muduo库-日志类
muduo库-日志类
muduo库中的日志为诊断日志,用于将代码运行时的重要信息进行保存,方便故障诊断和追踪。日志通常分为如下两种:
- 同步日志:当需要写出一条日志消息时,只有等到这条日志消息完全写出时才能执行后续的程序,其问题在于可能会阻塞在磁盘写操作上;
- 异步日志:当需要写日志消息时,只是将日志消息进行存储,当积累到一定量时或者达到时间间隔后,由后台线程自动将存储的所有日志进行数据;
综上所述,异步日志的好处是前台线程不会阻塞在写日志上,后台线程真正写日志时,日志消息往往已经积累了很多,此时只需一次 IO 操作,从而减少了 IO 函数的调用次数,提高了效率。
而一个日志库大体可以分为前端和后端两部分:
- 前端:生成日志消息到缓冲区
- 后端:将缓冲区中的日志消息输出到本地文件
日志的前端与后端就是一个典型的 "多生产者——单消费者" 问题:
- 对于生产者而言,要尽可能坐到低延迟、低 CPU 开销、无阻塞;
- 对于消费者而言,要做到足够大的吞吐量,并占用少的资源;
对于日志消息而言,要做到以下几点:
- 每条日志消息占一行,且格式明确,便于 awk、grep 工具分析;
- 打印线程ID、日志级别、源文件、行号;
- 时间戳精确到微秒;
- 对于分布式系统而言,使用 GMT 时区;
日志框架设计思路
每一次日志操作,都进行三个步骤:
- 打开文件
- 写文件
- 关闭文件
但是,当写入日志的频率较高时,磁盘 IO 占用较高。尽管在多线程文件操作中是线程安全的,但是多个线程写入日志的顺序确难以保证。
