 的时机不同,大家可以把 Read View 理解成一个数据快照,就像相机拍照那样,定格某一时刻的风景。**「读提交」隔离级别是在「每个语句执行前」都会重新生成一个 Read View,而「可重复读」隔离级别是「启动事务时」生成一个 Read View,然后整个事务期间都在用这个 Read View**。
四种隔离级别的应用场景?
- 读未提交:适用于对数据一致性要求不高的场景,例如读取非敏感信息的查询操作。
- 读已提交:适用于对数据一致性要求较高的场景,例如需要读取其他事务已提交的数据。
- 可重复读:适用于对数据一致性要求非常高的场景,例如订单处理、库存管理等需要保证数据一致性的操作。
- 串行化:适用于对数据一致性要求极高的场景,例如银行转账操作、库存扣减等需要严格保证数据一致性的操作。
什么是索引
在数据库中,索引是一种数据结构,用于提高数据的检索速度和查询效率。索引可以看作是数据库表中一个或多个列的快速查找表,类似于书籍的目录,它们帮助数据库系统快速定位和访问表中的特定数据行。
MySQL怎么避免回表
- 覆盖索引
- 索引下推
索引下推的原理
我们先简单了解一下MySQL大概的架构:
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。
索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
我们来具体看一下,在没有使用ICP的情况下,MySQL的查询:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给
Server层去检测该记录是否满足WHERE条件。
使用ICP的情况下,查询过程:
- 存储引擎读取索引记录(不是完整的行记录);
- 判断
WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录; - 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给
Server层,Server层检测该记录是否满足WHERE条件的其余部分。
MySQL的NULL值是怎么存储的
MySQL 的 Compact 行格式中会用「NULL值列表」来标记值为 NULL 的列,NULL 值并不会存储在行格式中的真实数据部分。
mysql查询优化
- 使用索引
- 覆盖索引
- 避免索引失效的情况
- 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能
- 尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
- 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率
SQL 分页查询如何实现?offset过大怎么优化
分页实际上就是从结果集中“截取”出第M~N条记录。这个查询可以通过LIMIT <N-M> OFFSET <M>子句实现。
例如,如果一页为3条数据,那么第一页就是
1 | |
第二页为:
1 | |
在MySQL中,LIMIT 15 OFFSET 30还可以简写成LIMIT 30, 15
offset过大怎么优化?
问题来了,limit 1451231,30 就会扫描145万行,然后丢掉前145万条只取30条,数据库压力能不大么,相对来说limit 30只会扫描30行,速度当然快。
子查询优化法 先找出第一条数据,然后大于等于这条数据的id就是要获取的数据 缺点:数据必须是连续的,可以说不能有where条件,where条件会筛选数据,导致数据失去连续性
倒排表优化法
倒排表法类似建立索引,用一张表来维护页数,然后通过高效的连接得到数据
缺点:只适合数据数固定的情况,数据不能删除,维护页表困难
反向查找优化法
当偏移超过一半记录数的时候,先用排序,这样偏移就反转了
缺点:order by优化比较麻烦,要增加索引,索引影响数据的修改效率,并且要知道总记录数 ,偏移大于数据的一半
limit限制优化法
把limit偏移量限制低于某个数。超过这个数等于没数据,我记得alibaba的dba说过他们是这样做的
数据库与缓存一致性问题
为什么B+数比红黑树更适合做索引数据结构
AVL 树(平衡二叉树)和红黑树(二叉查找树)基本都是存储在内存中才会使用的数据结构。
在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。
B+树的子节点大于红黑树,红黑树只能有2个子节点,B树子节点大于2,子节点数多这一特点保证了存储相同大小的数据,树的高度更小,数据局部更加紧凑,而硬盘读取有局部加载的优化
B+树所有数据都在叶子节点,更方便遍历,而红黑树遍历要用中序。
MySQL是什么隔离级别
MySQL是可重复读级别,但是它很⼤程度上可以避免幻读现象。解决的方案有两种:
- 针对快照读(普通 select 语句),是通过 MVCC ⽅式解决了幻读
- 针对当前读:(select ... for update 等语句),是通过 next-key lock(记录锁+间隙锁)⽅式解决了幻读,因为当执⾏ select ... for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插⼊。
表连接注意事项
- 应该用小表驱动大表
- 如果左表比较大,并且业务要求驱动表必须是左表,那么我们可以通过where条件语句,使得左表被过滤的小一些
- 关联字段给索引,因为在mysql的嵌套循环算法中,是通过关联字段进行关联,并查询的,所以给关联字段索引很必要
- 如果sql里面有排序,请给排序字段加上索引,不然会造成排序使用全表扫描;
- 能用inner join 就用 inner join
mysql 有哪些锁?
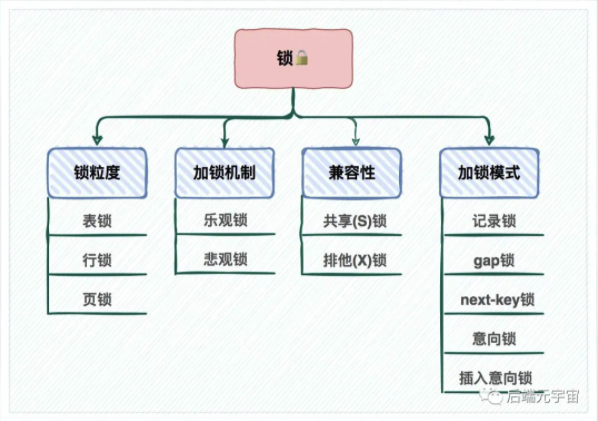
加锁模式
记录锁:用于锁一行,分为共享和排他。
意向锁:意向锁属于表级锁,其设计目的主要是为了在一个事务中揭示下一行将要被请求锁的类型。分为意向共享锁和意向排他锁。意向锁之间是相互兼容的,但是意向锁和普通锁之间是可以互斥的。
- 作用:如果另一个任务试图在该表级别上应用共享或排它锁,则受到由第一个任务控制的表级别意向锁的阻塞。第二个任务在锁定该表前不必检查各个页或行锁,而只需检查表上的意向锁。
间隙锁:间隙锁是一个在两个索引记录之间的间隙上的锁。不锁记录本身
临键锁:记录锁和间隙锁的结合,不仅锁了区间,也锁了记录本身,区间是左开右闭。
插入意向锁:间隙锁形式的意向锁,是一个间隙锁,行锁。当执行插入操作时,总会检查当前插入操作的下一条记录(已存在的主索引节点)上是否存在锁对象,判断是否锁住了 gap,如果锁住了,则判定和插入意向锁冲突,当前插入操作就需要等待,也就是配合上面的间隙锁或者临键锁一起防止了幻读操作。
自增锁:用于自增主键的锁,是一个表锁。
锁粒度
- 全局锁:通过flush tables with read lock 语句会将整个数据库就处于只读状态了,这时其他线程执行以下操作,增删改或者表结构修改都会阻塞。全局锁主要应用于做全库逻辑备份,这样在备份数据库期间,不会因为数据或表结构的更新,而出现备份文件的数据与预期的不一样。
- 表级锁:MySQL 里面表级别的锁有这几种:
- 表锁:通过lock tables 语句可以对表加表锁,表锁除了会限制别的线程的读写外,也会限制本线程接下来的读写操作。
- 自增锁:自增锁是一种比较特殊的表级锁。并且在事务向包含了
AUTO_INCREMENT列的表中新增数据时就会去持有自增锁。 - 意向锁:当执行插入、更新、删除操作,需要先对表加上「意向独占锁」,然后对该记录加独占锁。意向锁的目的是为了快速判断表里是否有记录被加锁。
- 行级锁:InnoDB 引擎是支持行级锁的,而 MyISAM
引擎并不支持行级锁。
- 记录锁,锁住的是一条记录。而且记录锁是有 S 锁和 X 锁之分的,满足读写互斥,写写互斥
- 间隙锁,只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
- Next-Key Lock 称为临键锁,是 Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
- 插入意向锁:插入意向锁是一种特殊的间隙锁 ——
间隙锁可以锁定开区间内的部分记录。
- 插入意向锁之间互不排斥,所以即使多个事务在同一区间插入多条记录,只要记录本身(主键、唯一索引)不冲突,那么事务之间就不会出现冲突等待。
一个事务里有特别多sql的弊端(即大事务的弊端)
大事务产生的原因
- 操作的数据比较多
- 大量的锁竞争
- 事务中有其他非DB的耗时操作
大事务造成的影响
- 并发情况下,数据库连接池容易被撑爆
- 锁定太多的数据,造成大量的阻塞和锁超时
- 执行时间长,容易造成主从延迟
- 回滚所需要的时间比较长
- undo log膨胀
MySQL是什么隔离级别?
MySQL是可重复读,但是在很大程度上解决了幻读,解决方案有两种:
- 针对快照读(普通 select 语句),是通过 MVCC ⽅式解决了幻读
- 针对当前读:(select ... for update 等语句),是通过 next-key lock(记录锁+间隙锁)⽅式解决了幻读,因为当执⾏ select ... for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入。
sql数据库如何解决死锁
- 设置合理的锁超时时间:当尝试获取锁超过设定的时间后,放弃锁请求,避免长时间等待导致死锁。
- 优化事务设计:尽量减小事务的大小和持续时间,减少锁的持有时间,从而降低死锁的风险。
- 使用低隔离级别:如果可能,使用较低的隔离级别,以减少锁的需求和冲突。
MVCC有什么用
MVCC(Multiple Version Concurrency Control)的主要作用是解决读-写和写-写冲突,使得大多数读操作不用加锁,从而提高了并发性能。通过保存数据的多个版本来实现并发访问,避免了读操作之间的锁竞争。
事务的原理
事务是并发控制的单位,是用户定义的一个操作序列。这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务通常是以BEGIN TRANSACTION开始,以COMMIT或ROLLBACK结束。COMMIT表示提交,即将事务中所有对数据库的更新写回到磁盘上的物理数据库中去,事务正常结束。ROLLBACK表示回滚,即在事务运行的过程中发生了某种故障,系统将事务中对数据库的所有已完成的操作全部撤消,滚回到事务开始的状态。
如果数据库短时间有大量数据存储,比如10分钟存50w条,该如何设计
读写分离
在绝大部分面向用户的系统中,都是读多写少的模型,比如电商,大部分的时候是在搜索和浏览,比如抖音,大部分是在加载短视频,所以我们需要考虑的问题是,数据库如何扛住查询请求。一般的解决方法是读写分离.
所谓读写分离,就是把同一个数据库分离成两份,一份专门用来做事务操作,另一份专门用来做读操作,如图。

做了主从复制之后,我们就可以在写入时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响到读请求的执行。同时呢,在读流量比较大的情况下,我们可以部署多个从库共同承担读流量,这就是所说的 一主多从 部署方式,在你的垂直电商项目中就可以通过这种方式来抵御较高的并发读流量。另外,从库也可以当成一个备库来使用,以避免主库故障导致数据丢失。
数据库主从不一致解决方案
方案一:忽略。
任何脱离业务的架构设计都是耍流氓,绝大部分业务,例如:百度搜索,淘宝订单,QQ消息,58帖子都允许短时间不一致。
画外音:如果业务能接受,最推崇此法。
如果业务能够接受,别把系统架构搞得太复杂。
方案二:放弃主从架构,强制读主。
(1)不采用读写主从架构,只使用一个高可用主库提供数据库服务;
(2)读和写都落到主库上;
(3)采用缓存来提升系统读性能 存储;
这是很常见的微服务架构,可以避免数据库主从一致性问题。
方案三:半同步复制
修改主库后至少同步修改完成一个从库,才返回请求,缓存每次都从那个同步更新的从库中读数据。
方案优点:利用数据库原生功能,比较简单
方案缺点:主库的写请求时延会增长,吞吐量会降低
K-V数据库
典型的代表就是Redis,也是目前业内非常主流的Nosql数据库。
之所以在IO性能方面比传统关系型数据库高,有两个点
- 数据基于内存,读写效率高
- KV型数据,时间复杂度为O(1),查询速度快
drop,delete,truncated的区别
数据恢复方面:delete 可以恢复删除的数据,而 truncate 和 drop 不能恢复删除的数据。
执行速度方面:drop > truncate > delete。
删除数据方面:drop 是删除整张表,包含行数据和字段、索引等数据,而 truncate 和 drop 只删除了行数据。
添加条件方面:delete 可以使用 where 表达式添加查询条件,而 truncate 和 drop 不能添加 where 查询条件。
重置自增列方面:在 InnoDB 引擎中,truncate 可以重置自增列,而 delete 不能重置自增列。
数据库插入大量数据怎么优化插入速度?
- 禁用索引:在插入数据前暂时禁用索引,数据插入完毕后再启用索引。可以通过
ALTER TABLE tb_name DISABLE KEYS;和ALTER TABLE tb_name ENABLE KEYS;来实现。 - 禁用唯一性检查:插入数据时,MySQL
会对插入的数据进行唯一性检查。这种唯一性检验会降低插入数据的速度。为了降低这种情况对查询速度的影响,可以在插入数据前禁用唯一性检查,等到插入数据完毕后在开启。语句为
SET UNIQUE_CHECKS=0;和SET UNIQUE_CHECKS=1; - 禁用外键检查
- 禁止自动提交:
SET AUTOCOMMIT=0;插入之后再设置SET AUTOCOMMIT=1; - 使用批量插入:
INSERT INTO items(name,city,price,number,picture) VALUES ('耐克运动鞋','广州',500,1000,'001.jpg'),('耐克运动鞋2','广州2',500,1000,'002.jpg');,这样比一句一句执行insert少了与数据库之间的连接等操作
一条update语句的执行流程
select语句的执行流程
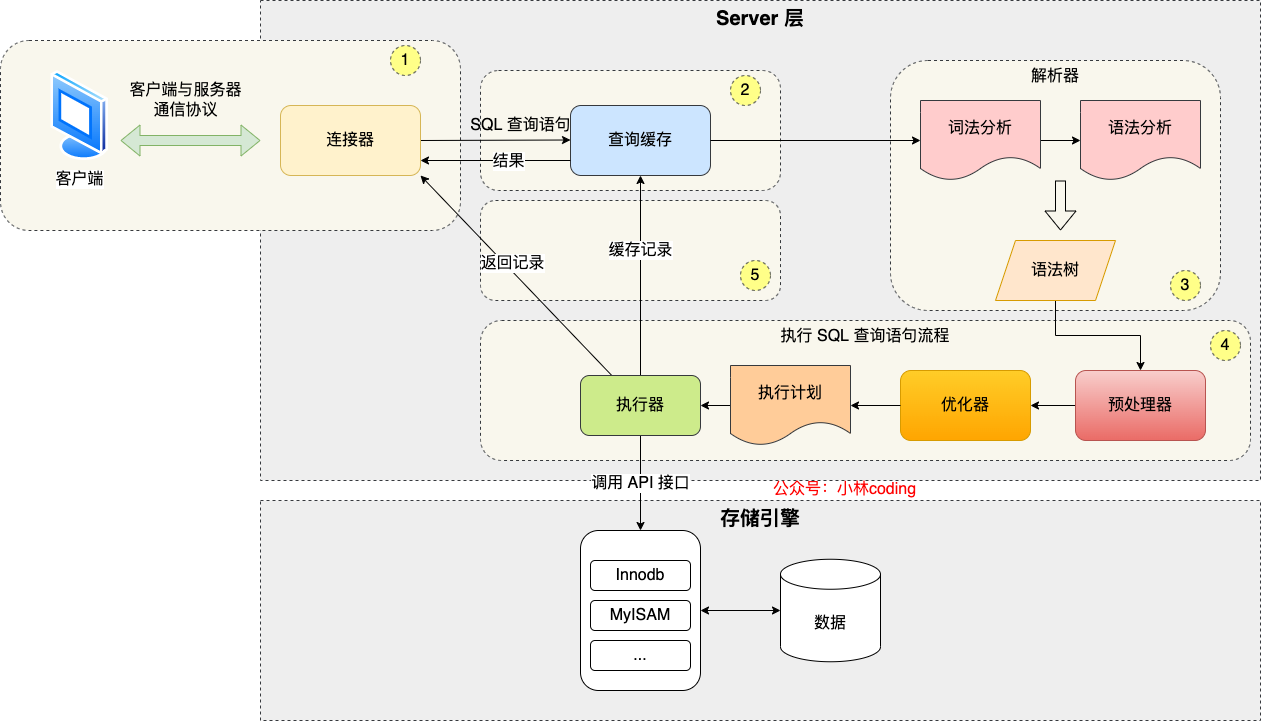
- 连接器:管理连接和权限验证
- 查询缓存:执⾏查询语句前,先看下查询缓存中是否有结果
- 解析器:解析SQL
- 执⾏SQL:
- 预处理:判断表和字段是否存在
- 优化:比如有多个索引的时候决定使用哪个索引?
- 执行
一条update语句的执行流程
select语句的流程要先走一遍,即:
- server层验证身份,然后到引擎层
- 调用存储引擎接口后,会先从Buffer Pool获取数据页,如果没有就从磁盘中读入Buffer Pool,然后判断更新前后的记录是否一样
- 开启事务,修改数据之前先记录undo log,写入Buffer Pool的undo page
- 开始更新page data中的记录,被修改的数据页称为脏页,修改会被记录到内存中的 redo log buffer中,再刷盘到磁盘的redo log文件,此时事务是 perpare阶段
- 这个时候更新就完成了,当时脏页不会立即写入磁盘,而是由后台线程完成,这里会用double write来保证脏页刷盘的可靠性
- 还没结束呢,这时候可以通知Server层,可以正式提交数据了, 执行器记录binlog cache,事务提交时才会将该事务中的binglog刷新到磁盘中
- 这个时候Update语句完成了Buffer Pool中数据页的修改、undo日志、redo log缓存记录,以及记录binlog cache缓存
- commit阶段,这个阶段是将redo log中事务状态标记为commit
- 此时binlog和redo log都已经写入磁盘,如果触发了刷新脏页的操作,先把脏页copy到double write buffer里,Double Write Buffer 的内存数据刷到磁盘中的共享表空间 ibdata,再刷到数据磁盘上数据文件 ibd
- 流程完结
高并发下库存超卖怎么解决?如何实现高并发?
综合使用数据库和Redis满足高并发扣减:
扣减库存其实包含两个过程:第一步是超卖校验,第二步是扣减数据的持久化;在传统数据库扣减中,两步是一起完成的。抗写的实现原理其实是巧妙的利用了分离的思想,分离开防超卖和数据持久化;首先防超卖是由Redis来完成的;通过Redis防超卖后,只要落库就可以;落库通过任务引擎,业务数据库使用商品分库分表,任务引擎任务通过单据号分库分表,热点商品的落库会被状态机分散开,消除热点。
第一关解决超卖检验:我们可以把数据放入Redis中,每次扣减库存,都对Redis中的数据进行incryby 扣减,如果返回的数量大于0,说明库存够,因为Redis是单线程,可以信任返回结果。第一关是Redis,可以抗高并发,性能Ok。超卖校验通过后,进入第二关。
第二关解决库存扣减:经过第一关后,第二关不需要再判断数量是否足够,只需要傻瓜扣减库存就行,对数据库执行如下语句,当然还是需要处理防重幂等的,不需要判断数量是否大于0了,扣减SQL只要如下写就可以。
要点:最终还是要使用数据库,热点怎么解决的呢?任务库使用订单号进行分库分表,这样针对同一个商品的不同订单会散列在任务库的不同库存,虽然还是数据库抗量,但已经消除了数据库热点。
Undo log、redo log、binlog是哪个层实现的?
- Redo Log 在引擎层实现,用来恢复数据的,保障已提交事务的持久化特性,记录的是物理级别的数据页(包括data page和undo page)做的修改
- Undo Log 在引擎层实现的逻辑日志,用于数据回滚到之前状态,对于每个UPDATE语句,对应一条相反的UPDATE的undo log
- BinLog 是Server实现的逻辑日志,用于复制和恢复数据,记录了所有的 DDL 和 DML 语句(除了数据查询语句select、show等)
如何排查慢查询
查看数据库服务慢查询日志是否开启:
1 | |
开启慢查询:
1 | |
查看并设置慢查询阈值(超过这个时间sql就会被记录在慢查询日志中)
1 | |
有两个索引,一个索引识别度高(例如唯一索引),另一个是普通索引,但是查询语句可能会选择普通索引,这是为什么?
