muduo库-Buffer实现
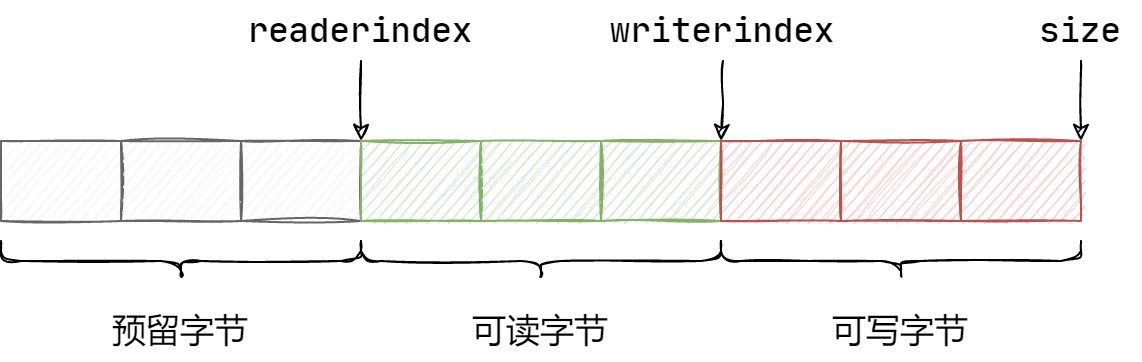
muduo库中的Buffer结构示意图如下图所示:
它使用 vector
来作为底层容器,可以进行动态的扩容操作。其次,前置的预留字节空间可用于填充数据序列化后的消息长度。该类的构造函数及其成员变量如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Buffer : public muduo::copyable {public :static const size_t kCheapPrepend = 8 ;static const size_t kInitialSize = 1024 ;explicit Buffer (size_t initialSize = kInitialSize) : buffer_(kCheapPrepend + initialSize), readerIndex_(kCheapPrepend), writerIndex_(kCheapPrepend) { assert (readableBytes () == 0 );assert (writableBytes () == initialSize);assert (prependableBytes () == kCheapPrepend);private :char > buffer_;size_t readerIndex_;size_t writerIndex_;static const char kCRLF[];
可见,Buffer 类对于预留空间默认为 8 字节,而其默认大小为 8 + 1024,即
1032 字节。
如下三个函数分别返回预留空间大小、可读空间大小和可写空间大小,而
peek() 则返回读指针。
1 2 3 4 size_t prependableBytes () const size_t readableBytes () const size_t writableBytes () const const char * peek () const
如下函数用于在可读区域中寻找回车换行符,search()
方法的第一个参数和第二个参数是查找的范围,第三个和第四个参数是要查找的子集的头部和尾部。对于
kCRLF 而言, ASCII 码为 13,的 ASCII 码为
10,所以这实际上是两个字符,这也是如下调用 search() 方法时最后一个参数是
kCRLF + 2 的原因。
1 2 3 4 5 6 7 8 9 10 11 const char Buffer::kCRLF[] = "\r\n" ;const char * findCRLF () const const char * crlf = std::search (peek (), beginWrite (), kCRLF, kCRLF+2 );return crlf == beginWrite () ? NULL : crlf;const char * findCRLF (const char * start) const assert (peek () <= start);assert (start <= beginWrite ());const char * crlf = std::search (start, beginWrite (), kCRLF, kCRLF+2 );return crlf == beginWrite () ? NULL : crlf;