为此,可以在应用程序启动之初打开全局文件一次,后续每次日志操作,只需写入文件即可。
由于文件操作默认是存在缓冲区的,只有当缓冲区存满后,才将缓冲区的内容输出到文件中。相较于频繁的打开文件,此方案减少了打开文件、关闭文件的次数,效率得到了提升。
note
C++ 中的 ostream 并非线程安全,而 C 中的 fwrite 则是线程安全的。
为了进一步提高效率,尽可能地减少磁盘 IO 的操作。可以使用一个线程安全队列,一边负责写日志消息,一边负责取日志消息。当所取日志条数或总长度达到一定数量时,我们才写入一次磁盘,以此来降低磁盘 IO 的操作次数。
除此之外,多个线程还可以共用一个日志前端,使用多缓冲技术。例如 muduo 库所采用的双缓冲技术,前端负责向 Buffer 中填入数据,后端则负责将 Buffer 中的数据取出来写入到文件。
如图所示,准备两块缓冲区 Buffer A 和 Buffer B,前端负责往 Buffer A 中写入日志消息,后端负责将 Buffer B 中的日志消息写入文件:
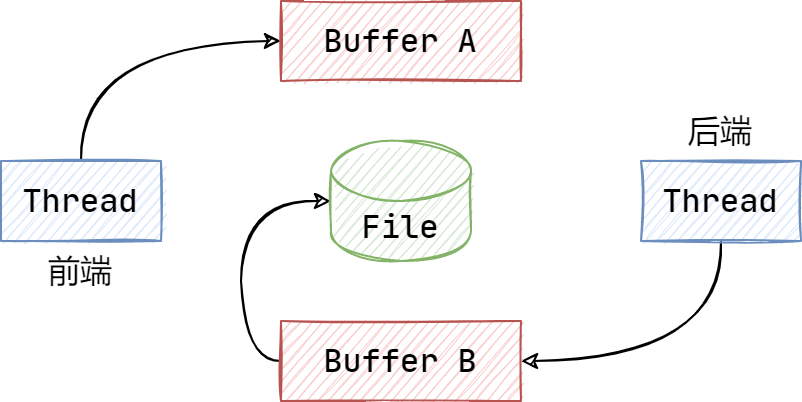
当 Buffer A 写满之后,交换 A 和 B,让后端将 Buffer A 中的日志消息写入文件,而前端则往 Buffer B 中写入新的日志消息,如此反复。
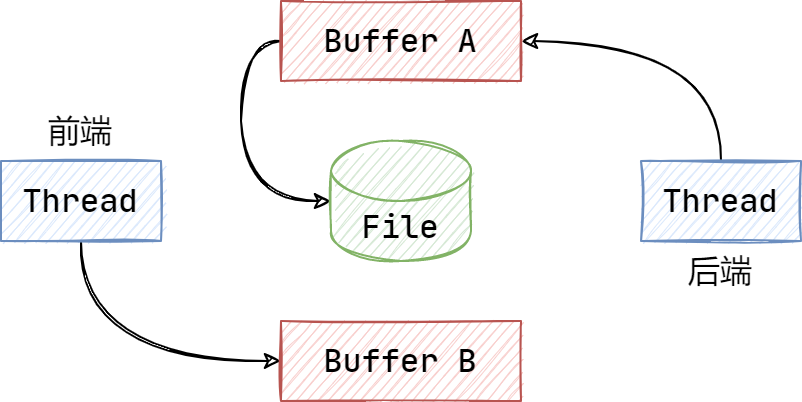