- 统计信息:数据库优化器依赖于统计信息来决定使用哪个索引。如果普通索引的统计信息更加全面或更新,优化器可能会认为它更适合当前的查询。
- 索引覆盖:如果查询只需要索引中已有的列,优化器可能会选择那个能够“覆盖”查询的索引,即使它不是唯一索引。
- 查询条件:查询中使用的特定条件可能与普通索引更匹配,例如,如果查询涉及到索引的前缀或范围查询。
Mysql索引选择的策略
- 选择唯一性高的字段作为索引:唯一性高的字段可以更好地帮助MySQL快速定位到符合条件的数据行,从而减少全表扫描的时间。
- 尽量选择字段长度较小的字段作为索引:长度较小的字段在索引和查询时占用的空间更小,能够提高索引的效率。
- 考虑使用复合索引:复合索引是指同时对多个字段创建索引,可以提高查询效率。但是需要注意不要创建过多的复合索引,以免影响数据库性能。
- 避免在列上进行函数操作:在查询条件中尽量不要对字段进行函数操作,否则无法使用索引,导致查询性能下降。
mysql事务回滚原理
当一个事务被回滚时,MySQL会通过回滚日志中的记录来还原所有修改的数据,并删除日志文件中的相应记录。具体的原理是:MySQL会在undo表空间中创建一个临时表,用于存储需要回滚的数据,这些数据包括旧值、新值以及被修改的行的引用。然后,MySQL将在内存中读取回滚日志文件,以确定哪些操作需要回滚。一旦操作被确定,MySQL就会将这些操作的undo日志应用到undo表空间中的临时表中,并将被修改的行还原为之前的状态。
如何用mysql实现分布式锁 用伪代码+sql语句实现,输入一个字符串返回是否修改成功还是失败
在表中增加一个字段,利用update的记录锁和事务实现,先开启个事务,update状态代表持有锁,然后执行,最后状态修改回去
binlog的三种格式
MySQL 的 binlog(Binary Log)有三种常见的格式:
- STATEMENT(语句模式)
- 特点:记录每一条会导致数据更改的 SQL 语句。
- 优点:生成的日志文件较小,不会有太多的 I/O 开销。
- 缺点:某些复杂的 SQL 语句(如包含非确定性函数的语句)可能无法被精确复制。
- ROW(行模式)
- 特点:记录每一行的数据更改,而不是具体的 SQL 语句。
- 优点:能够精确地记录数据变化,尤其在复杂的 SQL 操作下效果更好。
- 缺点:日志文件较大,因为需要记录每行数据的变动情况。
- MIXED(混合模式)
- 特点:这是
STATEMENT和ROW模式的混合体。MySQL 会根据执行的 SQL 语句类型在两者之间切换。 - 优点:兼具
STATEMENT模式的节省日志大小的优点和ROW模式的精确性。 - 缺点:由于是混合模式,日志大小和性能可能会视具体使用场景有所不同。
- 特点:这是
通过设置 binlog_format
参数,可以在这三种模式之间进行切换。
为什么mysql使用B+树? 跳表不行吗? 不也可以一次加载大量磁盘数据进来吗?
- 跳表在内存中的结构可能导致较高的内存占用,因为它维护了多个层级的链表。
- 跳表在磁盘上的表现可能不如 B+ 树。B+ 树的节点大小可以优化以适应磁盘块的大小,而跳表的结构可能导致更高的磁盘I/O,因为它需要在多个链表中查找。
操作系统
用户态和内核态的互换、条件(腾讯云)
切换条件
从用户态到内核态切换可以通过三种方式,或者说会导致从用户态切换到内核态的操作:
- 系统调用,其实系统调用本身就是中断,但是软件中断,跟硬中断不同。系统调用机制是使用了操作系统为用户特别开放的一个中断来实现,如 Linux 的 int 80h 中断。
- 异常:如果当前进程运行在用户态,如果这个时候发生了异常事件,会触发由当前运行进程切换到处理此异常的内核相关进程中
- 外围设备中断:外围设备完成用户请求的操作之后,会向CPU发出中断信号,这时CPU会转去处理对应的中断处理程序。
切换过程
当发生用户态到内核态的切换时,会发生如下过程(本质上是从“用户程序”切换到“内核程序”)
- 设置处理器至内核态。
- 保存当前寄存器(栈指针、程序计数器、通用寄存器)。
- 将栈指针设置指向内核栈地址。
- 将程序计数器设置为一个事先约定的地址上,该地址上存放的是系统调用处理程序的起始地址。
而之后从内核态返回用户态时,又会进行类似的工作。
I/O 频繁发生内核态和用户态切换,怎么解决(腾讯云)
I/O会导致系统调用,从而导致内核态和用户态之间的切换。因为对I/O设备的操作是发生在内核态。那如何减少因为I/O导致的系统调用呢?
答案是:用户进程缓冲区。
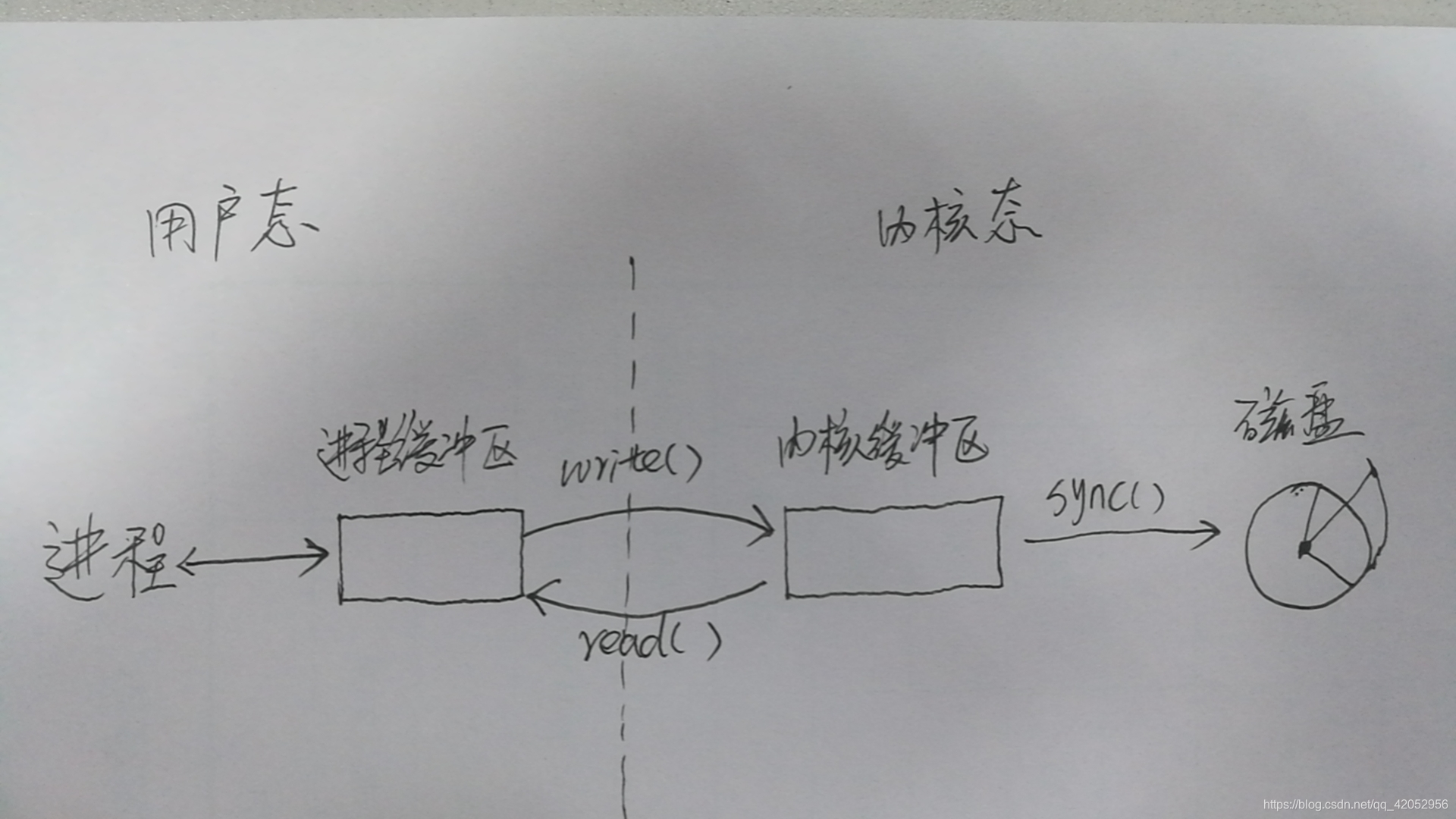
用户进程缓冲区:
程序在读取文件时,会先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。所以说:用户缓冲区的目的就是是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。除了在进程中设计缓冲区,内核也有自己的缓冲区。
内核缓存区:
当一个用户进程要从磁盘读取数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程缓冲区中。但若是内核缓冲区中没有数据,内核会把对数据块的请求,加入到请求队列,然后把进程挂起,为其它进程提供服务。等到数据已经读取到内核缓冲区时,把内核缓冲区中的数据读取到用户进程中,才会通知进程,当然不同的IO模型,在调度和使用内核缓冲区的方式上有所不同。
网卡收到一个包之后到用户读取这个包经历了多少次系统调用,有多少次拷贝操作
- 网络中断处理: 当网卡接收到数据包时,会触发网络中断,导致内核调用中断处理程序。这一步并不直接计算在系统调用的范畴内。
- 协议栈处理:
数据包会被传递给协议栈中的相应层(例如TCP/IP协议栈)。在这个过程中,内核可能执行一些系统调用来处理网络协议,如
ip_rcv和tcp_rcv等。 - 套接字缓冲区: 数据包被放置在套接字缓冲区中,等待应用程序读取。这一步可能涉及到一次数据拷贝,将数据从协议栈缓冲区拷贝到套接字缓冲区。
- 应用程序读取:
应用程序通过系统调用(例如
read或recv)从套接字缓冲区中读取数据。这一步可能涉及到一次数据拷贝,将数据从套接字缓冲区拷贝到用户空间缓冲区。
总的来说,通常情况下,至少有两次拷贝操作:一次是从协议栈缓冲区到套接字缓冲区,另一次是从套接字缓冲区到用户空间缓冲区。系统调用的次数会涉及到中断处理、协议栈处理和应用程序读取。每个系统调用都可能涉及到上下文切换和内核态与用户态之间的切换,这可能会引入一些额外的开销。
操作系统如何进行进程的上下文切换
- 保存当前进程状态: 当操作系统决定需要切换到另一个进程时,首先会保存当前进程的状态。这个状态通常包括 CPU 寄存器的内容(如程序计数器、栈指针、通用寄存器等)、进程控制块(PCB)中的进程信息(如进程 ID、进程状态、程序计数器等)以及其他可能的状态信息。
- 选择下一个进程: 操作系统根据调度算法从就绪队列中选择下一个要运行的进程。这个选择可以根据不同的调度算法进行,例如先来先服务(FCFS)、轮转法(Round Robin)、优先级调度等。
- 加载下一个进程状态: 一旦选择了下一个要运行的进程,操作系统就会从该进程的 PCB 中获取其状态信息。这些信息包括进程的程序计数器、栈指针、寄存器值等。然后,操作系统将这些状态加载到 CPU 中,准备开始执行该进程。
- 切换内存空间: 在多任务操作系统中,不同进程可能会运行在不同的内存空间中,因此在切换进程时,操作系统可能还需要执行内存空间的切换操作。这包括更新页表、切换地址空间等。
- 恢复运行: 最后,操作系统会将 CPU 控制权转移到新选择的进程,开始执行其代码。此时,该进程的状态被加载到 CPU 中,从之前保存的状态中恢复,并继续执行其上一次被暂停的位置。
线程崩溃进程会崩溃吗?
一般情况下,如果一个线程崩溃,那么整个进程很可能会崩溃。 这是因为线程之间共享地址空间,一个线程的崩溃可能导致内存的不确定性,进而影响到其他线程的执行。
遇到过死锁吗?怎么解决的,不要背那四条。
鸵鸟策略,遇到死锁的时候把进程kill掉。
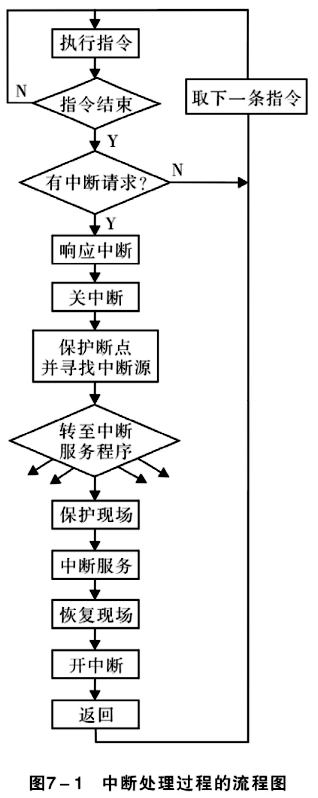
cpu中断后,进程的处理流程
当 CPU 接收到中断信号后,会暂停当前正在执行的进程,并执行中断处理程序。下面是 CPU 中断后进程的处理流程的一般步骤:
- 关中断。CPU关闭中断,即不再接受其他外部中断请求。
- 保存断点。将发生中断处的指令地址压入堆栈,以使中断处理完后能正确的返回(注意,有可能保存中断处的指令地址,也有可能是中断处的指令的下一条指令的地址,具体情况视中断的类型)。
- 识别中断源。CPU识别中断的来源,确定中断类型号,从而找到相应的中断处理程序的入口地址
- (以上三步一般由处理中断的硬件电路完成)保存现场。将发生中断处的有关寄存器(中断服务程序要使用的寄存器)以及标志寄存器的内容压入堆栈。
- 执行中断服务程序。转到中断服务程序入口开始执行,可在适时时刻重新开放中断,以便允许响应较高优先级的外部中断。
- (后三步一般由软件,即中断处理程序完成)恢复现场并返回。把“保护现场”时压入堆栈的信息弹回寄存器,然后执行中断返回指令,从而返回主程序继续运行。(IRET指令,无操作数,从栈顶弹出3个字,分别送入IP、CS和FLAGS寄存器)
说说你对信号量的理解
信号量是一种用于进程间同步和互斥的同步原语。它通常用于解决多个进程或线程之间共享资源的并发访问问题。信号量可以是计数器或标志,用于控制对临界区的访问。
在操作系统中,信号量通常分为两种类型:
- 二进制信号量(Binary Semaphore):也称为互斥锁,只能取两个值,通常为 0 或 1。它用于实现临界区的互斥访问,保证在同一时刻只有一个进程可以访问临界资源。
- 计数信号量(Counting Semaphore):可以取多个值,通常用于控制共享资源的访问数量。它允许多个进程同时访问临界资源,但是需要限制资源的数量。
信号量的基本操作包括:
- 初始化:创建信号量,并设置其初始值。
- P 操作(Wait 操作):尝试获取信号量资源,如果资源不可用,则进入等待状态,直到资源可用。如果是二进制信号量,P 操作会将信号量值减 1。
- V 操作(Signal 操作):释放信号量资源,如果有等待的进程,通知它们资源可用。如果是二进制信号量,V 操作会将信号量值加 1。
信号量的使用场景包括:
- 临界区的互斥访问:多个进程需要对临界资源进行互斥访问,防止竞争条件(Race Condition)的发生。
- 生产者消费者问题:多个生产者和消费者共享一个有限的缓冲区,需要控制缓冲区的访问数量。
- 读者写者问题:多个读者和写者共享一个数据资源,需要控制读写操作的并发访问。
说说你对虚拟内存的理解,尽可能多
虚拟内存是一种计算机操作系统的内存管理技术,它将物理内存(RAM)和磁盘存储结合起来,为每个进程提供了一个连续的、私有的地址空间。虚拟内存使得多个进程可以同时运行,并且可以让每个进程感觉自己拥有整个系统的内存空间。
以下是对虚拟内存的更详细理解:
- 地址映射:虚拟内存将进程中的逻辑地址(虚拟地址)映射到物理内存中的物理地址。这样,进程看到的地址空间是连续的,但实际上数据可能存储在物理内存中的不同位置,或者甚至存储在磁盘上。
- 页面:虚拟内存将地址空间分割成固定大小的页面(Page),通常为 4KB 或 8KB。物理内存也被分割成相同大小的页面。每个页面都有一个对应的页表(Page Table)记录它在物理内存中的位置。
- 页面置换:当物理内存不足以容纳所有进程的数据时,虚拟内存使用页面置换算法将一部分数据从物理内存中换出到磁盘上的交换空间(Swap Space),以释放物理内存供其他进程使用。常见的页面置换算法有最近最少使用(LRU)、先进先出(FIFO)等。
- 虚拟内存管理:虚拟内存管理包括地址映射、页面分配、页面置换等功能。操作系统负责管理虚拟内存的分配和释放,以及页面置换算法的选择和执行。
- 内存保护:虚拟内存可以为每个页面设置不同的访问权限,如读、写、执行等,以保护进程的内存安全。
- 内存共享:虚拟内存允许多个进程共享内存页面,这些页面可以映射到不同的进程地址空间中,实现共享数据或代码。
操作系统通过什么方式向用户提供系统调用
操作系统的主要功能是为管理硬件资源和为应用程序开发人员提供良好的环境,但是计算机系统的各种硬件资源是有限的,因此为了保证每一个进程都能安全的执行。处理器设有两种模式:“用户模式”与“内核模式”。一些容易发生安全问题的操作都被限制在只有内核模式下才可以执行,例如I/O操作,修改基址寄存器内容等。而连接用户模式和内核模式的接口称之为系统调用。
应用程序代码运行在用户模式下,当应用程序需要实现内核模式下的指令时,先向操作系统发送调用请求。操作系统收到请求后,执行系统调用接口,使处理器进入内核模式。当处理器处理完系统调用操作后,操作系统会让处理器返回用户模式,继续执行用户代码。
- 系统调用接口:
- 操作系统会提供一组系统调用接口,这些接口定义了用户程序可以调用的操作系统服务和功能。这些接口通常以函数的形式提供给用户空间的应用程序,用户程序可以通过调用这些函数来请求操作系统执行特定的任务,如文件操作、进程管理、网络通信等。
- 软中断或陷阱指令:
- 当用户程序调用系统调用接口时,通常会触发一个软中断(Software Interrupt)或者陷阱指令(Trap Instruction)。这些指令会使处理器从用户态切换到内核态,进入操作系统的执行环境。在这个过程中,操作系统会检测到这个中断或者陷阱,并根据用户请求执行相应的系统调用服务。
应用程序到磁盘读写完整流程
在Linux系统中,应用程序到磁盘的读写流程是一个复杂的过程,涉及多个系统层面的交互。以下是一个简化的描述:
- 应用程序发起读写请求:当应用程序需要读取或写入数据时,它会通过系统调用(如
read()或write())请求操作系统进行数据传输。 - 系统调用转换为内核操作:系统调用将用户空间的请求转换为内核空间的操作。在内核空间,数据会被写入到页缓存(PageCache)中,这是一种利用内存作为缓冲区的机制,可以提高数据访问速度。
- 页缓存和磁盘交互:如果是读操作,内核会检查页缓存中是否有请求的数据。如果没有,它会从磁盘读取数据并加载到页缓存中。如果是写操作,数据首先被写入页缓存,并标记为“脏”,之后在适当的时候由flusher线程写回磁盘。
- DMA控制器参与数据传输:为了减轻CPU的负担,直接内存访问(DMA)控制器会被用来在内存和磁盘之间传输数据,无需CPU的直接干预。
- 数据写入磁盘:最终,数据会被写入磁盘。这个过程可能是由flusher线程触发的,也可能是应用程序通过调用如
fsync()的系统调用显式请求的。
数据在操作系统中的存储形式
- 文件系统:操作系统通过文件系统管理数据的存储和组织。文件系统将数据以文件的形式存储在存储设备(如硬盘、固态硬盘等)上,并提供对这些文件的管理、访问和操作。
- 数据库:数据库系统是一种专门用于管理和组织数据的软件。数据库中的数据以表格的形式进行组织,可以使用结构化查询语言(SQL)等方式对数据进行查询、更新和操作。
- 内存:操作系统使用内存来存储正在运行的程序和它们所需的数据。内存是临时存储,当计算机关闭时,其中的数据通常会丢失。
- 缓存:为了提高数据访问的速度,操作系统通常会使用缓存来临时存储最近访问过的数据。缓存位于内存中,可以减少对存储设备的访问次数,加快数据的访问速度。
- 寄存器:寄存器是位于处理器内部的存储单元,用于暂存和处理指令和数据。寄存器的访问速度非常快,但容量较小,通常用于存储临时数据和处理器状态信息。
如何解决死锁
- 预防死锁:通过一次性分配所有资源、按序请求资源等方式来预防死锁的发生。
- 避免死锁:通过银行家算法等来判断并避免系统进入不安全状态,从而避免死锁。
- 检测与解除死锁:定期检测系统中是否发生死锁,一旦发生死锁,则采取解除死锁的措施。解除死锁通常涉及撤销一些进程,以便回收它们的资源,从而使得其他进程能够继续执行。
- 死锁定理:系统处于死锁的充分条件是:当且仅当次状态的进程-资源分配图是不可简化的。
软连接和硬链接的区别
物理实现:
- 软链接: 软链接是⼀个独⽴的⽂件,它包含了指向⽬标⽂件或⽬录的路径。软链接实际上是⼀个特殊的⽂件,其中包含有关⽬标⽂件的引⽤。
- 硬链接: 硬链接是⽬标⽂件的⼀个额外的⽬录项。⽬录项指向相同的物理数据块,实际上只是⽂件系统中的两个或多个⽬录项指向相同的inode。
链接的目标:
- 软链接: 软链接可以链接到⽂件或⽬录,甚⾄可以链接到不存在的⽂件。
- 硬链接: 硬链接只能链接到⽂件,⽽且必须是同⼀⽂件系统中的。
对链接的影响:
- 软链接: 如果原始⽂件被删除或移动,软链接仍然存在,但链接将失效。软链接可以跨⽂件系统,但如果⽬标⽂件被删除,软链接将成为坏链接(dangling link)。
- 硬链接: 删除或移动原始⽂件并不会影响硬链接,因为硬链接只是inode的另⼀个引⽤。只有当所有硬链接都被删除后,inode的数据块才会被释放。
创建方式:
- 软链接: 使⽤ln -s 命令创建软链接。例如, ln -s target_file link_name 。
- 硬链接: 使⽤ln 命令创建硬链接。例如, ln target_file link_name 。
链接数量:
- 软链接: 软链接只会增加⽬标⽂件的链接计数,⽽不会增加inode的链接计数。
- 硬链接: 硬链接会增加⽬标⽂件的链接计数,也会增加inode的链接计数。当链接计数为零时,⽂件系统才会释放相关的数据块。
64位和32位的区别及原理
我们通常说的64位技术是相对于32位而言的,这个位数指的是CPU GPRs(General-Purpose Registers,通用寄存器)的数据宽度为64位,64位指令集就是运行64位数据的指令,也就是说处理器一次可以运行64bit数据。
32位处理器一次只能处理32位,也就是4个字节的数据;而64位处理器一次就能处理64位,即8个字节的数据。如果将总长128位的指令分别按16位、32位、64位为单位进行编辑的话:32位的处理器需要4个指令,而64位处理器则只要两个指令。显然,在工作频率相同的情况下,64位处理器的处理速度比32位的更快。除了运算能力之外,与32位处理器相比,64位处理器的优势还体现在系统对内存的控制上。由于地址使用的是特殊的整数,而64位处理器的一个ALU(算术逻辑运算器)和寄存器可以处理更大的整数,也就是更大的地址。传统32位处理器的寻址空间最大为4GB,而64位的处理器在理论上则可以达到1800万个TB(1TB=1024GB)。
多进程和多线程如何选择?