同样的,可读区域中查找结尾符的方法如下:
1 2 3 4 5 6 7 8 9 10 const char * findEOL () const const void * eol = memchr (peek (), '\n' , readableBytes ());return static_cast <const char *>(eol);const char * findEOL (const char * start) const assert (peek () <= start);assert (start <= beginWrite ());const void * eol = memchr (start, '\n' , beginWrite () - start);return static_cast <const char *>(eol);
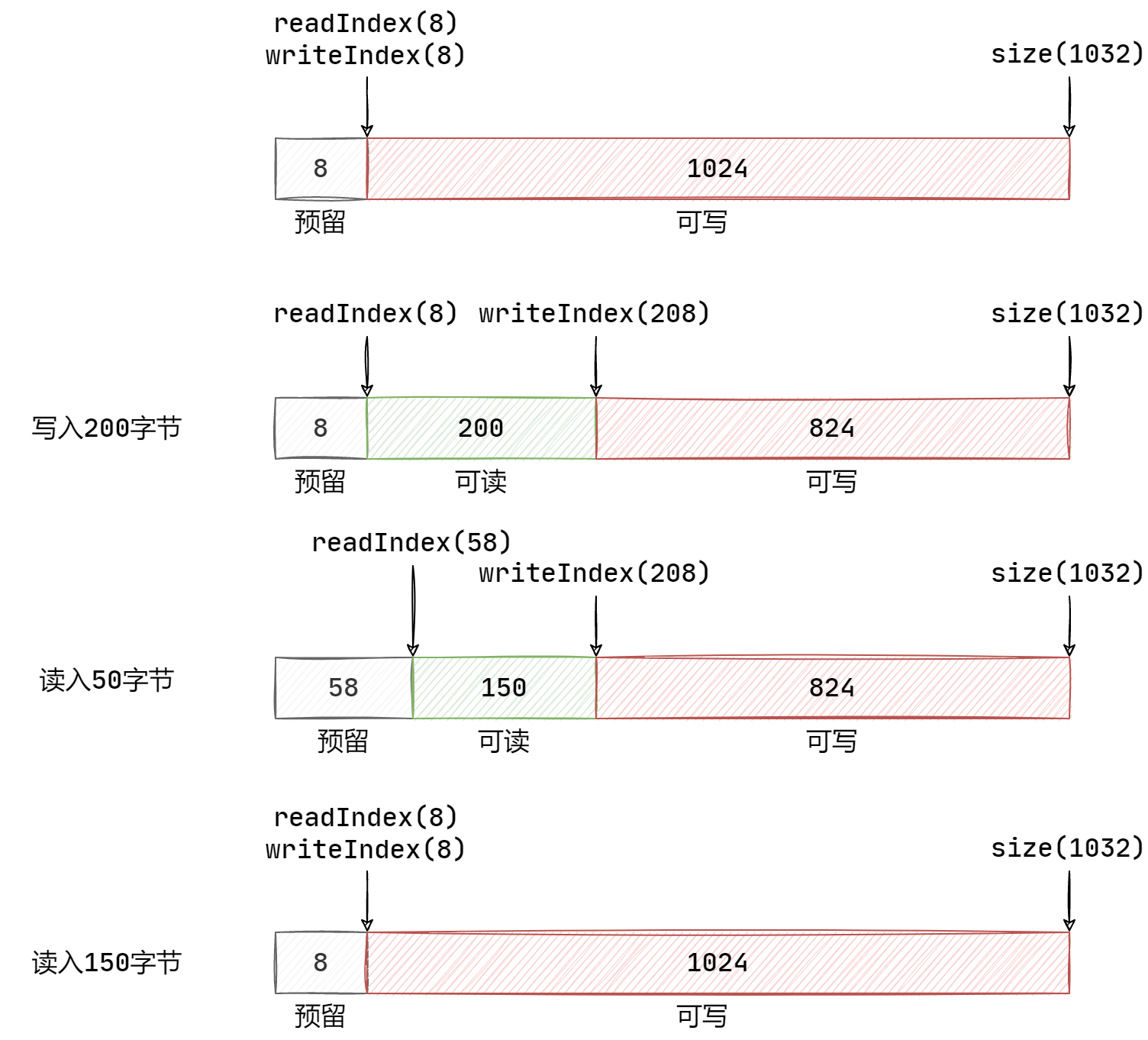
如下方法仅仅只是移动指针,而不操作数据。注意,在断言之后,len
的大小只能小于等于可读空间的大小。因此,如果 len
的长度小于可读空间的大小,说明数据还未读取完,移动读指针即可。而在 else
中,则表示 len 的长度等于可读空间的大小,说明数据刚好读取完成,那么调用
retrieveAll() 方法将读指针和写指针重置为初始化状态即可。而
retrieveUntil() 则是移动可读指针直到指定位置为止。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void retrieve (size_t len) assert (len <= readableBytes ());if (len < readableBytes ()){else {retrieveAll ();void retrieveAll () void retrieveUntil (const char * end) assert (peek () <= end);assert (end <= beginWrite ());retrieve (end - peek ());
其过程如下图中最后两步操作所示:
如下函数则是从可读区域中读取数据,读取的数据大小与 int64
的大小相同,读完之后,移动读指针并返回数据。
1 2 3 4 5 6 7 8 9 10 11 int64_t readInt64 () int64_t result = peekInt64 ();retrieveInt64 ();return result;int64_t peekInt64 () const assert (readableBytes () >= sizeof (int64_t ));int64_t be64 = 0 ;memcpy (&be64, peek (), sizeof be64);return sockets::networkToHost64 (be64);
peek()函数
