设计模式
设计模式
UML类图
类之间的关系通常是我们需要关心的,而我们可以通过UML类图来描述类之间的关系。UML类图中的关系有以下几种:
泛化关系(generalization)
类的继承结构表现在UML中为:泛化(generalize)与实现(realize):
继承关系为 is-a的关系;两个对象之间如果可以用 is-a 来表示,就是继承关系:(..是..)
eg:自行车是车、猫是动物
泛化关系用一条带空心箭头的直接表示;如下图表示(A继承自B);
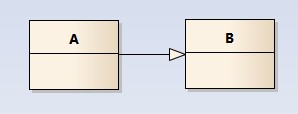
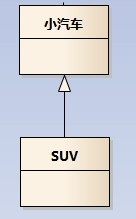
eg:汽车在现实中有实现,可用汽车定义具体的对象;汽车与SUV之间为泛化关系;
实现关系(realization)
实现关系用一条带空心箭头的虚线表示;
eg:”车”为一个抽象概念,在现实中并无法直接用来定义对象;只有指明具体的子类(汽车还是自行车),才 可以用来定义对象(”车”这个类在C++中用抽象类表示,在JAVA中有接口这个概念,更容易理解)
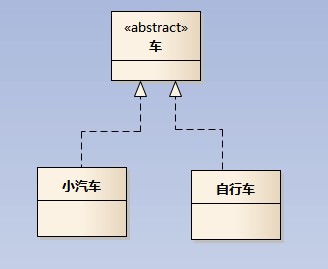
注:最终代码中,实现关系表现为继承抽象类;
聚合关系(aggregation)
聚合关系用一条带空心菱形箭头的直线表示,如下图表示A聚合到B上,或者说B由A组成;
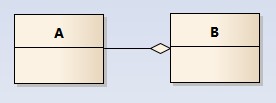
聚合关系用于表示实体对象之间的关系,表示整体由部分构成的语义;例如一个部门由多个员工组成;
与组合关系不同的是,整体和部分不是强依赖的,即使整体不存在了,部分仍然存在;例如, 部门撤销了,人员不会消失,他们依然存在;
组合关系(composition)
组合关系用一条带实心菱形箭头直线表示,如下图表示A组成B,或者B由A组成;
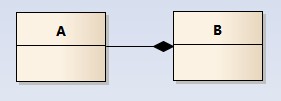
与聚合关系一样,组合关系同样表示整体由部分构成的语义;比如公司由多个部门组成;
但组合关系是一种强依赖的特殊聚合关系,如果整体不存在了,则部分也不存在了;例如, 公司不存在了,部门也将不存在了;
关联关系(association)
关联关系是用一条直线表示的;它描述不同类的对象之间的结构关系;它是一种静态关系, 通常与运行状态无关,一般由常识等因素决定的;它一般用来定义对象之间静态的、天然的结构; 所以,关联关系是一种“强关联”的关系;
比如,乘车人和车票之间就是一种关联关系;学生和学校就是一种关联关系;
关联关系默认不强调方向,表示对象间相互知道;如果特别强调方向,如下图,表示A知道B,但 B不知道A;
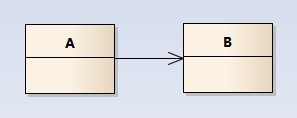
注:在最终代码中,关联对象通常是以成员变量的形式实现的;
依赖关系(dependency)
依赖关系是用一套带箭头的虚线表示的;如下图表示A依赖于B;他描述一个对象在运行期间会用到另一个对象的关系;
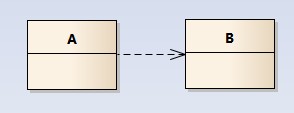
与关联关系不同的是,它是一种临时性的关系,通常在运行期间产生,并且随着运行时的变化; 依赖关系也可能发生变化;
显然,依赖也有方向,双向依赖是一种非常糟糕的结构,我们总是应该保持单向依赖,杜绝双向依赖的产生;
注:在最终代码中,依赖关系体现为类构造方法及类方法的传入参数,箭头的指向为调用关系;依赖关系除了临时知道对方外,还是“使用”对方的方法和属性;
设计模式
设计模式知识见设计模式
面向对象设计原则
- 单一职责原则(Single Responsibility Principle)
- 一个类应该仅有一个引起它变化的原因。
- 变化的方向隐含着类的责任。
- 里氏替换原则(Liskov Substitution Principle)
- 子类必须能够替换它们的基类(IS-A)。
- 继承表达类型抽象。
- 依赖倒置原则(Dependence Inversion Principle)