- 需要频繁创建销毁的优先用线程(进程的创建和销毁开销过大)
- 需要进行大量计算的优先使用线程(CPU频繁切换)
不同进程通信方式的适用场景
- 管道:管道的通信方式效率低,不适合进程间频繁地交换数据。
- 消息队列:通信不及时,不适合比较大数据的传输
- 缺点:通信不及时,不适合比较大数据的传输,消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销。
- 优点:可以频繁地交换数据
- 共享内存
- 信号量:适用与不同进程之间的同步和互斥
- socket:常用于网络通信
守护进程的作用和原理
守护进程(Daemon)是在操作系统中运行的一种特殊类型的后台进程。它在系统启动时启动,并在系统关闭时终止,与用户交互的终端会话无关。守护进程通常在后台运行,不会与用户进行直接的交互,也不会被用户终止。
创建守护进程的三种方式:
- 使用nohup命令
- 使用fork()函数按步骤创建
- daemon() 函数直接创建守护进程
作用
提供服务:守护进程通常负责提供某种服务,例如:Web 服务器、数据库服务、打印服务等。
系统管理:守护进程可以执行系统管理任务,例如:日志记录、监控系统状态、自动备份等。
定时任务:守护进程可以定期执行某些任务,例如:定时清理临时文件、执行定时脚本等。
原理
- 创建子进程,父进程退出,在Linux中父进程先于子进程退出会造成子进程成为孤儿进程,而每当系统发现一个孤儿进程是,就会自动由1号进程(init)收养它,这样,原先的子进程就会变成init进程的子进
- 为了避免守护进程成为孤儿进程,需要使用setid创建一个新的会话,并担任该会话组的组长。从而让子进程摆脱原会话的控制,让进程摆脱原进程组的控制,让进程摆脱原控制终端的控制
那么,在创建守护进程时为什么要调用setsid函数呢?由于创建守护进程的第一步调用了fork函数来创建子进程,再将父进程退出。由于在调用了fork函数时,子进程全盘拷贝了父进程的会话期、进程组、控制终端等,虽然父进程退出了,但会话期、进程组、控制终端等并没有改变,因此,还还不是真正意义上的独立开来,而setsid函数能够使进程完全独立出来,从而摆脱其他进程的控制
文件系统
文件系统的基本数据单位是文件,它的目的是对磁盘上的文件进行组织管理,那组织的方式不同,就会形成不同的文件系统。
Linux 最经典的一句话是:「一切皆文件」,不仅普通的文件和目录,就连块设备、管道、socket 等,也都是统一交给文件系统管理的。
Linux 文件系统会为每个文件分配两个数据结构:索引节点(index node)和目录项(directory entry),它们主要用来记录文件的元信息和目录层次结构。
- 索引节点,也就是 inode,用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。
- 目录项,也就是 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。
由于索引节点唯一标识一个文件,而目录项记录着文件的名,所以目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个别字。比如,硬链接的实现就是多个目录项中的索引节点指向同一个文件。
注意,目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件。
目录项和目录是一个东西吗?
虽然名字很相近,但是它们不是一个东西,目录是个文件,持久化存储在磁盘,而目录项是内核一个数据结构,缓存在内存。
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了文件系统的效率。
注意,目录项这个数据结构不只是表示目录,也是可以表示文件的。
那文件数据是如何存储在磁盘的呢?
磁盘读写的最小单位是扇区,扇区的大小只有
512B
大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。
所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux
中的逻辑块大小为 4KB,也就是一次性读写 8
个扇区,这将大大提高了磁盘的读写的效率。
以上就是索引节点、目录项以及文件数据的关系,下面这个图就很好的展示了它们之间的关系:
索引节点是存储在硬盘上的数据,那么为了加速文件的访问,通常会把索引节点加载到内存中。
另外,磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
- 超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
- 索引节点区,用来存储索引节点;
- 数据块区,用来存储文件或目录数据;
我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的:
- 超级块:当文件系统挂载时进入内存;
- 索引节点区:当文件被访问时进入内存;
用户态和内核态之间通信方式
- sysctl
- sysfs
- netlink
- procfs(/proc)
页面置换算法
- OPT:标杆,实际上不能实现
- FIFO:先进先出,效果最差,有颠簸
- LRU:最近最久未使用,根据⻚⾯未被访问时⻓⽤升序列表将⻚⾯排列,每次将最久未被使⽤⻚⾯置换出去。
- LFU:最少频次使用,每次淘汰使用频次最少的页面
- Clock:时钟算法,为每个页面设置一个访问位,再将内存中的页面都通过链接指针链接成一个循环队列。
- 当需要淘汰一个页面时,只需检查页的访问位:如果是0,选择此页换出;如果是1,将它置0,暂不换出,继续检查下一个页面
- 改进的clock算法:除了设置访问位,还考虑到页面有没有被修改,同时设置(访问位,
标志位)。然后找到第一个(访问位, 标志位)为(0, 0)的位置。
- 第一轮:从当前位置开始扫描到第一个(0,0)的帧用于替换。本轮扫描不修改任何标志位
- 第二轮:若第一轮扫描失败,则重新扫描,查找第一个(0,1)的帧用于替换。本轮将所有扫描过的帧访问位设为0
- 第三轮:若第二轮扫描失败,则重新扫描,查找第一个(0,0)的帧用于替换。本轮扫描不修改任何标志位
- 第四轮:若第三轮扫描失败,则重新扫描,查找第一个(0,1)的帧用于替换
LRU-K算法和2Q算法
LRU-K算法
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下
(1). 数据第一次被访问,加入到访问历史列表;
(2). 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
(3). 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
(4). 缓存数据队列中被再次访问后,重新排序;
(5). 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
2Q算法
该算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:
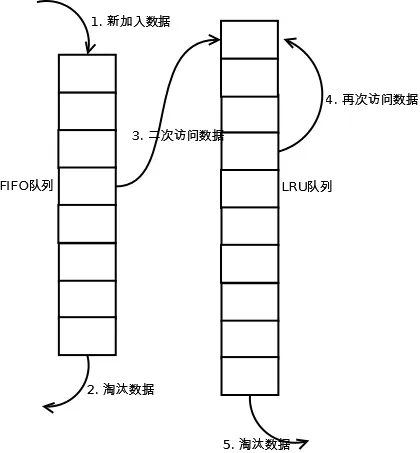
(1). 新访问的数据插入到FIFO队列;
(2). 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
(3). 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
(4). 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
(5). LRU队列淘汰末尾的数据。
虚拟内存
虚拟内存是一种扩展了物理内存的概念,它允许计算机将硬盘上的一部分空间作为虚拟内存,用于存储暂时不被使用的程序或数据。当程序需要更多内存空间时,虚拟内存会将不常用的数据暂时保存到硬盘上,从而释放出内存空间供其他程序使用。
虚拟内存的工作原理包括以下几个步骤:
- 地址映射: 操作系统将每个程序的内存地址映射到物理内存或虚拟内存中的某个位置。程序访问内存时,操作系统会根据映射关系将程序指令或数据加载到内存中。
- 页面置换: 当物理内存不足以容纳所有程序的数据时,操作系统会将不常用的页面(内存中的一段数据)转移到硬盘上的虚拟内存中,从而为其他程序释放出空间。这个过程称为页面置换,常用的置换算法包括最近最少使用(LRU)和先进先出(FIFO)等。
- 页面调度: 当程序需要访问虚拟内存中的数据时,操作系统会将所需的页面从硬盘上调入内存,并更新地址映射表,以便程序能够正确地访问数据。
虚拟内存的优点在于它可以扩展物理内存的容量,使计算机能够同时运行更多的程序,提高了系统的整体性能和稳定性。然而,虚拟内存也会带来一定的性能开销,因为数据需要在内存和硬盘之间频繁地传输。
内核里面有进程和线程的区分吗?
没有,在Linux 里面,无论是进程,还是线程,到了内核里面,我们统一都叫任务(Task),由一个统一的结构 task_struct 进行管理,这个task_struct 数据结构非常复杂,囊括了进程管理生命周期中的各种信息。

自旋锁的适用场景
因为自旋锁加锁失败不用阻塞,而是忙等,所以如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
操作系统读取文件的流程,拷贝的次数
步骤 1:系统调用
- 用户进程调用系统调用:用户进程通过调用类似
read()或fread()之类的系统调用来发起文件读取请求。 - 陷入内核:系统调用会触发上下文切换,用户态进入内核态。此时,操作系统将接管文件读取的工作。
步骤 2:文件系统处理
文件系统检查缓存
:内核会首先检查文件系统缓存(如页面缓存或缓冲区缓存),查看请求的文件内容是否已经存在于缓存中。
- 如果数据已经在缓存中(缓存命中),则直接从缓存中读取数据,跳过后续的磁盘读取。
- 如果缓存中没有所需的数据(缓存未命中),则需要从磁盘读取文件。
步骤 3:磁盘 I/O 操作
- 块设备驱动程序与磁盘通信:操作系统通过块设备驱动程序向磁盘发送读取请求。磁盘控制器会访问物理存储设备(如 HDD 或 SSD),并将所请求的块数据从磁盘读取到内存中(具体来说,是内核态的缓冲区或页面缓存中)。
步骤 4:内核处理数据
- 内核缓存数据:磁盘将数据读取到内核的缓冲区或页面缓存中。这些缓存数据暂存在内核空间中,供后续的文件读取使用。
步骤 5:用户进程读取数据
- 从内核拷贝到用户空间:一旦数据在内核态准备就绪,操作系统会将数据从内核态的缓存(页面缓存或缓冲区)拷贝到用户进程的缓冲区(即用户态内存中)。用户进程最终通过系统调用获取这些数据。
拷贝次数
如果缓存命中,只需要将数据从内核空间拷贝到用户空间。这是一个内核态到用户态的拷贝。所以只需要一次。
如果缓存没有命中,要将磁盘拷贝到内核缓冲区,然后再从内核缓冲区拷贝到用户缓冲区。所以需要两次。
进程fork读取的是一样的数据吗?
1. 内存数据
- 复制-on-write(写时复制):大多数现代操作系统使用
fork的“写时复制”机制来高效处理内存。在fork时,父进程和子进程共享相同的物理内存页面,但这些页面在被写入时才会被复制。这样,只有当其中一个进程修改内存中的数据时,操作系统才会为该进程复制相应的内存页面。这种机制减少了不必要的数据复制,提高了性能。 - 数据一致性:在
fork之后,父进程和子进程拥有相同的初始内存数据。任何对内存数据的修改,只会影响到当前进程的内存副本,不会影响另一个进程。即使在fork后,两个进程都可以访问相同的数据,但它们的修改不会相互影响。
2. 文件描述符
- 文件描述符的复制:在
fork时,父进程的所有文件描述符会被复制到子进程中。这意味着子进程和父进程可以共享打开的文件、管道、套接字等。它们共享相同的文件偏移量(如果是文件)和文件状态标志。因此,文件描述符的操作会对父进程和子进程产生影响,除非在fork后显式地关闭或修改这些描述符。
3. 资源
- 进程资源:除了内存数据,
fork还复制了其他资源,如进程的状态、优先级、信号处理器等。然而,进程间的资源(如 CPU 时间)和调度是独立的,不会直接影响对方。
4. 环境
- 环境变量和程序计数器:
fork创建的子进程继承了父进程的环境变量和程序计数器的状态。因此,子进程会从父进程的当前位置开始执行,并拥有相同的环境变量。
设计模式
面向对象设计的六大原则
- 单一职责(Single Responsibility Principle):一个类应该只负责一个职责,术语叫:仅有一个引起其变化的原因。
- 开闭原则(Open Close Principle):一个类一旦开发完成,后续增加新的功能就不应该通过修改这个类来完成,而是通过继承,增加新的类。
- 里氏替换原则(Liskov Substitution Principle):一个软件系统中所有用到一个类的地方都替换成其子类,系统应该仍然可以正常工作。
- 依赖倒置原则(Dependence Inversion
Principle):是指一种特定的解耦(传统的依赖关系建立在高层次上,而具体的策略设置则应用在低层次的模块上)形式,使得高层次的模块不依赖于低层次的模块的实现细节,依赖关系被颠倒(反转),从而使得低层次模块依赖于高层次模块的需求抽象。
- 高层次的模块不应该依赖于低层次的模块,两者都应该依赖于抽象接口。
- 抽象接口不应该依赖于具体实现。而具体实现则应该依赖于抽象接口。
- 接口隔离原则(Interface Segregation Principle, ISP):客户端不应该依赖它不需要的接口。
- 迪米特法则(Law of Demeter, LoD), 最少知识原则(Principle of Least Knowledge): 1. 每个对象应该对其他对象尽可能最少的知道 2. 每个对象应该仅和其朋友通信;不和陌生人通信 3. 仅仅和直接朋友通信
常见设计模式和使用场景、
设计模式分为三大类:创建型模式、结构型模式、行为型模式。
单例模式
一般使用于整个程序只需要一个类的实例,可以节省资源,并提供一个全局访问函数来访问该实例。
应用场景:
- 缓存
- 线程池
- ⽇志记录器
工厂模式
细分为简单工厂、工厂方法和抽象工厂。在创建对象时,不会对客户端暴露对象的创建逻辑,而是通过使⽤共同的接口来创建对象。其⽤来封装和管理类的创建,本质是对获取对象过程的抽象。
应用场景:
- 当⼀个类不知道它所需要的类的时候。
- 当⼀个类希望通过其子类来指定创建对象的时候。
- 当类将创建对象的职责委托给多个帮助⼦类中的某⼀个,并且希望将哪⼀个帮助⼦类是代理者的信息局部化时。
场景举例:
- 在数据库操作中,通过⼯⼚模式可以根据不同的数据库类型(MySQL、Oracle等)创建对应的数据库连接对象
- 通过⼯⼚模式可以根据配置⽂件或其他条件选择不同类型的⽇志记录器,如⽂件⽇志记录器、数据库⽇志记录器等。
- 在图形⽤户界⾯(GUI)库中,可以使⽤⼯⼚模式创建不同⻛格或主题的界⾯元素,如按钮、⽂本框等。
- 在加密算法库中,可以使⽤⼯⼚模式根据需要选择不同的加密算法,例如对称加密、⾮对称加密等。
- 在⽂件解析过程中,可以使⽤⼯⼚模式根据⽂件类型选择不同的解析器,如XML解析器、JSON解析器等。
- 在⽹络通信库中,可以使⽤⼯⼚模式创建不同类型的⽹络连接对象,如TCP连接、UDP连接等。
观察者模式
属于行为型模式的⼀种,它定义了⼀种⼀对多的依赖关系,让多个观察者对象同时监听某⼀个主题对象。这个主题对象在状态变化时,会通知所有的观察者对象,使他们能够自动更新自己。
使用场景:
- 事件处理:当⼀个对象的状态发⽣改变时,观察者模式可以⽤于通知和处理与该对象相关的事件。这在图形⽤户界⾯(GUI)开发中是很常⻅的,例如按钮点击事件、⿏标移动事件等。
- 发布订阅:观察者模式可以⽤于实现发布-订阅模型,其中⼀个主题(发布者)负责发送通知,⽽多个观察者(订阅者)监听并响应这些通知。这种模型在消息队列系统、事件总线等场景中经常使⽤。
- MVC架构:观察者模式常被⽤于实现MVC架构中的模型和视图之间的通信。当模型的状态发⽣改变时,所有相关的视图都会得到通知并更新显示。
- 异步编程:观察者模式可以⽤于处理异步任务的完成事件。任务完成时,通知所有相关的观察者进⾏后续处理。
代理模式
代理模式(Proxy Pattern)是⼀种结构型设计模式,其主要⽬的是在访问某个对象时引⼊⼀种代理对象,通过代理对象控制对原始对象的访问。代理模式可以⽤于实现懒加载、控制访问、监控对象等场景。
应用场景:
- 远程代理:⼀个对象在不同的地址空间提供局部代表。这样可以隐藏⼀个对象存在于不同地址空间的事实。
- 虚拟代理:根据需要创建开销很⼤的对象。通过它来存放实例化需要很⻓时间的真实对象,这样就可以达到性能的最优化。⽐如说你打开⼀个很⼤的HTML⽹⻚时,⾥⾯可能有很多的⽂字和图⽚,但你还是可以很快打开它,此时你所看到的是所有的⽂字,但图⽚却是⼀张⼀张地下载后才能看到。那些未打开的图片框,就是通过虚拟代理来替代了真实的图片,此时代理存储了真实图片的路径和尺⼨。
- 安全代理:⽤来控制真实对象访问时的权限。⼀般⽤于对象应该有不同的访问权限的时候。
- 智能指引:指当调⽤真实的对象时,代理处理另外⼀些事。如计算真实对象的引⽤次数,这样当该对象没有引⽤时,可以⾃动释放它;或当第⼀次引⽤⼀个持久对象时,将它装⼊内存;或在访问⼀个实际对象前,检查是否已经锁定它,以确保其他对象不能改变它。它们都是通过代理在访问⼀个对象时附加⼀些内务处理。
策略模式
策略模式(Strategy Pattern)是⼀种⾏为设计模式,它定义了⼀系列算法,,把它们单独封装起来,并且使它们可以互相替换,使得算法可以独⽴于使⽤它的客户端⽽变化,也是说这些算法所完成的功能类型是⼀样的,对外接⼝也是⼀样的,只是不同的策略为引起环境⻆⾊表现出不同的⾏为。
1 | |
装饰模式
装饰模式(Decorator Pattern)是⼀种结构型设计模式,它允许在不改变原始类接⼝的情况下,动态地添加功能或责任。装饰模式通过创建⼀个装饰类,包裹原始类的实例,并在保持原始类接⼝不变的情况下,提供额外的功能。就增加功能来说,装饰模式⽐⽣成⼦类更为灵活。
适配器模式
将⼀个类的接⼝转换成⽤户希望得到的另⼀个接⼝。它使原本不相容的接⼝得以协同⼯作——速记关键字:转换接⼝2。
单例模式实现的优点
- 因为单例模式在内存中就只有一个实例,其主要优点可以减少内存的开支。尤其是一个对象需要频繁地创建销毁时,毕竟创建或销毁时性能又无法优化, 那么单例模式就非常合适了;
- 因为单例模式只生成一个实例,所以,其主要优点可以减少系统的性能开销,当一个对象产生需要比较多的资源时,比如读取配置,产生其他依赖对象时,则可以通过在应用启动时直接产生一个单例对象,然后永久驻留内存的方式来解决;
- 同时单例模式可以避免对资源的多重占用,比如一个写文件操作,由于只有一个实例存在内存中,避免对同一个资源文件的同时写的操作;
- 单例模式可以在系统设置全局的访问点,优化和共享资源访问,可以设计一个单例类,负责所有数据表的映射处理等。
怎么提前销毁懒汉式局部静态变量?