peek() 函数即 cin.peek() ,它与 cin.get() 类似,但有一个重要的区别,当 get
函数被调用时,它将返回输入流中可用的下一个字符,并从流中移除该字符;但是,peek
函数返回下一个可用字符的副本,而不从流中移除它。
如下函数是向可写区域追加数据:
1 2 3 4 5 6 7 8 9 10 11 void append (const StringPiece& str) append (str.data (), str.size ());void append (const char * data, size_t len) ensureWritableBytes (len);copy (data, data+len, beginWrite ());hasWritten (len);void append (const void * data, size_t len) append (static_cast <const char *>(data), len);
如果要追加的数据长度大于可写区域的长度,那么就需要扩容:
1 2 3 4 5 6 void ensureWritableBytes (size_t len) if (writableBytes () < len) {makeSpace (len);assert (writableBytes () >= len);
其中的扩容函数如下:
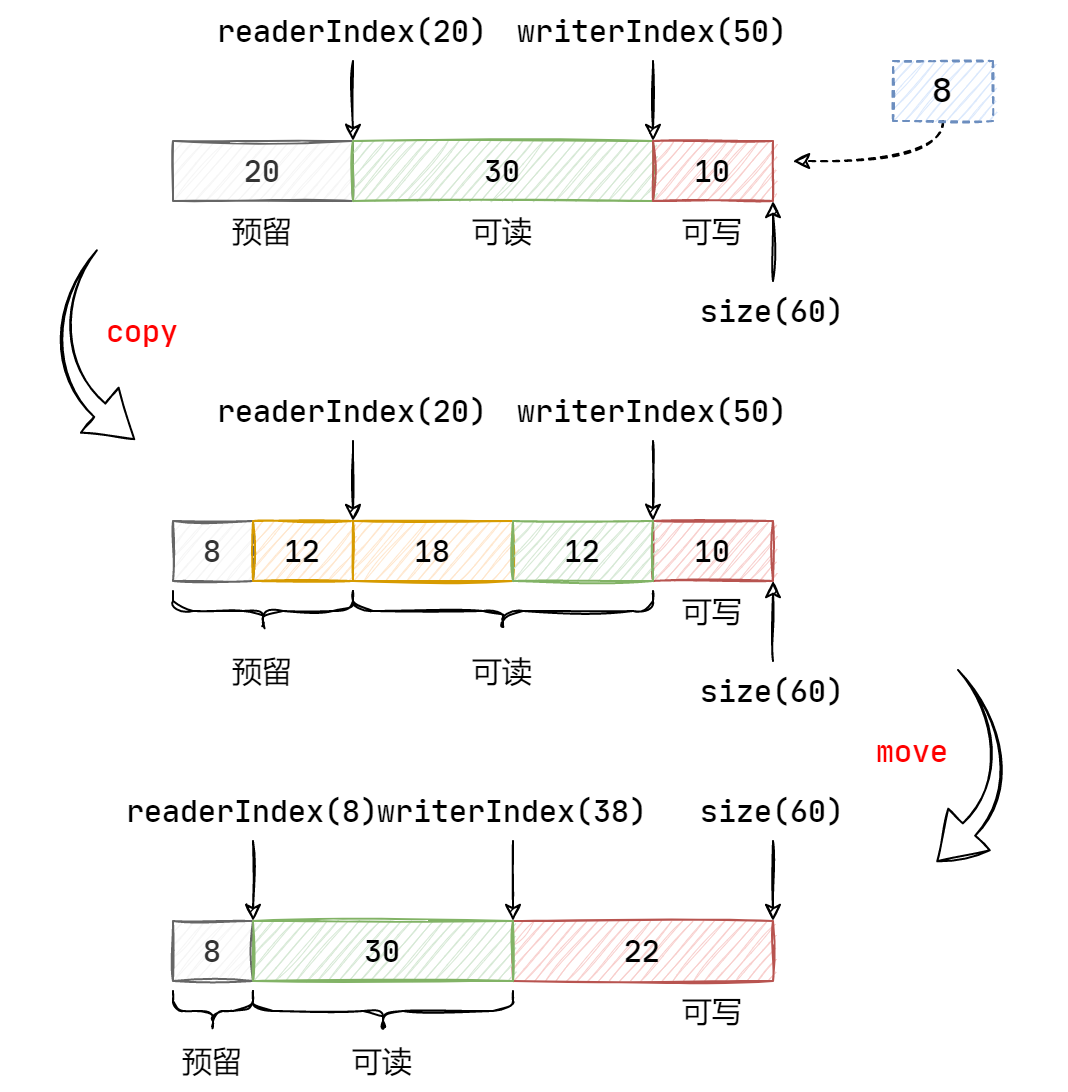
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void makeSpace (size_t len) if (writableBytes () + prependableBytes () < len + kCheapPrepend) resize (writerIndex_+len);else assert (kCheapPrepend < readerIndex_);size_t readable = readableBytes ();copy (begin ()+readerIndex_,begin ()+writerIndex_,begin ()+kCheapPrepend);assert (readable == readableBytes ());
如果可写区域的长度 和预留区域的长度 之和小于所需长度 和初始化预留区域的长度 (8)之和,就需要对缓冲区进行扩容,其过程如下图所示,可见,扩容后可写区域的长度即为所需长度
len。
否则,则表示预留空间和可写区域还很充足,为此需要将预留区域中多出来的部分移动到可写区域中去。其过程如下图所示,先将可写区域的内容向前移动,使得预留区域恢复为初始化大小,即
8。然后移动读指针和写指针。
对于如下函数,其目的是在可读区域前添加一段数据。而预留区域初始化的 8
个字节便是为该函数所准备的,以便在可读区域前添加一些序列化后的数据长度信息,而无需进行数据的迁移,以少量的空间代价换取了时间。其过程如下:先将读指针前移
len 个长度,然后将 data 中的数据拷贝进来即可。