- 高层模块(稳定)不应该依赖于低层模块(变化),二者都应该依赖于抽象(稳定) 。
- 抽象(稳定)不应该依赖于实现细节(变化) ,实现细节应该依赖于抽象(稳定)。
- 接口隔离原则(Interface Segregation Principle)
- 不应该强迫客户程序依赖它们不用的方法。
- 接口应该小而完备。
- 迪米特法则(Law Of Demeter)
- 一个对象应该对其他对象有最少的了解,低耦合,高内聚。
- 开闭原则(Open Close Principle)
- 对扩展开放,对更改封闭。
- 类模块应该是可扩展的,但是不可修改。
设计模式分类
- 创建型模式: 这类模式提供创建对象的机制, 能够提升已有代码的灵活性和可复用性。创建型模式包括单例模式、工厂模式、抽象工厂模式、建造者模式、原型模式
- 结构型模式: 这类模式介绍如何将对象和类组装成较大的结构, 并同时保持结构的灵活和高效。结构型模式包括适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式
- 行为型模式: 这类模式负责对象间的高效沟通和职责委派。行为型模式包括策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
单例模式
面试手写两种单例
1 | |
单例模式中懒汉和饿汉的本质区别
- 饿汉式在进程刚开始的时候就创建了对象,若这个其构造函数需要做的事有很多,那么会导致系统在启动的时候卡顿.而懒汉式的实例对象是在第一次使用的时候才创建的,这样就避免了启动卡顿的问题。在C++中由于饿汉式的这个缺点,所以一般不使用饿汉式,而是使用懒汉式。
- 饿汉式是线程安全的,在类创建的同时就已经创建好一个静态的对象供系统使用,以后不在改变。而懒汉模式需要在实现的时候保证线程安全。
懒汉式的实现方式
首先将static类型的对象改成指针,调用函数获取该指针时,首先判断指针是否为空,为空就new一个,不为空直接返回指针.我们初始化其为空,这样就需要new一个了,然后第二次调用该函数getInstance()就不为空了,然后直接返回。
1 | |
但这个并不是线程安全的!
上面的实现在单线程环境下没问题,因为单线程情况下getInstance()不会被同时调用,只能调用完,再调用.但是在多线程条件下,该函数不是可重入函数。多线程条件下,某个线程调用该函数,没有执行完即对象instance还没被创建,另一个线程也执行该函数,发现instance为空,那也执行创建语句instance
= new Singleton();,所以该函数不是可重入函数.
info
可重入函数是指能够被多个线程“同时”调用的函数,并且能保证函数结果正确不必担心数据错误的函数
创建instance对象其实做了三件事:
- 分配内存空间
- 构造对象
- 给instance赋值
1 | |
- 如前面所说,线程A把new的对象赋值给instance之前,线程B也进入了
getInstance()函数,发现instance为空,也执行了new语句,这样就会导致两个线程创建了两个对象,这样就违背了单例. - 编译器为了加快代码执行速度,可能先赋值,然后再构造对象,比如对象的属性很多,构造比较久,就先给变量赋值,然后再对该变量进行初始化.这样就会导致线程A执行到第一步,给instance赋值,此时instance不为空,但是对象还没有构造出来,线程B执行到第一步,发现instance不为空,就直接返回了instance,但是此时对象还没有构造出来,这样就会导致线程B使用了一个没有构造出来的对象,这样就会导致程序崩溃.
从上面两个角度来看,我们都需要给instance = new Singleton();加锁,不能让多个线程同时执行这一句.
1 | |
info
std::lock_guard属于C++11特性,锁管理遵循RAII习语管理资源。RAII详见RAII原理
但是这里又有新的问题:锁的粒度太大了,单线程环境下每次调用该函数也会执行加锁操作.所以还得修改,改成下面之后,单线程下只有第一次会加锁,第二次以后调用就不会加锁了.