三种工厂模式的区别
- 简单工厂模式只有一个抽象产品类,只有一个具体的工厂类。
- 工厂方法模式只有一个抽象产品类,而抽象工厂模式有多个抽象产品类。
- 工厂方法模式的具体工厂类只能创建一个具体产品类的实例,而抽象工厂模式可以创建多个具体产品类的实例。
使用工厂模式的好处?
可以将对象的创建和实现解耦。
总结
简单工厂模式:让一个工厂类负责创建所有对象;但没有考虑后期扩展和维护,修改违背开闭原则,静态方法不能被继承。
工厂方法模式:主要思想是继承,修改符合开闭原则;但每个工厂只能创建一种类型的产品。
抽象工厂模式:主要思想是组合,本质是产品族,实际包含了很多工厂方法,修改符合开闭原则;但只适用于增加同类工厂这种横向扩展需求,不适合新增功能方法这种纵向扩展。
Redis
常见的有五种数据结构:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
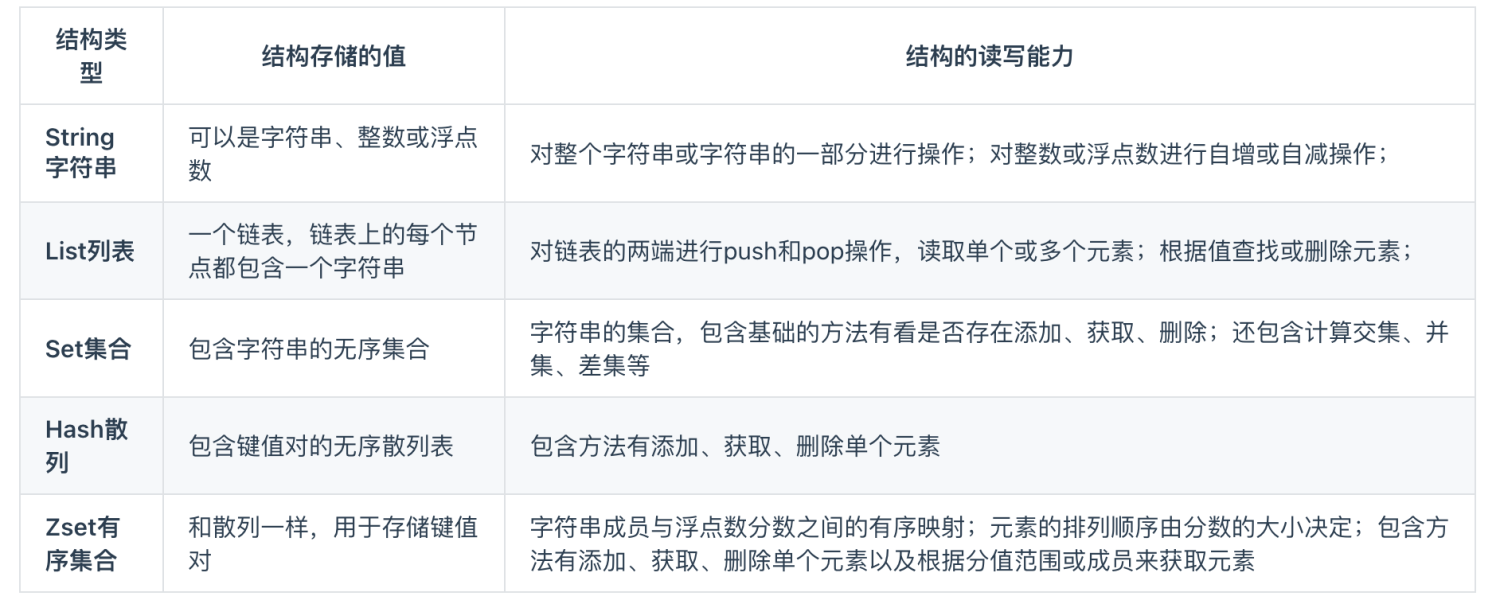
redis底层数据结构
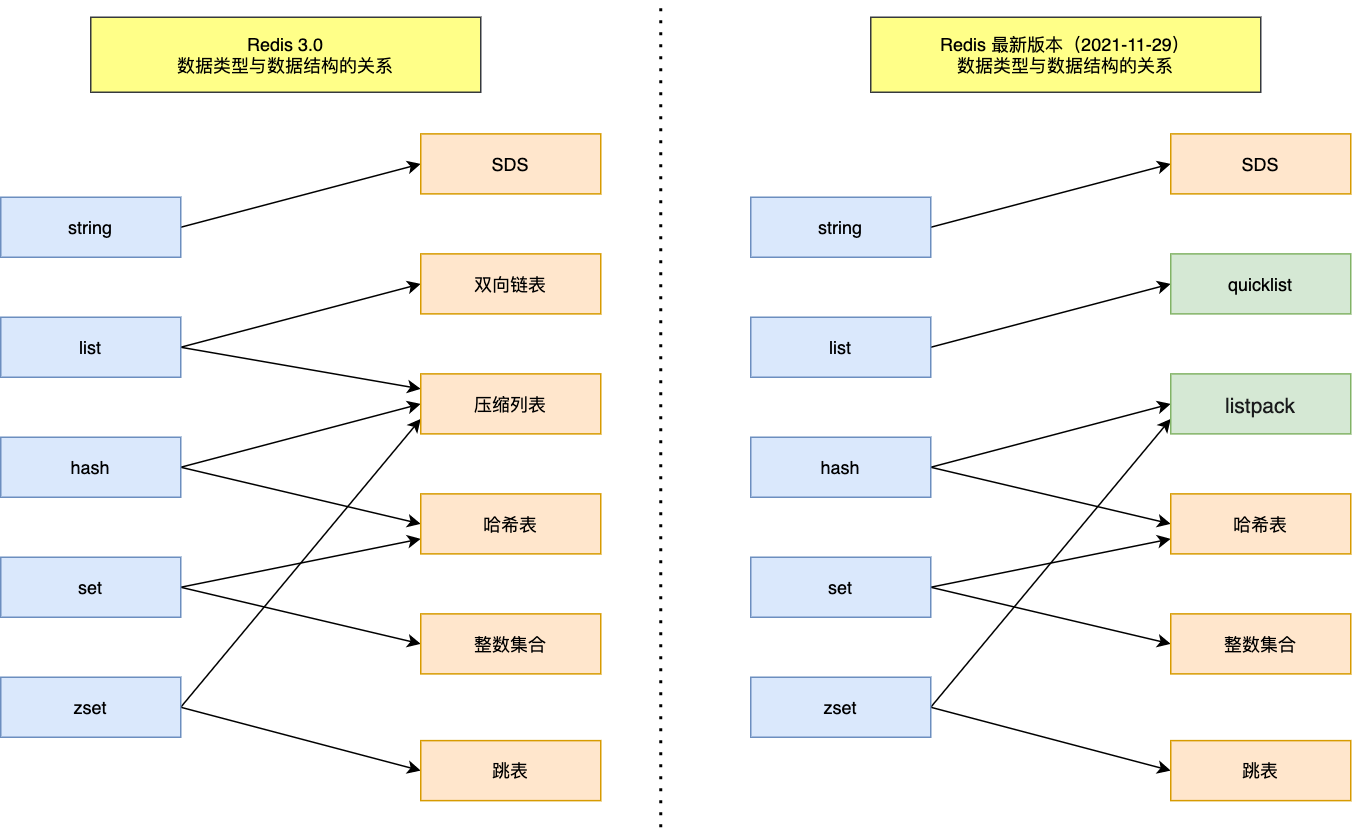
redis做缓存有哪些问题?如何解决?
从缓存穿透,缓存击穿,缓存雪崩,缓存⼀致性等⽅⾯来答。参考缓存雪崩、缓存穿透、缓存预热、缓存击穿、服务降级
跳表的插入与删除
插入
向一个跳跃表中插入元素可以分为三步:
- 找到各层的插入位置 。
和单链表一样,要插入一个元素,需要找到前驱节点。跳跃表是多层链表, 那么需要找到各层的前驱节点。
下图中,要插入一个新元素 20 ,其中数组 last[k] 表示找到的第 k 阶上的前驱节点。
找的方法和查找过程一样,只需要记住每一层可以向右考察到的最后一个节点即可。
- 决定新节点的阶 。
用上面提到的 随机函数 RandLevel 决定它的阶。 如果得到比整个跳跃表还要高的阶,需要把头节点的阶增高,与之对齐。 以便任何节点都可以从左上角的头节点出发找到。
由于 last 数组的含义是各层的插入位置,而且,接下来将要把头节点在新增高的这些层上指向新节点, 于是把头节点 head 记为 last 数组在这些层上的值。
下图中,假如生成了一个大的阶 4 ,那么跳跃表的阶将会增高到 4, 并设置 last[4] = head 。
- 各层执行插入动作 。
仍然和单链表一样,插入一个新节点的过程,就是把新节点和前驱、后驱节点分别搭线。 只不过跳跃表是在多层上进行。
在每一层,前驱节点 last[k] 指向新节点,新节点指向 last[k] 原来的后驱节点。
删除
同样地,从一个跳跃表中删除元素可以也可以分为三步:
- 找到各层的前驱节点和要删除的节点 。
从单链表中删除一个元素,需找到前驱节点。跳跃表是多层链表,也需找到各层的前驱节点。
和前面一样,last 数组来存放各层的前驱节点。 查找元素的过程,即可记录 last 数组。
同时查找结束后,亦可判断要删除的元素是否存在于表中。
下图以删除元素 22 为例:
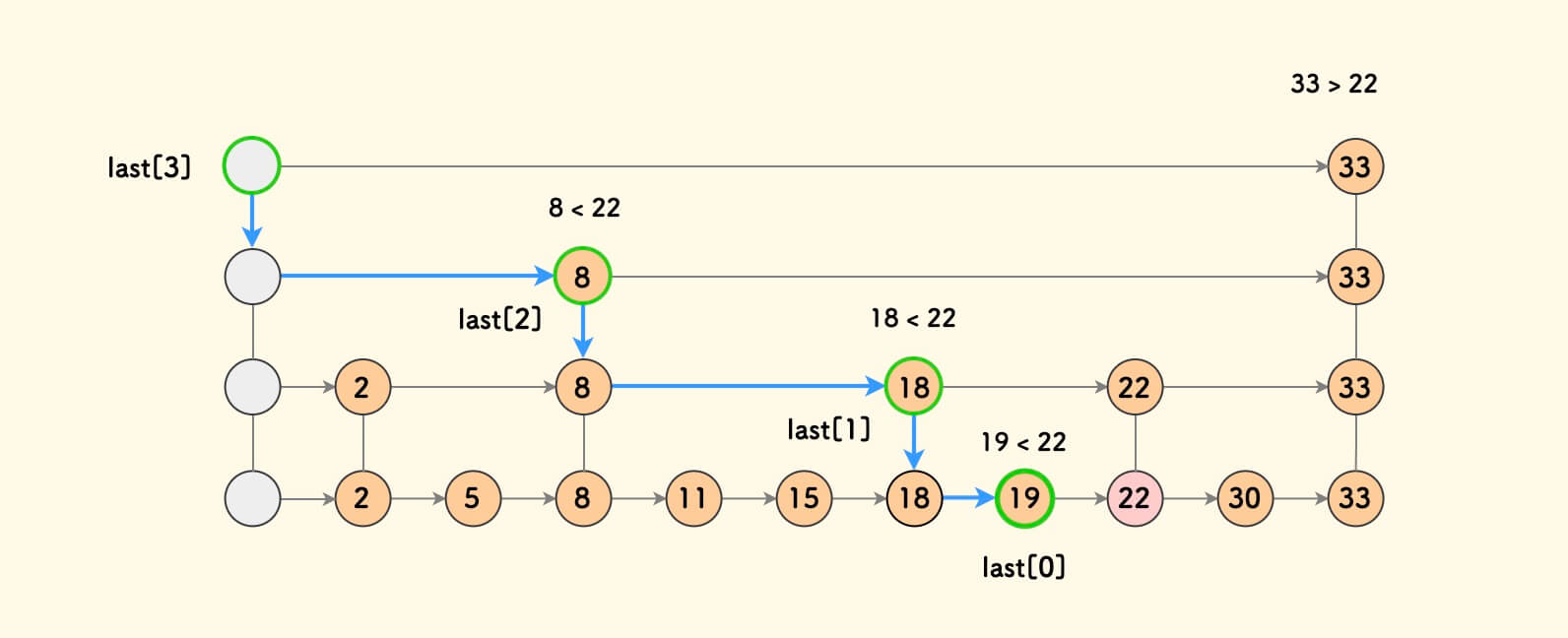
- 各层执行删除 。
仍然与单链表是类似。在各层上,前驱节点直接指向要删除的节点的后驱节点。 最终释放要删除的节点的内存即可。
不过,并非 last 数组的每一项都是待删除节点的前驱节点, 在删除时需要注意过滤。
以删除 22 为例,具体的删除动作就是,如果 last[k] 的后驱是 22, 则将 last[k] 的后驱指向 22 的后驱。
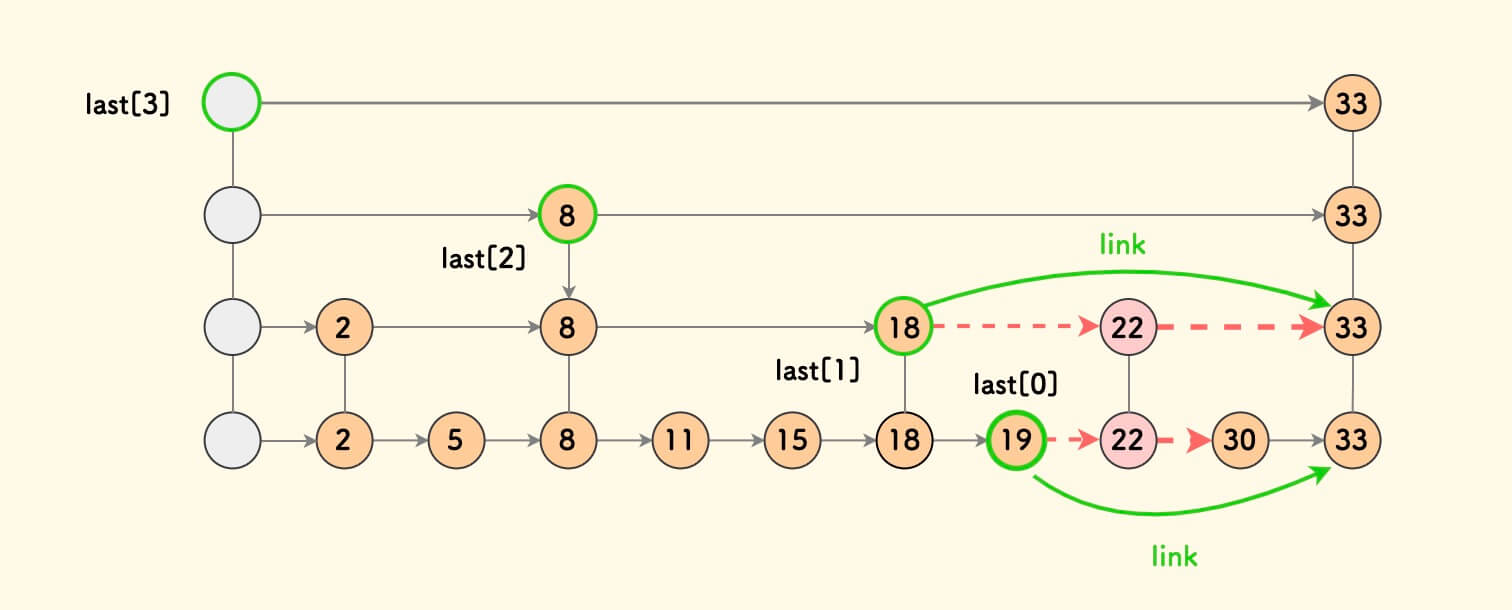
- 抹去删除节点后可能残留的孤零的高阶 。
如果删除的元素是一个高阶节点,可能让跳跃表的头节点残留下孤零零的高阶。
这一步是可选的,即使不清理也无大碍。
以删除高阶节点 33 为例,删除 33 后,头节点的阶可以由 4 降为 3 。
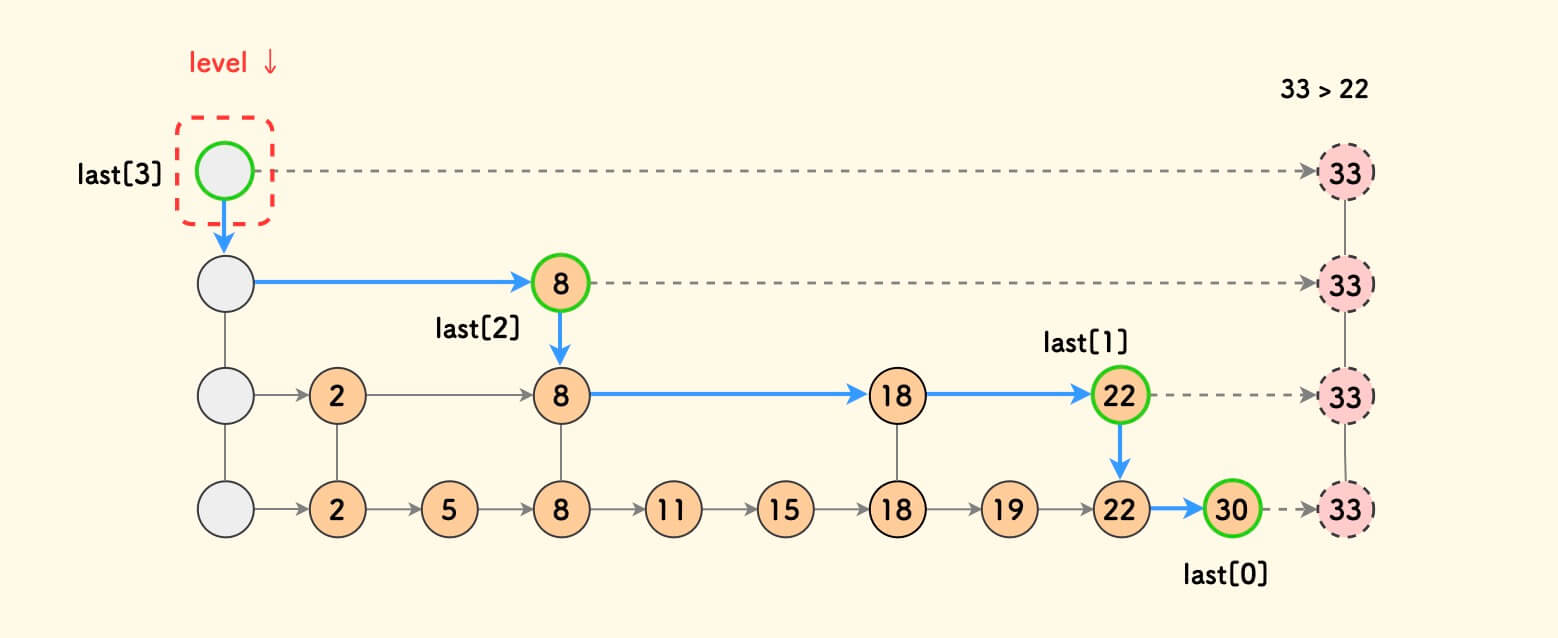
什么情况使用MySQL,什么情况使用Redis
Redis适合处理高性能读写、缓存、实时通信等场景,而MySQL适合存储和处理结构化数据、支持复杂查询和事务处理的场景。
redis的key会对应不同的数据结构,怎么知道一个key对应的是什么数据结构,怎么取对应的内存取值的呢?
在 Redis 的实现中,每个 key 的值(value)都被存储在一个
RedisObject
结构体中,这个结构体包含了值的数据类型和实际的数据结构指针。
RedisObject 结构体的定义大致如下:
1 | |
reids除了用setnx实现分布式锁还有其他方法吗?