1 2 3 4 5 6 void prepend (const void * data, size_t len) assert (len <= prependableBytes ());const char * d = static_cast <const char *>(data);copy (d, d+len, begin ()+readerIndex_);
如下方法是 Buffer 类最重要的方法,其目的是为了从 fd 上读取数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ssize_t Buffer::readFd (int fd, int * savedErrno) char extrabuf[65536 ];struct iovec vec[2 ];const size_t writable = writableBytes ();0 ].iov_base = begin ()+writerIndex_;0 ].iov_len = writable;1 ].iov_base = extrabuf;1 ].iov_len = sizeof extrabuf;const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1 ;const ssize_t n = sockets::readv (fd, vec, iovcnt);if (n < 0 ) {else if (implicit_cast <size_t >(n) <= writable) {else {size ();append (extrabuf, n - writable);return n;
由于 IP 数据包中有一个 16 位的长度字段,则说明 IP 数据包的最大长度为
65536 字节,即 64K。同时由于 IP 数据包的分片机制,即单次发送的 IP
报文长度不能超过 MTU(最大传输单元),通常为 1500
字节。为此,该函数在栈上申请了 64K
的额外空间用于尽力接受一个完整的数据包,以防可写区域不足以容纳所接收到的网络数据。
而结构体 iovec 则用于定义一个向量元素,其定义如下:
1 2 3 4 struct iovec {void *iov_base; size_t iov_len;
iov_base
所指向的缓冲区用于存放网络接受的数据,或者是网络将要发送的数据。而
iov_len 字段用于存放接受数据的最大长度,或者是实际写入的数据长度。
在 readFd 方法中,定义了两个 iovec
结构体,一部分用于将读到的数据放在可写区域,另一部分用于将读到的数据放在额外缓冲区域。然后,使用如下方法进行分散读,即将数据从文件描述符读到分散的内存块中。其中的第三个参数表示
iov 的数组长度。
1 2 #include <sys/uio.h> ssize_t readv (int fd, const struct iovec *iov, int iovcnt)
从 readFd 方法中可以看出,如果可写区域的长度小于
65536,则两个内存块都使用,否则只使用可写区域即可。
最后根据 readv
方法的返回值来确定是否需要额外缓冲区,如果返回的字节数要大于可写区域的长度,说明两个内存块都使用了,且可写区域中已经填充满了,其余的数据全部在额外缓冲区中,此时,只需移动写指针到缓冲区的数据末端,然后将额外缓冲区中的数据追加进来即可。
转载自Muduo库之Buffer