1 | |
这种情况下,出自这个if的括号就会释放锁了,(return instance前面的括号)。这个也有问题,第二个线程阻塞后还是会执行new,所以需要加一个if判断。
1 | |
这个instance是static的,存储在全局/静态变量区——操作系统的数据段。是同一个进程,多个线程共享的数据。
CPU在执行线程指令的时候,为了加快多线程的执行速度(或者说是先由编译器做的优化,然后落实到CPU上),会将这些线程共享的数据都拷贝一份到自己的线程寄存器上——我们这里就是instance对象.
所以我们要加一个关键字volatile,加了之后,当instance这个共享变量改变之后,就是告诉线程该去内存上去找该变量而不是取自己的寄存器上的。因为线程A先取了该变量到自己寄存器上,然后线程B把该变量修改了(修改后它也会同步到内存里),那么线程A要是还在自己的寄存器上取该变量,那读取到的就是未更新的。
所以volatile适合用来修饰随时都可能被修改的变量,告诉将要读取该变量的线程不要从自己的寄存器或者cache上取该变量,而是去内存上取。
线程安全的懒汉式单例模式
1 | |
不使用互斥锁的线程安全的懒汉式单例模式
将该对象放在函数里,成为静态局部变量。注意,静态局部变量也是在全局区(C++内存模型的叫法),和静态全局变量,全局变量一样,是在编译器就被分配了内存。
但是静态局部变量的初始化是运行到该语句时,进行初始化
info
C和C++的处理还不一样,C语言是编译时分配内存和初始化的;C++,编译时分配内存,(运行时)首次使用时初始化。这主要是由于C++引入对象后,要进行初始化必须执行相应构造函数和析构函数,在构造函数或析构函数中经常会需要进行某些程序中需要进行的特定操作,并非简单地分配内存。所以C++标准定为全局或静态对象是有首次用到时才会进行构造。
1 | |
也因为是调用该函数才会初始化该对象,没调用的话该对象不会调用构造函数,所以也是一个懒汉式单例模式。
info
在多线程情况下,函数静态局部变量的初始化,在汇编指令上已经自动添加线程互斥指令了.如果线程A调用该函数,在初始化未完成之前,线程B不会执行该初始化操作。线程A完成初始化后,已经初始化过的变量,其它线程不会再重复进行初始化操作,从而只有一个实例对象产生。
C++ static初始化见Cpp-static初始化
以上单例内容参考自C++ 单例模式
建造者模式和工厂模式的区别
建造者模式与工厂模式是极为相似的,总体上,建造者模式仅仅只比工厂模式多了一个“导演类”的角色。在建造者模式的类图中,假如把这个导演类看做是最终调用的客户端,那么图中剩余的部分就可以看作是一个简单的工厂模式了。
与工厂模式相比,建造者模式一般用来创建更为复杂的对象,因为对象的创建过程更为复杂,因此将对象的创建过程独立出来组成一个新的类————导演类。也就是说,工厂模式是将对象的全部创建过程封装在工厂类中,由工厂类向客户端提供最终的产品;而建造者模式中,建造者类一般只提供产品类中各个组件的建造,而将具体建造过程交付给导演类。由导演类负责将各个组件按照特定的规则组建为产品,然后将组建好的产品交付给客户端。
为什么需要创建型模式
首先,在编程中,对象的创建通常是一件比较复杂的事,因为,为了达到降低耦合的目的,我们通常采用面向抽象编程的方式,对象间的关系不会硬编码到类中,而是等到调用的时候再进行组装,这样虽然降低了对象间的耦合,提高了对象复用的可能,但在一定程度上将组装类的任务都交给了最终调用的客户端程序,大大增加了客户端程序的复杂度。采用创建类模式的优点之一就是将组装对象的过程封装到一个单独的类中,这样,既不会增加对象间的耦合,又可以最大限度的减小客户端的负担。
其次,使用普通的方式创建对象,一般都是返回一个具体的对象,即所谓的面向实现编程,这与设计模式原则是相违背的。采用创建类模式则可以实现面向抽象编程。客户端要求的只是一个抽象的类型,具体返回什么样的对象,由创建者来决定。
再次,可以对创建对象的过程进行优化,客户端关注的只是得到对象,对对象的创建过程则不关心,因此,创建者可以对创建的过程进行优化,例如在特定条件下,如果使用单例模式或者是使用原型模式,都可以优化系统的性能。