使用 zset
ZSET 可以被用来实现分布式锁,特别适用于需要对锁进行排序或者有超时时间的场景。其基本原理是:
- 客户端尝试通过
ZADD命令将一个唯一标识插入到有序集合中,分值为当前时间加上锁的超时时间。 - 当客户端获取锁时,首先检查集合中的最小值,如果当前时间还未超过这个分值,说明锁已经被其他客户端持有;如果已经超时,则可以获取锁。
- 释放锁时,将该唯一标识从有序集合中删除。
这种方式的优点是能够实现更细粒度的锁控制,例如锁的过期排序、延迟执行等。
使用 Redis Bitmap 实现分布式锁
Bitmap 是 Redis 的一种特殊数据类型,可以用来高效地表示二进制状态(0 或 1),这种特性可以被用来实现锁。基本步骤是:
- 每个锁对应 Bitmap 中的一个位,当一个客户端想要获取锁时,它会将对应位设置为 1。
- 如果该位已经是 1,则表示锁已被持有;如果成功设置为 1,则表示锁获取成功。
- 释放锁时,将对应位设置为 0。
这种方式适合在高密度锁竞争的场景中使用,可以高效地管理大量锁。
redis的渐进式哈希?
Redis 的渐进式哈希(Incremental Rehashing)是为了解决哈希表在扩展或收缩过程中可能导致的阻塞问题而设计的机制。传统哈希表在进行重新哈希(rehashing)时,可能会一次性将所有元素从旧哈希表搬迁到新哈希表,这样会在数据量较大的情况下导致操作时间过长,从而阻塞 Redis 的服务。因此,Redis 采用了渐进式哈希来避免这种情况。
渐进式哈希的工作原理:
- 两个哈希表: Redis
哈希表扩展或收缩时,会临时维护两个哈希表:
ht[0]:当前正在使用的哈希表。ht[1]:新的哈希表,用于存放扩展后的数据。
- rehashidx 指针: Redis 不会一次性完成所有的 rehash
操作,而是将其分解为多次小的操作,每次执行少量的元素搬迁工作。Redis
通过一个名为
rehashidx的指针来记录 rehash 的进度,指向需要搬迁的槽位。每次 Redis 处理客户端请求时,都会顺便将ht[0]中部分槽位的数据搬迁到ht[1],直到整个 rehash 过程完成。 - 渐进搬迁:
- 每次渐进式 rehash 时,Redis 会把
ht[0]中的一个或多个槽的所有键值对搬迁到ht[1]。这种搬迁操作是在处理正常请求的过程中顺带进行的,因此 Redis 可以保持响应的流畅性,不会因为一次性 rehash 而长时间阻塞。
- 每次渐进式 rehash 时,Redis 会把
- rehash 触发条件:
渐进式哈希通常在以下几种情况下被触发:
- 当哈希表中的数据量超过一定的阈值时(负载因子过高)。
- 当哈希表中的数据量变少时,为了节省内存空间,哈希表会收缩。
- rehash 完成: 当
ht[0]中的所有数据都搬迁到ht[1]后,ht[0]将被释放,ht[1]变成新的哈希表,并且rehashidx指针被重置。此时,渐进式 rehash 完成。
渐进式哈希的优点
- 避免长时间阻塞: 传统的 rehash 需要一次性完成所有元素的搬迁操作,而 Redis 的渐进式哈希通过分批次完成搬迁,避免了 Redis 服务器的阻塞,保证了高效的响应。
- 平衡性能与内存: 渐进式哈希可以在数据逐渐增长的过程中进行哈希表扩展,确保哈希表的查询、插入等操作始终保持较高性能。
- 动态扩展和收缩: 渐进式哈希不仅在哈希表需要扩展时进行,在数据减少时也会自动收缩哈希表,优化内存使用。
Redis Object 结构
每个 Redis 数据类型都用一个 redisObject
结构来表示。该结构不仅包含实际的数据结构,还包含一些元信息,比如数据类型、引用计数和
LRU(Least Recently Used)时间戳等。其主要字段包括:
- type:表示对象的类型(字符串、列表、集合、哈希表或有序集合)。
- encoding:表示对象底层的数据结构(如
intset、ziplist、hashtable等)。 - lru:记录上次访问该对象的时间,用于 LRU 淘汰策略。
- refcount:引用计数,用于管理对象的生命周期。
- ptr:指向实际的数据结构的指针。
通过这些设计,Redis 能够在不同的使用场景下选择最适合的底层数据结构,以实现高效的存储和操作。
项目
RPC框架
介绍项目
从零实现了 net/rpc 框架,并在此基础上新增了协议交换、注册中心、服务发现、负载均衡、超时处理等功能,同时在Tcp基础之上实现了Http协议,使得框架可以同时处理传统rpc和http请求。
Q:协议交换是怎么实现的?
定义了一个接口,不同的编码格式通过实现这个接口,来实现这样不同的编码格式,然后在client的结构中有一个codec类型的变量用来标识使用哪个编码协议。
Q:为什么有了Tcp还要实现http?Tcp效率不是更高吗?
纯TCP协议的效率会高于HTTP协议。TCP是传输层协议,直接用于点对点的可靠数据传输,不涉及额外的开销。而HTTP则是应用层协议,基于TCP构建,但会增加额外的头部信息、状态管理等处理,这使得它在性能上稍微逊色一些。
不过,HTTP的优势在于它的通用性和普遍支持,特别是可以方便地通过防火墙和代理服务器,适用于广泛的网络环境。而纯TCP更适合内网高效通信,特别是在低延迟和高吞吐量的场景中。
Q:怎么实现http协议的?
Web 开发中,我们经常使用 HTTP 协议中的 HEAD、GET、POST 等方式发送请求,等待响应。但 RPC 的消息格式与标准的 HTTP 协议并不兼容,在这种情况下,就需要一个协议的转换过程。HTTP 协议的 CONNECT 方法恰好提供了这个能力,CONNECT 一般用于代理服务。
假设浏览器与服务器之间的 HTTPS 通信都是加密的,浏览器通过代理服务器发起 HTTPS 请求时,由于请求的站点地址和端口号都是加密保存在 HTTPS 请求报文头中的,代理服务器如何知道往哪里发送请求呢?为了解决这个问题,浏览器通过 HTTP 明文形式向代理服务器发送一个 CONNECT 请求告诉代理服务器目标地址和端口,代理服务器接收到这个请求后,会在对应端口与目标站点建立一个 TCP 连接,连接建立成功后返回 HTTP 200 状态码告诉浏览器与该站点的加密通道已经完成。接下来代理服务器仅需透传浏览器和服务器之间的加密数据包即可,代理服务器无需解析 HTTPS 报文。
举一个简单例子:
- 浏览器向代理服务器发送 CONNECT 请求。
1 | |
- 代理服务器返回 HTTP 200 状态码表示连接已经建立。
1 | |
- 之后浏览器和服务器开始 HTTPS 握手并交换加密数据,代理服务器只负责传输彼此的数据包,并不能读取具体数据内容(代理服务器也可以选择安装可信根证书解密 HTTPS 报文)。
Q:超时处理是怎么实现的呢?具体在哪实现了超时处理
超时处理是 RPC 框架一个比较基本的能力,如果缺少超时处理机制,无论是服务端还是客户端都容易因为网络或其他错误导致挂死,资源耗尽,这些问题的出现大大地降低了服务的可用性。因此,我们需要在 RPC 框架中加入超时处理的能力。
纵观整个远程调用的过程,需要客户端处理超时的地方有:
- 与服务端建立连接,导致的超时
- 发送请求到服务端,写报文导致的超时
- 等待服务端处理时,等待处理导致的超时(比如服务端已挂死,迟迟不响应)
- 从服务端接收响应时,读报文导致的超时
需要服务端处理超时的地方有:
- 读取客户端请求报文时,读报文导致的超时
- 发送响应报文时,写报文导致的超时
- 调用映射服务的方法时,处理报文导致的超时
GeeRPC 在 3 个地方添加了超时处理机制。分别是:
1)客户端创建连接时 2)客户端 Client.Call()
整个过程导致的超时(包含发送报文,等待处理,接收报文所有阶段)
3)服务端处理报文,即 Server.handleRequest 超时。
创建连接超时:
客户端连接超时,只需要为 Dial
添加一层超时处理的外壳即可。在这里实现了一个超时处理的外壳
dialTimeout,这个壳将 NewClient 作为入参,在 2
个地方添加了超时处理的机制。
- 将
net.Dial替换为net.DialTimeout,如果连接创建超时,将返回错误。 - 使用子协程执行 NewClient,执行完成后则通过信道 ch 发送结果,如果
time.After()信道先接收到消息,则说明 NewClient 执行超时,返回错误。怎么实现?(使用select语句)
关键代码:
1 | |
Client.Call 超时:
Client.Call 的超时处理机制,使用 context
包实现,控制权交给用户,控制更为灵活。
1 | |
用户可以使用 context.WithTimeout 创建具备超时检测能力的
context 对象来控制。例如:
1 | |
服务端处理超时:
这一部分的实现与客户端很接近,使用 time.After() 结合
select+chan 完成。
1 | |
这里需要确保 sendResponse
仅调用一次,因此将整个过程拆分为 called 和
sent 两个阶段,在这段代码中只会发生如下两种情况:
- called 信道接收到消息,代表处理没有超时,继续执行 sendResponse。
time.After()先于 called 接收到消息,说明处理已经超时,called 和 sent 都将被阻塞。在case <-time.After(timeout)处调用sendResponse。
Q:在实际应用中,超时处理对于网络情况的波动十分关键,怎么应对这种情况?
可以实现动态调整的机制,在系统中监控相关的响应时间和网络延迟等指标,然后根据监控的结果动态修改配置,比如如果超时频繁发生,可以考虑增加超时时间,或者考虑优化系统服务性能。
Q:实现了哪些负载均衡策略
random和roundroubin,通过设置了selectMode和discovery两个结构来实现负载均衡,同时在client的基础之上又封装了xclient来实现。
Q:了解过其他现有的rpc框架吗?
有了解过go标准库的rpc框架和grpc框架,grpc使用http2作为传输协议和双向流,序列化格式主要是protubuf,也可以使用其他格式。
协议:
- gRPC:使用HTTP/2作为传输协议,支持流式传输和双向流。序列化格式主要是Protobuf,也可以使用其他格式如JSON。
- Go标准库RPC:使用HTTP/1.1作为传输协议,序列化格式基于Go的内置编码机制(
encoding/gob)。
性能:
- gRPC:由于使用HTTP/2和Protobuf,gRPC在性能上通常优于Go标准库RPC。HTTP/2支持多路复用和压缩,Protobuf提供高效的序列化。
- Go标准库RPC:性能较为基础,适合轻量级应用,但可能在高负载下不如gRPC高效。
功能:
- gRPC:提供了丰富的功能,包括流式调用(单向、双向流)、超时处理、负载均衡、服务发现等。gRPC生态中也有很多工具支持,如负载均衡器和监控工具。
- Go标准库RPC:功能较为基础,主要支持基本的远程过程调用。需要额外实现复杂的功能,如流式传输或高级的负载均衡。
跨语言支持:
- gRPC:设计为支持多语言,gRPC的客户端和服务端可以用不同的编程语言实现,支持的语言包括Go、Java、Python、C++等。
- Go标准库RPC:主要是Go语言内部使用,虽然可以在不同Go程序之间使用,但不具备跨语言的支持。
生态和社区支持:
- gRPC:有广泛的社区支持和生态系统,包括多种客户端库、监控工具、服务发现组件等。
- Go标准库RPC:社区支持相对较少,主要依赖于Go语言自带的工具和库。
Q:怎么设计超时重试机制
Q:怎么避免超时重试
- 请求id(唯一标识符):客户端在每次请求时生成一个唯一的请求ID,确保每个请求都有一个独特的标识符。服务器在处理请求时,首先检查请求ID是否已经处理过。如果已经处理过,则直接返回之前的结果,而不重复执行请求。
- 幂等请求类型:对于某些类型的操作,可以明确设计为幂等的。例如,"写入相同的值"、"更新特定的状态"等请求,重复执行不会影响最终结果。
- 基于数据库的去重:在数据库操作中,可以利用数据库的唯一约束或乐观锁机制,防止重复的插入或更新。例如,通过请求ID设置数据库的唯一性约束,从而避免同一请求被重复处理。
- 请求结果缓存:服务器可以缓存最近处理过的请求ID及其对应的结果。如果再次收到相同请求,则直接返回缓存中的结果,而不重新处理。
客户端
muduo
服务器通信网络库重写并简化了muduo网络库,使用C++11去除了boost库的依赖,使用基于OOP思想,reactor模型。one loop per thread的模型,通过epoll + 线程池,使用多线程和事件循环机制实现高并发处理。
channel
Channel类其实相当于一个文件描述符的保姆,想要IO多路复用监听某个文件描述符,就要把这个fd和该fd感兴趣的事件通过epoll_ctl注册到IO多路复用模块(我管它叫事件监听器)上。当事件监听器监听到该fd发生了某个事件。事件监听器返回 [发生事件的fd集合]以及[每个fd都发生了什么事件].Channel类则封装了一个 [fd] 和这个 [fd感兴趣事件] 以及事件监听器监听到 [该fd实际发生的事件].
Poller
负责监听文件描述符事件是否触发以及返回发生事件的文件描述符以及具体事件的模块就是Poller。所以一个Poller对象对应一个事件监听器(这里我不确定要不要把Poller就当作事件监听器)。在multi-reactor模型中,有多少reactor就有多少Poller。(这个Poller是个抽象虚类,由EpollPoller和PollPoller继承实现)
epollfd_就是用epoll_create方法返回的epoll句柄,这个是常识。channels_:这个变量是std::unordered_map<int, Channel*>类型,负责记录 文件描述符 ---> Channel的映射,也帮忙保管所有注册在你这个Poller上的Channel。ownerLoop_:所属的EventLoop对象,看到后面你懂了。
EpollPoller给外部提供的最重要的方法:
1 | |
这个函数可以说是Poller的核心了,当外部调用poll方法的时候,该方法底层其实是通过epoll_wait获取这个事件监听器上发生事件的fd及其对应发生的事件,我们知道每个fd都是由一个Channel封装的,通过哈希表channels_可以根据fd找到封装这个fd的Channel。将事件监听器监听到该fd发生的事件写进这个Channel中的revents成员变量中。然后把这个Channel装进activeChannels中(它是一个vector<Channel*>)。这样,当外界调用完poll之后就能拿到事件监听器的监听结果(activeChannels_)
EventLoop
EventLoop就是负责实现“循环”,负责驱动“循环”的重要模块!!Channel和Poller其实相当于EventLoop的手下,EventLoop整合封装了二者并向上提供了更方便的接口来使用。
每个EventLoop对象都唯一绑定了一个线程,这个线程其实就在一直执行这个函数里面的while循环,这个while循环的大致逻辑比较简单。就是调用Poller::poll方法获取事件监听器上的监听结果。接下来在loop里面就会调用监听结果中每一个Channel的处理函数HandlerEvent( )。每一个Channel的处理函数会根据Channel类中封装的实际发生的事件,执行Channel类中封装的各事件处理函数。(比如一个Channel发生了可读事件,可写事件,则这个Channel的HandlerEvent( )就会调用提前注册在这个Channel的可读事件和可写事件处理函数,又比如另一个Channel只发生了可读事件,那么HandlerEvent( )就只会调用提前注册在这个Channel中的可读事件处理函数)
Acceptor: 接受新用户连接并分发连接给SubReactor(SubEventLoop)
TcpConnection类
主要封装了一个已建立的TCP连接,以及控制该TCP连接的方法(连接建立和关闭和销毁),以及该连接发生的各种事件(读/写/错误/连接)对应的处理函数,以及这个TCP连接的服务端和客户端的套接字地址信息等。
我个人觉得TcpConnection类和Acceptor类是兄弟关系,Acceptor用于main EventLoop中,对服务器监听套接字fd及其相关方法进行封装(监听、接受连接、分发连接给SubEventLoop等),TcpConnection用于SubEventLoop中,对连接套接字fd及其相关方法进行封装(读消息事件、发送消息事件、连接关闭事件、错误事件等)。
项目的流程
- 建立连接:创建
TcpServer对象,并在TcpServer的构造函数实例化了一个Acceptor对象,并往这个Acceptor对象注册了一个回调函数TcpServer::newConnection()。实例化Acceptor对象时,Acceptor的构造函数中实例化了一个Channel对象,即acceptChannel_,该Channel对象封装了服务器监听套接字文件描述符(尚未注册到main EventLoop的事件监听器上)。接着Acceptor构造函数将Acceptor::handleRead( )方法注册进acceptChannel_中,这也意味着,日后如果事件监听器监听到acceptChannel_发生可读事件,将会调用Acceptor::handleRead( )函数。当有连接到来的时候,会在Acceptor::handleRead( )中调用TcpServer::newConnection()将建立好的连接封装成TcpConnection对象然后发送到sub Eventloop上。 - 消息读取:sub eventloop和main
eventloop一样,也是用Poller调用poll函数获取事件监听结果,然后同样调用channel监听到的事件并调用提前注册好的事件处理函数。这里
readCallback_保存的函数其实是TcpConnection::handleRead( ),消息读取的处理逻辑也就是由这个函数提供的。函数首先调用Buffer_.readFd(channel_->fd(), &saveErrno),该函数底层调用linux的readv()将Tcp接收缓冲区数据拷贝到用户定义的缓冲区中(inputBuffer_)。如果在读取拷贝的过程中发生了什么错误,这个错误信息就会保存在savedErrno中。如果当readFd( )返回值大于0,说明从接收缓冲区中读取到了数据,那么会接着调用messageCallback_中保存的用户自定义的读取消息后的处理函数。 - 消息发送:
TcpConnection::send(buf)函数内部其实是调用了Linux的函数write( ),如果TCP发送缓冲区能一次性容纳buf,那这个write( )函数将buf全部拷贝到发送缓冲区中。如果TCP发送缓冲区内不能一次性容纳buf:- 这时候
write( )函数buf数据尽可能地拷贝到TCP发送缓冲区中,并且将errno设置为EWOULDBLOCK。 - 剩余未拷贝到TCP发送缓冲区中的
buf数据会被存放在TcpConnection::outputBuffer_中。并且向事件监听器上注册该TcpConnection::channel_的可写事件。 - 事件监听器监听到该Tcp连接可写事件,就会调用
TcpConnection::handleWrite( )函数把TcpConnection::outputBuffer_中剩余的数据发送出去。 - 在
TcpConnection::handleWrite( )函数中,通过调用Buffer::writeFd()函数将outputBuffer_的数据写入到Tcp发送缓冲区,如果Tcp发送缓冲区能容纳全部剩余的未发送数据,那最好不过了。如果Tcp发送缓冲区依旧没法容纳剩余的未发送数据,那就尽可能地将数据拷贝到Tcp发送缓冲区中,继续保持可写事件的监听。 - 当数据全部拷贝到Tcp发送缓冲区之后,就会调用用户自定义的【写完后的事件处理函数】,并且移除该TcpConnection在事件监听器上的可写事件。(移除可写事件是为了提高效率,不会让
epoll_wait()毫无意义的频繁触发可写事件。因为大多数时候是没有数据需要发送的,频繁触发可写事件但又没有数据可写。)
- 这时候
- 断开连接:
- 被动断开:服务端
TcpConnection::handleRead()中感知到客户端把连接断开了。TcpConnection::handleRead( )函数内部调用了Linux的函数readv( ),当readv( )返回0的时候,服务端就知道客户端断开连接了。然后就接着调用TcpConnection::handleClose( )。TcpServer::removeConnection( )函数调用了remvoveConnectionInLoop( )函数,把unordered_map中该tcpconnection的对象映射删除,该函数的运行是在MainEventLoop线程中执行的,这里涉及到线程切换。因为该函数主要是从TcpServer对象中删除某条数据。而TcpServer对象是属于MainEventLoop的。这也是贯彻了One Loop Per Thread的理念。TcpConnection::connectDestroyed( )函数的执行是又跳回到了subEventLoop线程中。该函数就是将Tcp连接的监听描述符从事件监听器中移除。另外SubEventLoop中的Poller类对象还保存着这条Tcp连接的channel_,所以调用channel_.remove( )将这个Tcp连接的channel对象从Poller内的数据结构中删除。 - 主动断开:服务器主动关闭时,调用
TcpServer::~TcpServer()析构函数。不断循环的让这个TcpConnection对象所属的SubEventLoop线程执行TcpConnection::connectDestroyed()函数,同时在MainEventLoop的TcpServer::~TcpServer()函数中调用item.second.reset()释放保管TcpConnection对象的共享智能指针,以达到释放TcpConnection对象的堆内存空间的目的。
- 被动断开:服务端
channel的生命周期
从Acceptor的构造函数开始被构造,然后在断开连接时候的TcpConnection::connectDestroyed( )中被删除。
TcpConnection的生命周期
连接到来的时候Acceptor::handleRead( )中调用TcpServer::newConnection()将建立好的连接封装成TcpConnection对象然后发送到sub
Eventloop上。在断开连接的时候TcpConnection::connectDestroyed执行完毕就销毁。详细看https://www.cnblogs.com/Qiu-Bai/p/17127757.html,之后再补充。
如果TcpConnection中有正在发送的数据,怎么保证在触发TcpConnection关闭机制后,能先让TcpConnection先把数据发送完再释放TcpConnection对象的资源?
TcpConnection类继承了enable_shared_from_this类,继承了这个类之后能使用shared_from_this()函数。假如我们在TcpConnection对象(我们管这个对象叫TCA)中的成员函数中调用了shared_from_this(),该函数可以返回一个shared_ptr,并且这个shared_ptr指向的对象是TCA。
接着这个shared_ptr就作为channel_的Channel::tie()函数的函数参数。
1 | |
当事件监听器返回监听结果,就要对每一个发生事件的channel对象调用他们的HandlerEvent()函数。在这个HandlerEvent函数中,会先把tie_这个weak_ptr提升为强共享智能指针。这个强共享智能指针会指向当前的TcpConnection对象。就算你外面调用删除析构了其他所有的指向该TcpConnection对象的智能指针。你只要HandleEventWithGuard()函数没执行完,你这个TcpConnetion对象都不会被析构释放堆内存。而HandleEventWithGuard()函数里面就有负责处理消息发送事件的逻辑。当HandleEventWithGuard()函数调用完毕,这个guard智能指针就会被释放。
buffer类
readv和writev允许单个系统调用读入到或写出自一个或多个缓冲区。
Buffer::readFd()函数剖析
这个readFd巧妙的设计,可以让用户一次性把所有TCP接收缓冲区的所有数据全部都读出来并放到用户自定义的缓冲区Buffer中。用户自定义缓冲区Buffer是有大小限制的,我们一开始不知道TCP接收缓冲区中的数据量有多少,如果一次性读出来会不会导致Buffer装不下而溢出。所以在readFd( )函数中会在栈上创建一个临时空间extrabuf,然后使用readv的分散读特性,将TCP缓冲区中的数据先拷贝到Buffer中,如果Buffer容量不够,就把剩余的数据都拷贝到extrabuf中,然后再调整Buffer的容量(动态扩容),再把extrabuf的数据拷贝到Buffer中。当这个函数结束后,extrabuf也会被释放。另外extrabuf是在栈上开辟的空间,速度比在堆上开辟还要快。
线程池的好处
线程池为避免频繁创建、销毁线程,提供一组子线程,能从工作队列取任务、执行任务,而用户可以向工作队列加入任务,从而完成用户任务。可以更加高效。
跳表和红黑树的优劣
红黑树
- 节点要么是黑色,要么是红色
- 根节点和叶子节点(NIL)都是黑色
- 每个红色结点的两个子结点一定都是黑色。
- 任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
- 从上一条可以推出,如果一个结点存在黑子结点,那么该结点肯定有两个子结点
为什么不使用红黑树
跳表和红黑树复杂度一样,但是并发环境下,红黑树在插入和删除的时候可能需要做一些rebalance的操作,这样的操作可能会涉及到整个树的其他部分,而skiplist的操作显然更加局部性一些,锁需要盯住的节点更少,因此在这样的情况下性能好一些。
reactor和proactor区别以及适用场景
Reactor 是非阻塞同步网络模式,而 Proactor 是异步网络模式。
- Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
- Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
内存池
内存缓存模块仿写了Google的tcmalloc,实现了高效的多线程内存管理,使用基于页面的内存分配机制,用于替换系统的内存分配相关函数 malloc 和 free、使用三层 Cache结构,Thread Cache:主要解决锁竞争的问题;Central Cache:主要负责居中调度的问题;Page Cache:主要负责提供以页为单位的大块内存;减少多线程场景下的锁竞争和系统开销,提高内存分配和释放的速度和效率。
span管理以页为单位的大内存块。
线程局部存储通过thread_local声明即可,例如int thread_ local errCode;
内存池的实现
该项目所使用的内存池原型是 Google 的开源项目 tcmalloc,其全称为 Thread-Caching Malloc,即线程缓存的 malloc,实现了高效的多线程内存管理,用于替换系统的内存分配相关函数,即 malloc 和 free。
内存池主要解决的就是效率问题,它能够避免让程序频繁的向系统申请和释放内存。其次,内存池作为系统的内存分配器,还需要尝试解决内存碎片的问题,内存碎片分为如下两种:
- 外部碎片:指的是空闲的小块内存区域,由于这些内存空间不连续,以至于合计的内存足够,但是不能满足一些内存分配的需求。
- 内部碎片:指的是由于一些对齐的需求,导致分配出去的空间中一些内存无法被充分利用。
内存池尝试解决的是外部碎片的问题,同时也尽可能的减少内部碎片的产生。
该内存池的整体架构如下图所示:
其主要由以下三个部分组成:
Thread Cache: 线程缓存是每个线程独有的,用于小于等于 256KB 的内存分配,每个线程独享一个 ThreaCache了。Central Cache: 中心缓存是所有线程共享的,当 ThreadCache 需要内存时会按需从 CentralCache 中获取内存,而当 ThreadCache 中的内存满足一定条件时,CentralCache 也会在合适的时机对其进行回收。Page Cache: 页缓存中存储的内存是以页为单位进行存储及分配的,当 CentralCache 需要内存时,PageCache 会分配出一定数量的页给 CentralCache,而当 CentralCache 中的内存满足一定条件时,PageCache 也会在合适的时机对其进行回收,并将回收的内存尽可能的进行合并,组成更大的连续内存块,缓解内存碎片的问题。
上述三个部分的主要作用如下:
- Thread Cache: 主要解决锁竞争的问题;
- Central Cache: 主要负责居中调度的问题;
- Page Cache: 主要负责提供以页为单位的大块内存;
1.ThreadCache
Thread Cache 的结构如下图所示:

通过使用字节对齐的方法来减少哈希桶的数目,并且进一步增加内存利用率,在设计时,让不同的范围的字节数按照不同的对齐数进行对齐,具体的对齐方式如下:
| 字节数 | 对齐数 | 哈希桶下标 | 自由链表数目 |
|---|---|---|---|
| [1, 128] | 8 | [0, 16) | 16 |
| [129, 1024] | 16 | [16, 72) | 56 |
| [1025, 8 * 1024] | 128 | [72, 128) | 56 |
| [8 * 1024+1, 64 * 1024] | 1024 | [128, 184) | 56 |
| [64 * 1024+1, 256 * 1024] | 8*1024 | [184, 208) | 24 |
为了实现每个线程无锁访问属于自己的 Thread Cache,就需要用到线程局部存储(Thread Local Storage, TLS),使用该存储方法的变量在它所在的线程是全局可访问的,但是不能被其它线程访问到,这样就保证了数据的线程独立性。
当某个线程申请的对象不用了,可以将其释放给 Thread Cache,然后 Thread Cache 将该对象插入到哈希桶的自由链表当中即可。
但是随着线程不断地释放,对应自由链表中的长度也会越来越长,这些内存堆积在一个 Thread Cache 中就是一种浪费,此时应该将这些内存还给 Central Cache,这样一来,这些内存对于其它线程来说就是可申请的,因此当 Thread Cache 中某个桶当中的自由链表太长时,可以将其释放给 Central Cache。
2. CentralCache
当线程申请某一大小的内存时,如果 Thread Cache 中对应的自由链表不为空,那么直接取出一个内存块返回即可,但如果此时该自由链表为空,那么这时 Thread Cache 就需要向 Central Cache 申请内存了。
Central Cache 的结构与 Thread Cache 是一样的,都是哈希桶结构,并且所遵循的对齐规则也一致。这样做的好处是当 Thread Cache 的某个桶中没有内存时,就可以直接到 Central Cache 中相对应的哈希桶中取内存。
Central Cache 与 Thread Cache 不同之处有两点:
- Central Cache 是所有线程共享的,而 Thread Cache 是线程独享的;
- Central Cache 的哈希桶中挂载的是 Span,而 Thread Cache 的哈希桶中挂载的是切好的内存块;
其结构如下所示:
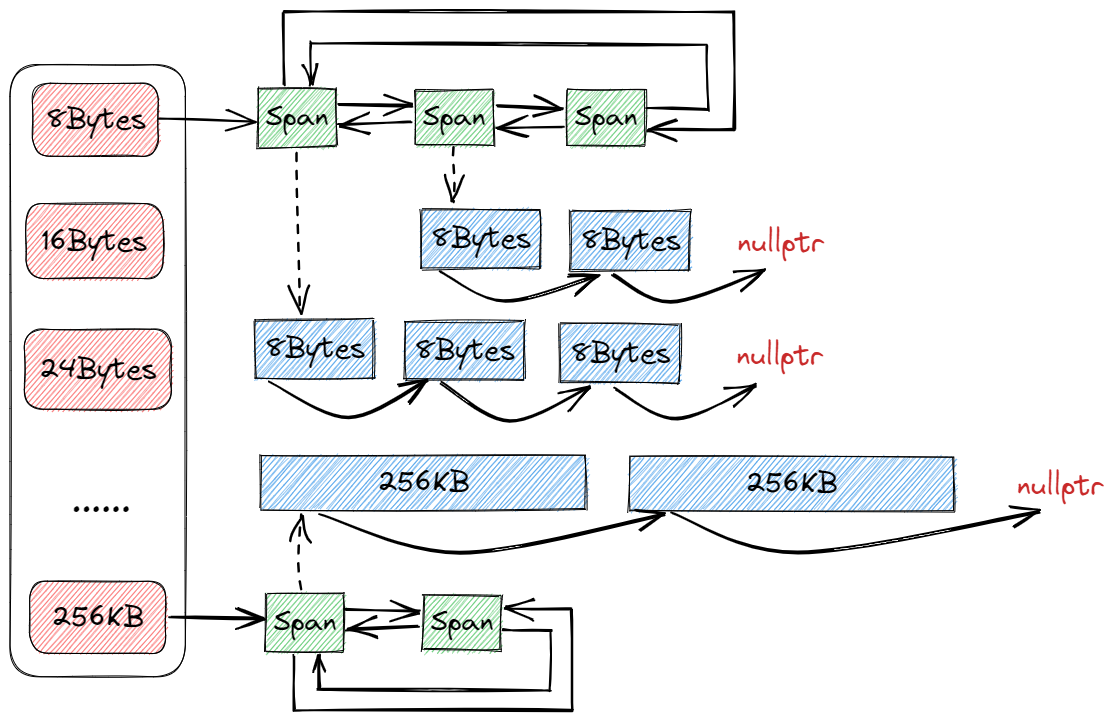
由于 Central Cache 是所有线程共享的,多个 Thread Cache 可能在同一时刻向 Central Cache 申请内存块,因此为了保证线程安全,需要加锁控制。此外,由于只有多个线程同时访问 Central Cache 的同一个桶时才会存在锁竞争,因此无需用锁来锁住所有哈希桶,只需锁住当前所访问的哈希桶即可。
当 Thread Cache 向 Central Cache 申请内存时,如果给的太少,那么 Thread Cache 在短时间用完了又会再来申请;但是如果给的太多,那么 Thread Cache 可能用不完而浪费大量的空间。为此,此处采用慢反馈调节算法,当 Thread Cache 向 Central Cache 申请内存时,如果申请的是较小的对象,那么可以多给一点,但如果申请的是较大的对象,就可以少给一点。
当 Thread Cache 中的某个自由链表太长时,会将自由链表中的对象归还给 Central Cache 中的 Span。但是需要注意的是,归还给 Central Cache 的这些对象不一定都属于同一个 Span 的,且 Central Cache 中的每个哈希桶中都可能不止一个 Span,因此归还时不仅需要知道该对象属于哪一个桶,还需要知道它属于这个桶中的哪一个 Span。为了建立页号和 Span 之间的映射,需要使用一种哈希表结构进行管理,一种方式是采用 C++ 中的 unordered_map,另一种方式是采用基数树数据结构。
3. PageCache
Page Cache 的结构与 Central Cache 一样,都是哈希桶的结构,并且 Page Cache 的每个哈希桶中都挂的是一个个的 Span,这些 Span 也是按照双向链表的结构连接起来的。
但是,Page Cache 的映射规则与 Central Cache 和 Thread Cache 不同,其采用的是直接定址法,比如 1 号桶挂的都是 1 页的 Span,2 号桶挂的都是 2 页的 Span,以此类推。
其次,Central Cache 每个桶中的 Span 都被切为了一个个对应大小的对象,以供 Thread Cache 申请。而 Page Cache 服务的是 Central Cache,当 Central Cache 中没有 Span 时,向 Page Cache 申请的是某一固定页数的 Span。而如果切分这个申请到的 Span 就应该由 Central Cache 自己来决定。
其结构如下图所示:
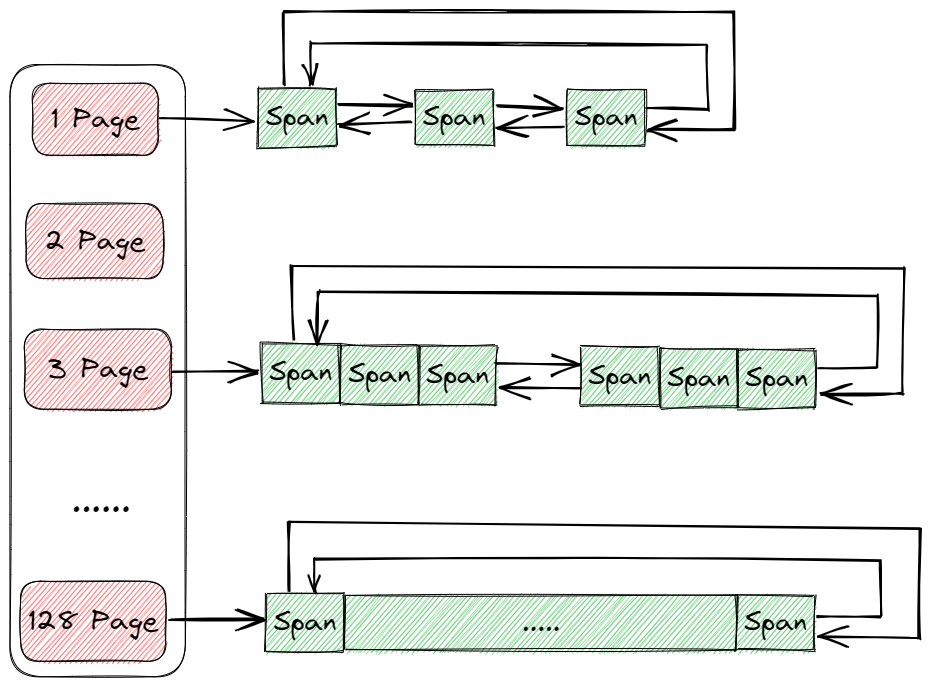
当每个线程的 Thread Cache 没有内存时都会向 Central Cache 申请,此时多个线程的 Thread Cache 如果访问的不是 Central Cache 的同一个桶,那么这些线程是可以同时进行访问的。这时 Central Cache 的多个桶就可能同时向 Page Cache 申请内存,所以 Page Cache 也是存在线程安全问题的,因此在访问 Page Cache 时也必须要加锁。
但是此处的 Page Cache 不能使用桶锁,因为当 Central Cache 向 Page Cache 申请内存时,Page Cache 可能会将其他桶中大页的 Span 切小后再给 Central Cache。此外,当 Central Cache 将某个 Span 归还给 Page Cache 时,Page Cache 也会尝试将该 Span 与其它桶当中的 Span 进行合并。
也就是说,在访问 Page Cache 时,可能同时需要访问多个哈希桶,如果使用桶锁则可能造成大量频繁的加锁和解锁,导致程序的效率底下。因此在访问 Page Cache 时没有使用桶锁,而是用一个大锁将整个 Page Cache 锁住。
如果 Central Cache 中有某个 Span 的 useCnt_ 减到 0
了,那么 Central Cache 就需要将这个 Span 归还给 Page Cache
了。为了缓解内存碎片问题,Page Cache 还需要尝试将还回来的 Span
与其它空闲的 Span 进行合并。
4. 基数树
由于在 PageCache 中最初建立页号与 Span 之间的映射关系时,采用的是 unordered_map 数据结构,但是通过性能测试发现,内存池的性能并未优于原生的 malloc/free 接口,因此通过 Visual Studio 的性能分析工具发现性能瓶颈位于 unordered_map 处。
这主要是因为 unordered_map 不是线程安全的,在多线程环境下需要加锁,而大量的加锁则会导致资源的消耗和性能的下降,因此在映射页号与 Span 之间的关系时,采用基数树(Radix Tree)数据结构来进行优化。
当采用如下图所示的单层基数树时,在 32 位平台下,以一页大小为 8K(\(2^{13}\)) 为例,此时页的数目就是 \(2^{32}\div 2^{13}=2^{19}\),因此存储页号最多需要 19 个比特位,同时由于 32 位平台下的指针大小为 4 字节,因此该数组的大小就是 \(2^{19}\times 4=2^{21}=2M\),内存消耗不大,是可行的。但是如果是在 64 位平台下,此时该数组的大小就是 \(2^{51}\times 8=2^{54}=2^{24}G\),这显然是不可行的:
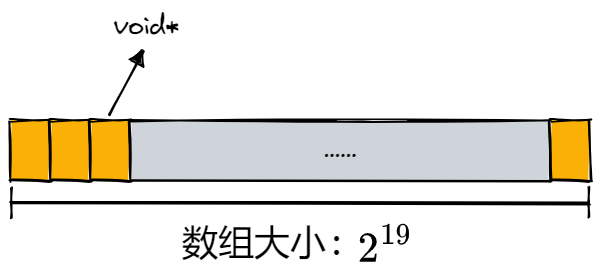
如下图所示,为二层基数树,同样在 32 位平台下,以一页的大小为 8K 为例来说明,此时存储页号最多需要 19 个比特位。而二层基数树实际上就是把这 19 个比特位分为两次进行映射。例如,前 5 个比特位在基数树的第一层进行映射,映射后得到对应的第二层,然后用剩下的比特位在基数树的第二层进行映射,映射后最终得到该页号所对应的 Span 指针。
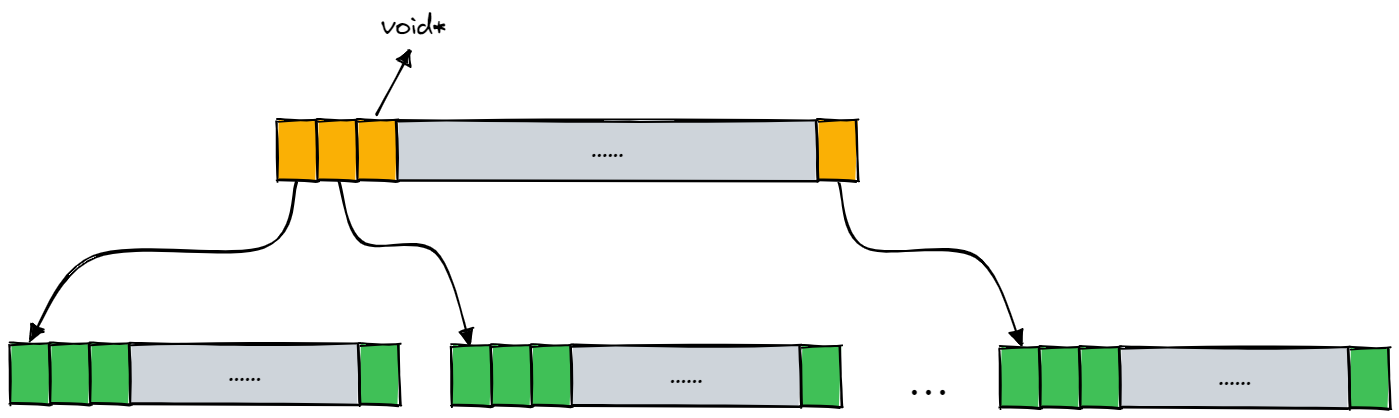
在二层基数树中,第一层的数组占用 \(2^5\times 4=2^7\) Bytes 空间,第二层的数组最多占用 \(2^5\times 2^{14}\times 4=2^{21}=2M\)。二层基数树相比与一层基数树的好处就是,一层基数树必须一开始就把 2M 的数组开辟出来,而二层基数树一开始只需要将第一层的数组开辟出来,当需要进行某一页号映射时再开辟对应的第二层的数组就行了。
在 32 位平台下,一层基数树和二层基数树都是适用的,但是在 64 位平台下,就需要使用下图所示的三层基数树了。三层基数树类似于二层基数树,实际上就是把存储页号的若干比特分为三次进行映射,而且只有当需要建立某一页号的映射关系时,才会开辟对应的数组空间,在一定程度上节约了内存空间:
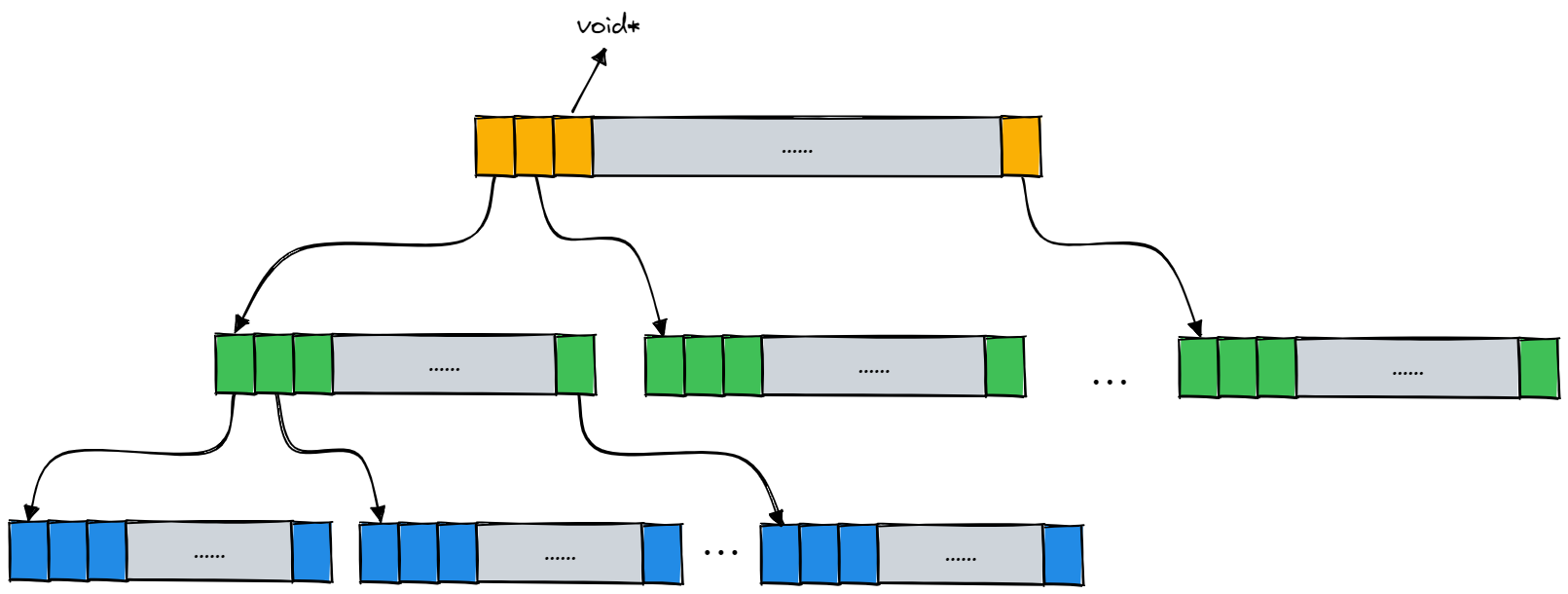
简单介绍一下你的项目
我的这个项目是一个分布式K-V缓存系统,基于CS架构,服务器由一个中心节点和一系列存储节点构成。为客户端提供数据的基于内存的数据缓存功能。底层存储结构是通过跳表实现的。
为什么要做这个项目?
这个项目综合性比较强,包括分布式缓存系统、服务器通信网络库以及内存池,主要是为了学习跳表、分布式存储、网络编程以及内存池等知识,将学习的东西综合应用。
项目是为了解决什么问题?
为了解决在高并发场景中的通过分布式横向扩展节点来处理更多的数据和请求,从而提高系统的容量和吞吐量。并且通过一致性哈希实现负载均衡,防止单个节点的性能瓶颈。
有什么亮点?难点?
亮点是通过一致性哈希能够实现负载均衡,并且把数据备份到下一个节点。有单一节点故障的恢复能力,能够灵活增添节点。
难点是在处理增添节点的时候数据的备份问题,还有服务器之间的数据传递问题。
项目遇到哪些困难,怎么解决的?
运用了哪些技术?
用了一致性哈希,跳表,LRU缓存,重写Muduo网络库,以及重写了google的tcmalloc内存池。
有什么收获?
主要是学习到了网络编程、还有分布式缓存的相关的知识,主要就是提高了C++的编码能力,没做项目之前对这些还比较陌生。
Web服务器里怎么设计的IO复用
使用的epoll,通过EventLoop循环调用实现。
项目里用了线程池,线程池怎么建立起来的,为什么要用线程池
Muduo是one Loop per thread模式,也就是一个线程一个事件循环。通过封装一个事件循环的线程类EventLoopThread,底层的线程通过C++11的thread类创建。然后通过for循环创新事件循环线程类,创建指定个数,会返回相应的EventLoop。当有新连接到来的时候,会调用getnextloop函数在主线程中通过轮询分配EventLoop。
因为单线程处理能力有限,如果多CPU的话可以并行处理数据,实现服务器的高并发。
为什么需要使用内存池?
因为这是基于内存的缓存系统,频繁的内存申请和释放会影响效率,而且还会出现内存碎片的问题,所以使用内存池解决这些问题。
Web服务器这个项目你用了线程池,线程池开多大的呢
线程池一般是根据CPU的数量来开的,有一个主线程,线程池一般就是CPU数量 - 1个。
整个开发过程中有没有遇到困难,怎么解决的
在数据迁移或者数据恢复的出现与预期不对的情况,通过画图,模拟哪些数据应该备份到哪里,然后调试一步一步观察数据的流动进行排错。
能介绍一下在web服务器项目中做了什么样的测试和学习,有什么样的体会
通过手动模拟计算哈希和画图查看数据迁移过程,手动添加新的节点以及Kill掉某一个节点查看系统是否正常运行。
web服务器最主要的一个考量指标是并发处理能力,想问你为了提高并发量做了怎么样的操作
网络服务器中,通过IO多路用以及线程池提高并发,存储通节点并且过内存池管理内存。
什么是跳表
跳表其实就是多层的有序链表,在最底层跳跃长度是1也就是普通的链表,越往上层走,跳表的下一个节点跳得越远,每一层成指数级增长。所以增删改查只需要log(N)的复杂度。
为什么不用哈希算法或者红黑树
相比哈希表,跳表是有序的,对于范围查询更有优势。而且也无需重新哈希。 相比红黑树,插入和删除操作的简便性,无需红黑树复杂的平衡操作,而且范围查询更加容易。
一致性哈希算法是什么,是用什么数据结构实现的
一致性哈希算法是用于分布式数据分片的做法,利用一个哈希环,将服务器节点名字哈希后注册到哈希环中。当有数据存储或者查询操作时通过哈希算法选择对应的存储节点。当发送数据迁移或者新增节点时无需进行大量数据迁移,而是只需要迁移在哈希环中有影响的节点数据即可。 使用的数据结构是红黑树(c++的map结构),方便快速寻找指定哈希值的前后节点。
基数树是什么
基数树的特点是它在树中的每个节点上都存储了一串位数字或者字母,而不是单一的元素。使用三层,第一层存储0-6字节。
为什么需要 I/O 多路复⽤?
- 提高性能:使用I/O多路复用可以减少I/O操作的开销。相比于每个I/O操作都创建一个线程或进程来处理,多路复用可以使用少量的线程或进程同时监视多个I/O通道,从而减少了上下文切换的开销,提高了系统的性能。
- 节省资源:创建和管理线程或进程需要消耗系统资源,而且线程或进程的数量受到系统资源的限制。通过使用I/O多路复用,可以减少同时活跃的线程或进程数量,从而节省了系统资源。
- 支持高并发:在高并发的场景下,使用I/O多路复用可以更有效地处理大量的并发连接。通过复用少量的线程或进程来处理多个I/O通道,可以更好地支持高并发的需求,提高系统的扩展性和稳定性。
- 支持非阻塞I/O:I/O多路复用通常与非阻塞I/O配合使用,可以实现非阻塞的I/O操作。这样可以避免因为I/O操作阻塞导致的线程或进程被长时间挂起,提高了系统的响应速度和吞吐量。
- 简化编程模型:使用I/O多路复用可以简化编程模型。开发人员不需要关注多个I/O操作的具体细节,而是可以使用简单的事件驱动模型来处理I/O事件。这样可以降低编程复杂度,提高代码的可读性和可维护性。
创建线程用什么api
std::thread
如何销毁线程,detach和join有什么区别?
- 调用
std::thread::join():在主线程中调用std::thread对象的join()方法可以等待该线程执行完成。主线程会阻塞,直到被等待的线程执行完成。在被等待的线程执行完成后,join()方法返回,线程对象被销毁。 - 调用
std::thread::detach():在创建线程后,可以调用std::thread对象的detach()方法将该线程“分离”出来。分离后,线程将在后台运行,不再与主线程同步。当线程执行完成后,其资源会自动释放,线程对象也会被销毁。
怎么保证线程安全?互斥锁粒度大怎么办?
使用互斥锁,锁粒度大可以使用细粒度锁。
怎么压测,压测的瓶颈在哪里,是如何检测这个瓶颈的
使用webbench,例子
1 | |
webbench 做压力测试时,该软件自身也会消耗CPU和内存资源,为了测试准确,请将 webbench 安装在别的服务器上。
测试时并发应当由小逐渐加大,比如并发100时观察一下网站负载是多少、打开页面是否流畅,并发200时又是多少、网站打开缓慢时并发是多少、网站打不开时并发又是多少;
瓶颈来源
- 数据库瓶颈
- 应用瓶颈
- 压测工具瓶颈
- Linux 机器出现异常
cpu
下面以 top 命令的输出例,对 CPU 各项主要指标进行说明:
- us(user):运行(未调整优先级的)用户进程所消耗的 CPU 时间的百分比。像 shell 程序、各种语言的编译器、数据库应用、web 服务器和各种桌面应用都算是运行在用户地址空间的进程。这些程序如果不是处于 idle 状态,那么绝大多数的 CPU 时间都是运行在用户态。
- sy(system):运行内核进程所消耗的 CPU 时间的百分比。所有进程要使用的系统资源都是由 Linux 内核处理的。当处于用户态(用户地址空间)的进程需要使用系统的资源时,比如需要分配一些内存、或是执行 I/O 操作、再或者是去创建一个子进程,此时就会进入内核态(内核地址空间)运行。事实上,决定进程在下一时刻是否会被运行的进程调度程序就运行在内核态。对于操作系统的设计来说,消耗在内核态的时间应该是越少越好。通常 sy 比例过高意味着被测服务在用户态和系统态之间切换比较频繁,此时系统整体性能会有一定下降。在实践中有一类典型的情况会使 sy 变大,那就是大量的 I/O 操作,因此在调查 I/O 相关的问题时需要着重关注它。大部分后台服务使用的 CPU 时间片中 us 和 sy 的占用比例是最高的。同时这两个指标又是互相影响的,us 的比例高了,sy 的比例就低,反之亦然。另外,在使用多核 CPU 的服务器上,CPU 0 负责 CPU 各核间的调度,CPU 0 上的使用率过高会导致其他 CPU 核心之间的调度效率变低。因此测试过程中需要重点关注 CPU 0。
- id(idle):空闲的 CPU 时间百分比。一般情况下, us + ni + id 应该接近 100%。线上服务运行过程中,需要保留一定的 id 冗余来应对突发的流量激增。在性能测试过程中,如果 id 一直很低,吞吐量上不去,需要检查被测服务线程/进程配置、服务器系统配置等。
- wa(I/O wait):CPU 等待 I/O 完成时间百分比。和 CPU 的处理速度相比,磁盘 I/O 操作是非常慢的。有很多这样的操作,比如:CPU 在启动一个磁盘读写操作后,需要等待磁盘读写操作的结果。在磁盘读写操作完成前,CPU 只能处于空闲状态。Linux 系统在计算系统平均负载时会把 CPU 等待 I/O 操作的时间也计算进去,所以在我们看到系统平均负载过高时,可以通过 wa 来判断系统的性能瓶颈是不是过多的 I/O 操作造成的。磁盘、网络等 I/O 操作会导致 CPU 的 wa 指标提高。通常情况下,网络 I/O 占用的 wa 资源不会很高,而频繁的磁盘读写会导致 wa 激增。如果被测服务不是 I/O 密集型的服务,那需要检查被测服务的日志量、数据载入频率等。如果 wa 高于 10% 则系统开始出现卡顿;若高于 20% 则系统几乎动不了;若高于 50% 则很可能磁盘出现故障。
分析思路
- wa(IO wait)的值过高,表示硬盘存在 I/O 瓶颈。
- id(idle)值高,表示 CPU 较空闲。
- 如果 id 值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量。
- 如果 id 值持续低于 10,那么系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
磁盘 I/O
iostat 参数详解
Linux 下可以用 iostat 命令来监控磁盘状态。
iostat -d 2 10 表示每 2 秒统计一次基础数据,统计 10 次:
- tps:该设备每秒的传输次数。“一次传输”意思是“一次 I/O 请求”。多个逻辑请求可能会被合并为“一次 I/O 请求”。“一次传输”请求的大小是未知的。
- kB_read/s:每秒从设备(driveexpressed)读取的数据量,单位为 Kilobytes。
- kB_wrtn/s:每秒向设备(driveexpressed)写入的数据量,单位为 Kilobytes。
- kB_read:读取的总数据量,单位为 Kilobytes。
- kB_wrtn:写入的总数量数据量,单位为 Kilobytes。
数据库
首先找慢查询
通过 SQL 语句定位到慢查询日志的所在目录,然后查看日志。
1
show variables like "slow%";慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题时,查询慢查询日志并不能定位问题。这时可以使用show processlist命令查看当前 MySQL 正在进行的线程状态,可以实时地查看 SQL 的执行情况。
找到慢查询 SQL 后可以用执行计划(explain)进行分析
单reactor单线程到多reactor多线程
单reactor单线程
这种模型在Reactor中处理事件,并分发事件,如果是连接事件交给acceptor处理,如果是读写事件和业务处理就交给handler处理,但始终只有一个线程执行所有的事情。
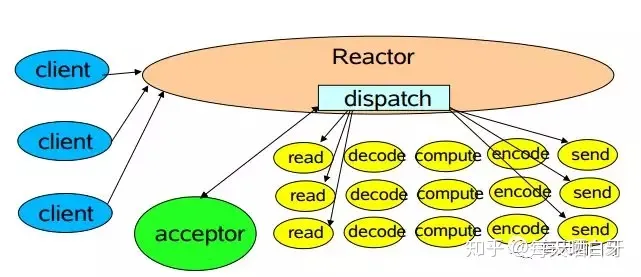
该线程模型的不足
- 仅用一个线程处理请求,对于多核资源机器来说是有点浪费的
- 当处理读写任务的线程负载过高后,处理速度下降,事件会堆积,严重的会超时,可能导致客户端重新发送请求,性能越来越差
- 单线程也会有可靠性的问题
单reactor多线程
这种模型和第一种模型到的主要区别是把业务处理从之前的单一线程脱离出来,换成线程池处理,也就是Reactor线程只处理连接事件和读写事件,业务处理交给线程池处理,充分利用多核机器的资源、提高性能并且增加可靠性。
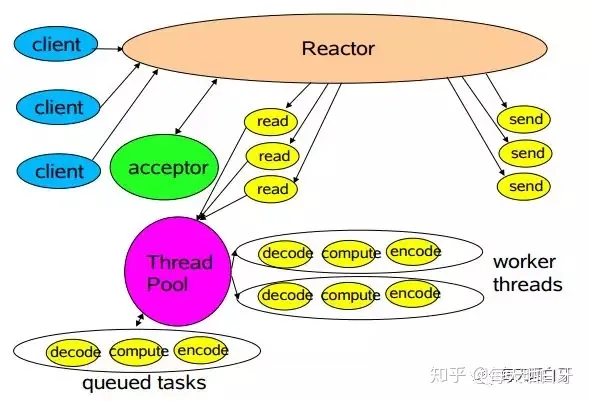
该线程模型的不足
Reactor线程承担所有的事件,例如监听和响应,高并发场景下单线程存在性能问题
多reactor多线程
这种模型下和第二种模型相比是把Reactor线程拆分了mainReactor和subReactor两个部分,mainReactor只处理连接事件,读写事件交给subReactor来处理。业务逻辑还是由线程池来处理。
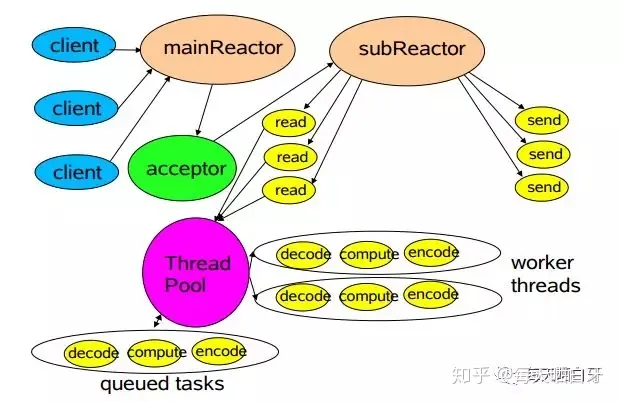
mainRactor只处理连接事件,用一个线程来处理就好。处理读写事件的subReactor个数一般和CPU数量相等,一个subReactor对应一个线程,业务逻辑由线程池处理
这种模型使各个模块职责单一,降低耦合度,性能和稳定性都有提高。这种模型在许多项目中广泛应用,比如Netty的主从线程模型等
Reactor三种模式形象比喻
餐厅一般有接待员和服务员,接待员负责在门口接待顾客,服务员负责全程服务顾客 Reactor的三种线程模型可以用接待员和服务员类比
- 单Reactor单线程模型:接待员和服务员是同一个人,一直为顾客服务。客流量较少适合
- 单Reactor多线程模型:一个接待员,多个服务员。客流量大,一个人忙不过来,由专门的接待员在门口接待顾客,然后安排好桌子后,由一个服务员一直服务,一般每个服务员负责一片中的几张桌子
- 多Reactor多线程模型:多个接待员,多个服务员。这种就是客流量太大了,一个接待员忙不过来了
free()函数如何知道要释放的空间大小?
free()函数如何知道要释放的空间大小? - 卡麦哈麦哈的回答 - 知乎 https://www.zhihu.com/question/302440083/answer/544571934
epoll一定要比select快吗,能举个例子吗?
不一定,文件描述符非常多时,每次都要对文件描述符进行一些操作并对参数读入时内核和用户态的切换操作导致select效率比较低。
但是网络环境非常好,即干扰很少,某个服务器只接受固定的计算机发来的数据(例如10台),这种情况下连接非常少, 使得epoll高效的上述因素显然不能成立了,此时可以认为epoll和select效率近似。
epoll最多能有多少个连接这个了解吗?
8G内存, 一个epoll服务端,15个客户端(通过增加虚拟IP,每个客户端5万个连接),能支持的并发连接数是接近70万。
客户端与服务器端建立TCP连接,当服务器端进程core dump之后会发生什么
当服务器端进程发生core
dump后,TCP连接通常会因为服务器进程的终止而关闭。客户端可能会收到一个错误,如ECONNRESET,表明连接被对方重置。此外,客户端的任何后续尝试发送或接收数据都会失败,因为TCP连接不再有效。
有没有避免死锁的机制
介绍以下内存池怎么实现的?
介绍以下muduo库
你了解什么是负载均衡吗?(腾讯云)
解释一下epoll(腾讯云)
红黑树(腾讯云)
跳表、红黑树、AVL树的区别
跳表、红黑树、AVL树分别适用于什么场景
手撕代码
线程安全的循环队列
1 | |
无锁队列
每个节点的数据结构:
1 | |
而对于一个无锁队列对象而言,包含以下部分
- 数据:队列的最大长度、链表头结点、链表尾节点
- 函数:初始化(构造函数)、入队、出队
1 | |
入队操作
1 | |
- 加入成功,那么退出循环进入倒数第三行
- 加入不成功,说明这时候有其他线程抢先往里面插入了一个节点,那么就把当前节点的位置更新为尾节点,再次进入循环直到能正确更新
到了最后一个CAS的时候,只需要进行一次置尾操作,并不需要循环,原因是:如果当前线程将节点已经加进去了的话,那么其他所有线程的操作都会失败,只有当前线程更新尾节点完成后,其他线程的第二个CAS操作才能成功。
这里有一个小trick,明明第6行每次循环时都会更新节点,为什么还需要第二个CAS操作呢?因为在极端情况下,一个线程已经完成了增加节点操作,在置尾操作(第三个CAS)之前突然挂了,这时候就导致其他所有线程全部不能更新。
在左耳朵耗子的博客中,对于上述问题的解决方法描述是选用了《Implementing Lock-Free Queues》论文中提到的第二个方法,该方法采用的是一开始在head,然后不断找next直到找尾节点(通过多个线程共用fetch来减少开销)。本文以论文中提到的第一个方法为例进行描述(因为我觉得它更优雅)。
出队操作
与入队操作类似。
1 | |
O(1)时间复杂度内删除链表中的一个节点
给你头节点head和待删除节点node,要求在O(1)时间复杂度删除node
若node不是最后一个节点
把node的值与node->next的值交换,然后删除node->next即可。
若node是最后一个节点
仍然需要从head遍历到node的上一个节点,然后删除node,但是只有这一种个情况是O(n),所以平均时间复杂度仍然是O(1)
string类实现,包括构造函数,拷贝构造函数,赋值构造,析构函数
1 | |
实现Vector类,要求实现这些方法:初始化、整体拷贝、push_back、pop_back、vector[pos]获取指定位置的元素
1 | |
快乐数,每一位平方求和,循环操作是否可以变为1
链表快排
1 | |
判断一个点是否在三角形内
使用叉乘判断点是否在三角形内:
1 | |
反转链表倒数k个节点前的节点
LC151. 反转字符串中的单词(要求原地翻转)
LC236. 二叉树的最近公共祖先
LC39. 组合总和
LC7. 整数反转
见整数反转.
稀疏矩阵乘法(要优化之后的)
见稀疏矩阵相乘.
1 | |
LC343. 整数拆分(割绳子)
见整数拆分.
LC54. 螺旋矩阵
见螺旋矩阵.
手撕代码:将一个字符串转换成字符加出现次数的形式,比如aaabb转换成a3b2(要求不能用任何int转str的api)(腾讯云)
手写线程池(腾讯云)
手写智能指针(腾讯云)
手写读者写者
口算(9^999999)%5=?
求(a^b)%n。本质是快速幂,只写出递归。a、b、n都很⼤,int会爆,必须⽤long
比赛
金融科技建模大赛
赛题设置
比赛的主题是“客户复购行为预测”。银行不仅关注新客户获客,也关注老客户的复购行为,希望增加客户黏性。客户在金融产品和服务上的重复购买行为越多,客户黏性越大。银行可以通过识别这些黏性客户,更好地分析他们的需求,并向他们推送新产品,进行客户关系管理。本次比赛的目标是对客户复购频率的三分类预测。比赛选手需要根据客户信息(包括基础客户画像信息、产品购买行为信息以及第三方客户画像补充信息)预测客户复购行为标签:低频(0)、中频(1)、高频(2),并根据客户平均价值(低频1、中频3、高频5),在独立样本上检验预测准确性(加权准确性)。
数据
分为3个表,X1表为客户基本信息,X2表为客户消费相关信息,X3为其他信息
初赛训练集
复赛训练集15000条,测试集8000条
特征工程
- 缺失值填充:对于连续型数值特征使用均值填充,对于离散型数值使用众数填充,对于类别特征使用unknown填充
- 特征经过脱敏,比如像X1表很多只写了基本特征,可以根据其格式判断是省份,身份证号。然后可以进一步根据省份划分出东中西部地区。身份证号其实就跟省份冲突。
- 根据catboost的特征重要性分析提取出强特征,然后对强特征做交叉特征(加减乘除),然后过滤掉重要性比较低的衍生特征
- 每个客户都有多条消费记录,把这些消费记录按照客户编号进行分桶,然后统计诸如消费次数,消费平均金额,并对里边如果是数值的特征做众数、中位数、平均数、最大最小值作为新特征,以及连续消费的天数,如果是字符串的话统计不同字符串的个数,等特征(这个对于性能提升是很大的)
- 对一些重要性不是特别重要的特征但是之间可能有关联的特征,这些特征单个可能不是很重要,但是做交叉之后重要性会更高(客户货款偿付比例与收入增长的关系。这可能反映了客户的财务稳定性和收入增长的能力)
训练
使用catboost模型,使用GridSearchCV网格搜索最优参数
xgboost、catboost、lightgbm
选择哪个算法取决于数据集的规模、特征的类型以及任务的要求。LightGBM 适用于大规模数据和高维特征,XGBoost 适用于一般规模的数据和任务,而 CatBoost 则适用于处理类别型特征和稀疏数据的场景。
第五届全国大学生计算机能力挑战赛
赛题描述
给予一批随机目标图片,选手需要将这些图片中的目标进行检测目标位置并识别目标类别。
数据集描述
提供少量训练集(训练集1500张图片、测试集500张图片),会在数据开放下载后陆续公布,总体为低资源的竞赛任务。训练集用于选手的模型训练,测试集存在服务器后台,用于最终结果的评测提交,不提供给选手。
训练集包含:1.图片文件;2.描述图片目标位置和类别文件。
YOLOv8结构
- 输入端:缩放图片尺寸数据、适应模型训练;
- Backbone:模型主网络,通过卷积层数的增加,提取P1-P5不同感受野的feature map,依次感受野逐渐增加;
- Neck:呈现FPN和PAN结构,其中FPN (feature pyramid networks):特征金字塔网络,采用多尺度来对不同size的目标进行检测;PAN:自底向上的特征金字塔。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行特征聚合。
- Prediction:为model框架中的Head头,用于最终的预测输出,P3 -> P4 -> P5过程中,感受野是增大的,所以依次预测目标为小 -> 中 -> 大。
使用的优化方法
场景题
一个数据流中随机抽样固定大小样本(字节懂车帝)
蓄水池抽样:
- 从数据流中读取前k个元素,依次放入水塘中。
- 对于第i个元素(i > k),以1/i的概率随机选择是否将其替换水塘中的某个元素。如果被选择,则随机选择水塘中的一个位置,用当前元素替换该位置的元素。
- 处理完整个数据流后,水塘中的k个元素即为随机抽样得到的样本。
圆上三个点构成锐角三角形的概率
1 / 4
美团用户点外卖场景 ,如何快速筛选距离比较近的商家,不要求很精确
ElasticSearch,倒排索引(inverted index)。
正排索引是从文档角度来找其中的单词,表示每个文档(用文档ID标识)都含有哪些单词,以及每个单词出现了多少次(词频)及其出现位置(相对于文档首部的偏移量)。所以每次搜索都是遍历所有文章。
倒排索引是从单词角度找文档,标识每个单词分别在那些文档中出现(文档ID),以及在各自的文档中每个单词分别出现了多少次(词频)及其出现位置(相对于该文档首部的偏移量)。
搜索的过程:
当用户输入任意的词条时,
- 首先对用户输入的数据进行分词,得到用户要搜索的所有词条。
- 然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。
- 最后根据这些编号去文档列表中找到文档
创建倒排索引,分为以下几步:
- 创建文档列表:lucene首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表
- 创建倒排索引列表:然后对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。然后记录下包含该词条的所有文档编号(及其它信息)。
我有1T空间的url,怎么考虑统计出现top10000的url
处理1TB数据以找到出现次数最多的前10000个URL是一个大数据问题。这里有一个可能的解决方案,使用MapReduce编程模型:
- Map阶段:将数据分割成更小的块,每个块由一个Map任务处理。Map任务读取URL,然后为每个URL生成键值对,键是URL,值是1。
- Shuffle阶段:系统将所有键值对按键(URL)进行排序和合并,以便所有相同的键(URL)都在一起。
- Reduce阶段:每个Reduce任务处理一组具有相同键的键值对,累加值以计算每个URL的总出现次数。
- 最后处理:所有Reduce任务的输出被合并,然后可以使用一个排序算法来找到出现次数最多的前10000个URL。
如果是分布式的场景,即有多个机子上都有很多url,现在怎么考虑
在分布式系统中处理大量URL的情况,你可以采用以下步骤:
- 数据分片:首先,将1TB的数据均匀分配到多个机器上。
- 本地统计:每台机器上运行MapReduce任务,本地统计每个URL出现的次数。
- 全局合并:将所有机器上的本地统计结果合并,这通常涉及到一个中心节点或使用另一个MapReduce作业来完成。
- Top K算法:在合并后的全局数据上运行Top K算法(如Min-Heap或MapReduce中的Secondary Sort)来找到出现次数最多的前10000个URL。
有140g沙子,现在有7g和2g的砝码各一个,并有一个天平,用最少次数把沙子分为50g和90g
- 用7 + 2 = 9g称两次得到18g
- 用7g称一次加上之前的18g一共是25g
- 用这25g沙子再称25g沙子得到50g
一共4次。
什么是跨域,怎么解决?
跨域是指浏览器出于安全原因阻止从一个域的网页向另一个域的服务器发出请求的现象。这个限制称为同源策略,它要求在同一个域名、协议和端口号的情况下,才允许进行请求。
常见的跨域解决方法有以下几种:
- CORS(跨域资源共享):服务器在响应头中添加特定的CORS头部信息(如
Access-Control-Allow-Origin),允许浏览器接受来自不同域的请求。 - JSONP:通过使用
<script>标签进行跨域请求。因为<script>标签不受同源策略限制,服务器会返回一段包含回调函数的JavaScript代码,前端接收到后会自动执行。 - 服务器代理:前端将请求发送到本域名的服务器,由服务器再去请求目标域,并返回结果给前端。
- Nginx反向代理:在Nginx中配置代理,前端请求经过Nginx代理到目标服务器,避免跨域问题。
其他
你都知道哪些消息队列
- Kafka
- RocketMQ
- RabbitMQ
如何判断一个图里是否存在环
使用深度优先搜索算法(DFS)来判断一个图是否存在环的基本思路:
- 从图中的任意一个顶点开始进行深度优先搜索。
- 在搜索过程中,如果遇到一个已经被访问过的顶点,而且这个顶点不是当前顶点的父节点(在搜索树中),则说明存在环。
git pull和git pull --rebase,git fetch的区别
git fetch和git pull的区别
在执行 git pull 后,代码会自动 merge 到本地的分支中,而
git fetch 会忽略掉这个 merge 操作,因此简单来说:
1 | |
git pull和git pull --rebase的区别
git pull 命令默认包含了一个 --merge
参数,因此二者的区别其实就是 merge 和 rebase
的区别。
merge:
merge 会创建一个新的
commit,如果合并时遇到了冲突,需要解决冲突后重新 commit。
rebase:
rebase 会将两个分支进行合并,同时合并之前的 commit
历史。如果出现冲突,解决冲突后执行以下命令即可:
1 | |
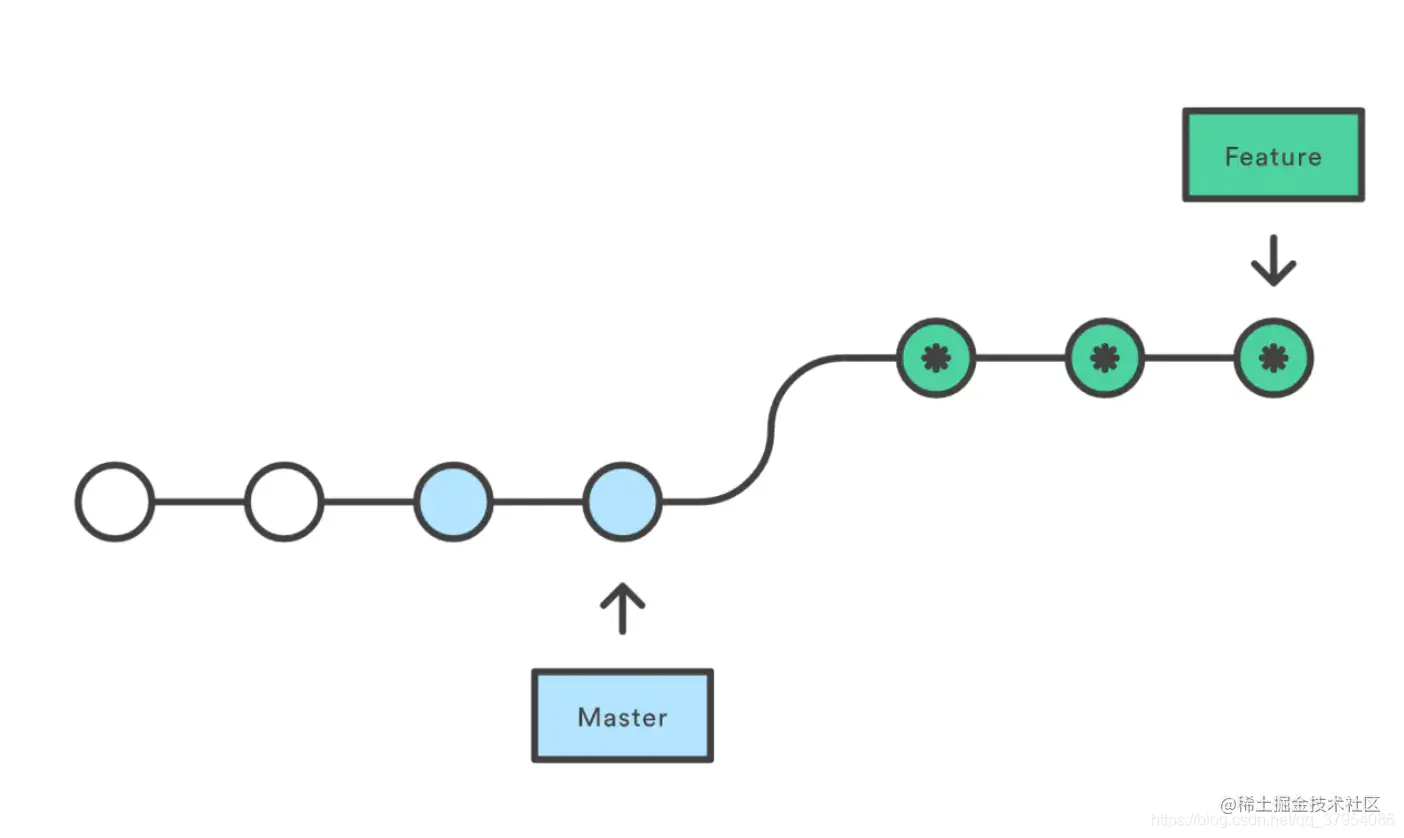
现在我们来实现一个多线程环境下的任务执行器,你觉得应该如何设计呢?
可以首先设计一个任务队列,用来存放待执行的任务。然后创建多个线程,这些线程会从任务队列中取出任务并执行。任务执行完成后,将结果存放到一个共享的列表中。需要注意的是,在多线程环境下,要确保线程安全,可以使用同步机制或锁来保证共享资源的安全访问。
git rebase, git merge, git squash的区别
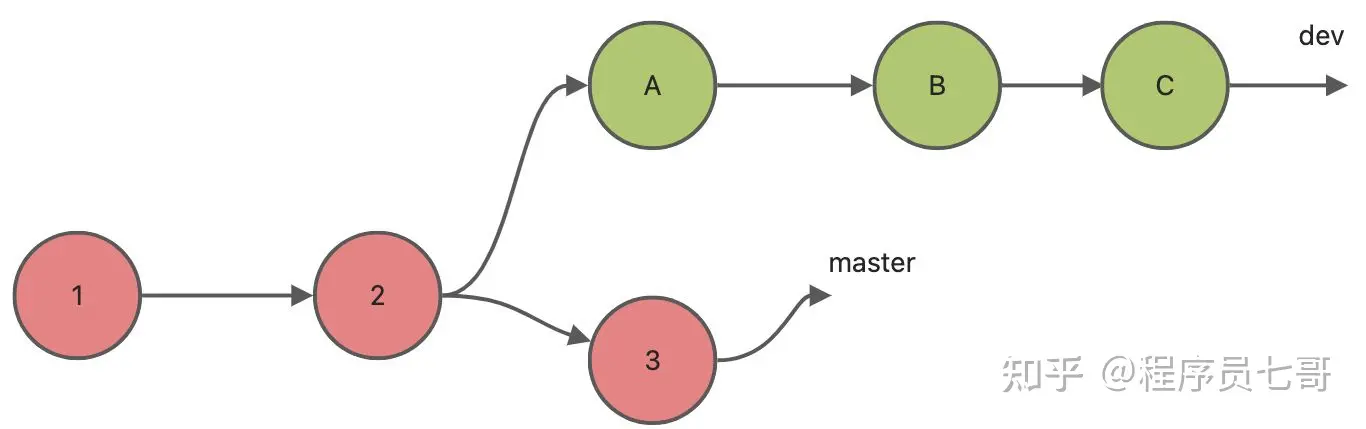
git merge:
这是最基本的merge,就是把提交历史原封不动的拷贝过来,包含完整的提交历史记录。
1 | |

此时还会生产一个 merge commit (D'),这个
merge commit
不包含任何代码改动,而包含在dev分支上的几个commit列表(A,
B和C)。查看git的提交历史(git log)可以看到所有的这些提交历史记录。
git squash merge:
根据字面意思,这个操作完成的是压缩的提交,解决的是什么问题呢?由于在dev分支上执行的是开发工作,有一些很小的提交,或者是纠正前面的错误的提交,对于这类提交对整个工程来说不需要单独显示出来一次提交,不然导致项目的提交历史过于复杂。所以基于这种原因,我们可以把dev上的所有提交都合并成一个提交;然后提交到主干。

在这个例子中,我们把A,B和C的改动合并成了一个D。
注意,squash merge
并不会替我们产生提交D,它只是把所有原本属于A、B和C的改动合并,然后放在本地文件,需要你再次手动执行
git commit 操作。
此时又要注意了,因为你要你手动 commit,也就是说这个 commit 是你产生的,不是有原来 dev 分支上的开发人员产生的,提交者本身发生了变化。也可以这么理解,就是你把 dev 分支上的所有代码改动一次性提交到 master 分支上而已。
git rebase merge:
由于 squash merge
会变更提交者作者信息,这是一个很大的问题,后期问题追溯不好处理(当然也可以由分支dev的所有者来执行
squash merge
操作,以解决部分问题),rebase merge
可以保留提交的作者信息,同时可以合并commit历史,完美的解决了上面的问题。
1 | |
rebase merge 分两步完成:
第一步:执行rebase操作,结果是看起来dev分支是从主分支的提交3拉出来的,而不是从提交2拉出来的,然后使用-i参数手动调整commit历史,是否合并如何合并。例如
rebase -i 命令会弹出文本编辑框:
1 | |
假设提交B是对提交A的一个拼写错误修正,因此可以不需要显式的指出来,我们把B修改为fixup:
1 | |
rebase之后的状态变为:
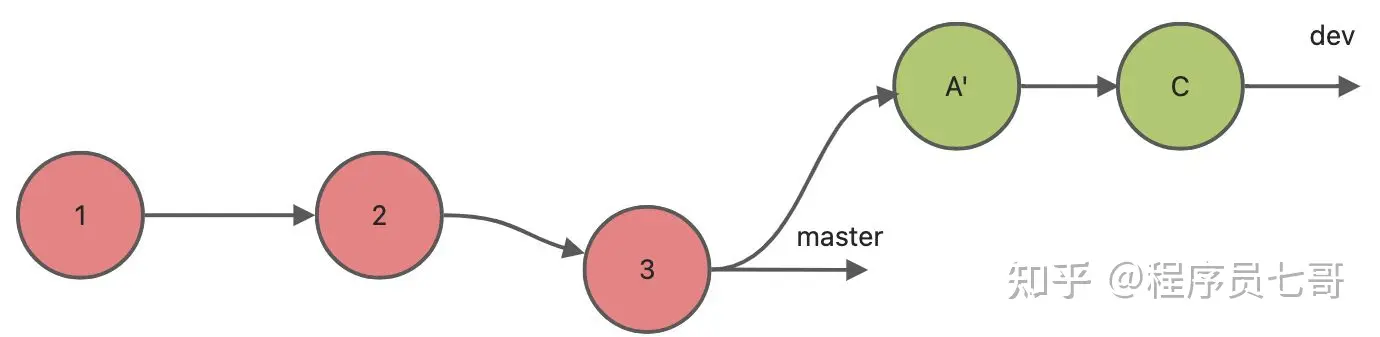 A' 是A和B的合并。
A' 是A和B的合并。
第二步:再执行merge操作,把dev分支合并到master分支:

注意:
- 在执行
rebase的时候可能会出现冲突的问题,此时需要手工解决冲突的问题,然后执行(git add)命令; - 所有冲突解决完之后,这时不需要执行(git commit)命令,而是运行(git rebase --continue)命令,一直到rebase完成;如果中途想放弃rebase操作,可以运行(git rebase --abort)命令回到rebase之前的状态。
CAP理论
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
Raft专注于解决一致性和分区容错性问题,而将可用性问题留给其他机制处理。