在大部分的时间中,前端线程和后端线程不会操作同一个缓冲区,这也就意味着前端线程的操作,不需要等待后端线程缓慢的写文件操作,因为不需要锁定临界区。
note
前端线程和后端线程仅仅只在交换缓冲区时会存在线程同步问题,因此只需要在交换缓冲区时使用互斥锁来保护临界区即可,这个时间极其短暂,这也就是提高吞吐量的关键所在。
同时,后端线程将缓冲区中的日志消息写入到文件系统中的频率,完全由自己的写入策略来决定,避免了每条新的日志消息都唤醒后端线程。
换言之,前端线程不是将一条条日志消息分别传送给后端线程,而是将多条消息组成一个大的 Buffer 传递给后端进行处理,相当于批量处理,减少了线程唤醒的频率和 IO 操作次数,降低开销。
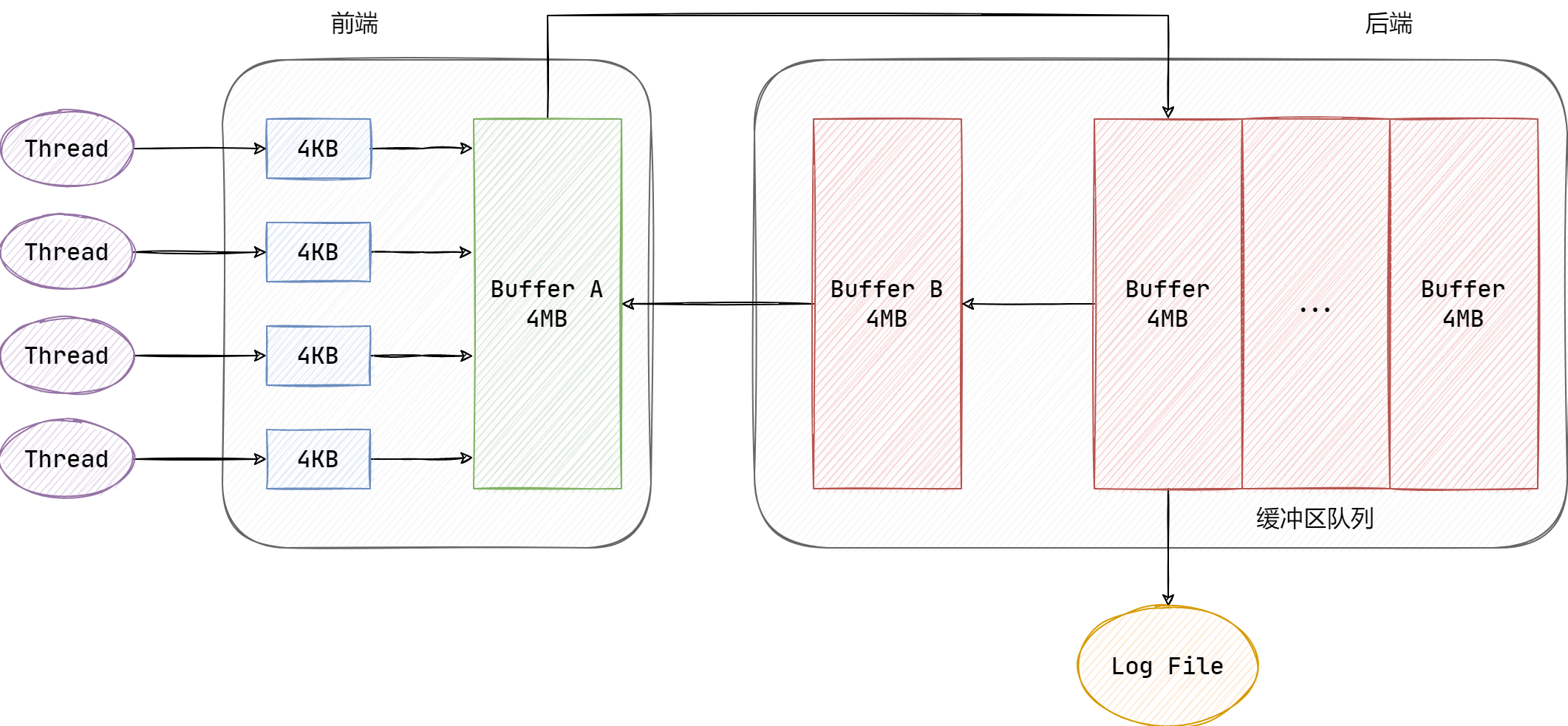
在 Muduo 的实现中,它在后端设置了一个已满缓冲区的队列,用于缓冲一个周期内临时要写的日志消息:
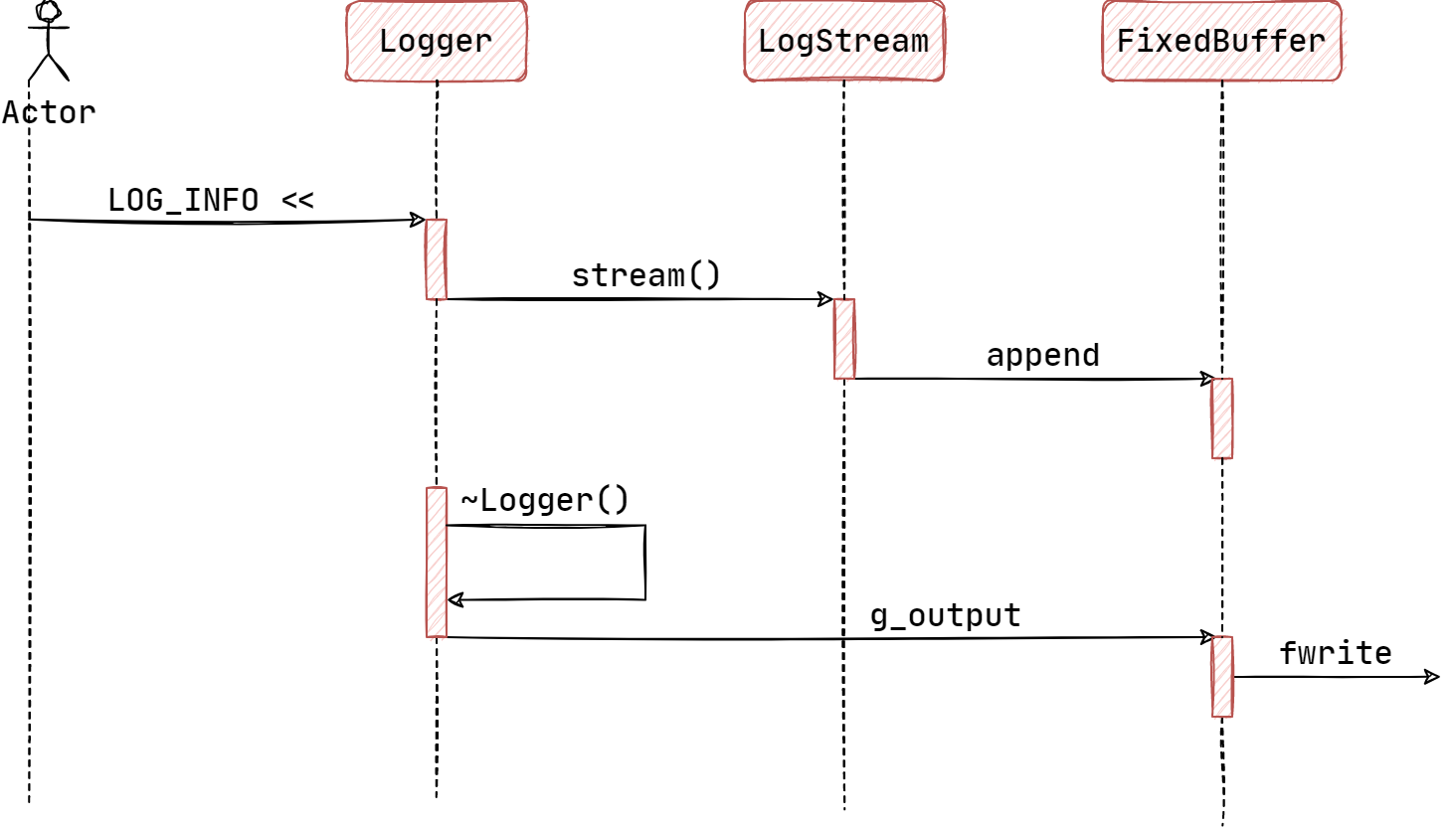
LogStream
FixedBuffer 类是作为 LogStream
类类型的缓冲区对象,其是一个模板类,传入一个非类型参数 SIZE
用来表示缓冲区的大小,其示意图如图所示:

如图所示,其在栈上维护一段大小为 SIZE
的内存区域,length 为已写入数据的长度,而
avail 为剩余可用的数据长度。
SmallBuffer 的默认大小为 4KB,为前端的
LogStream 所持有。而 LargeBuffer 的默认大小为
4MB,为后端 的 AsyncLogging 所持有。
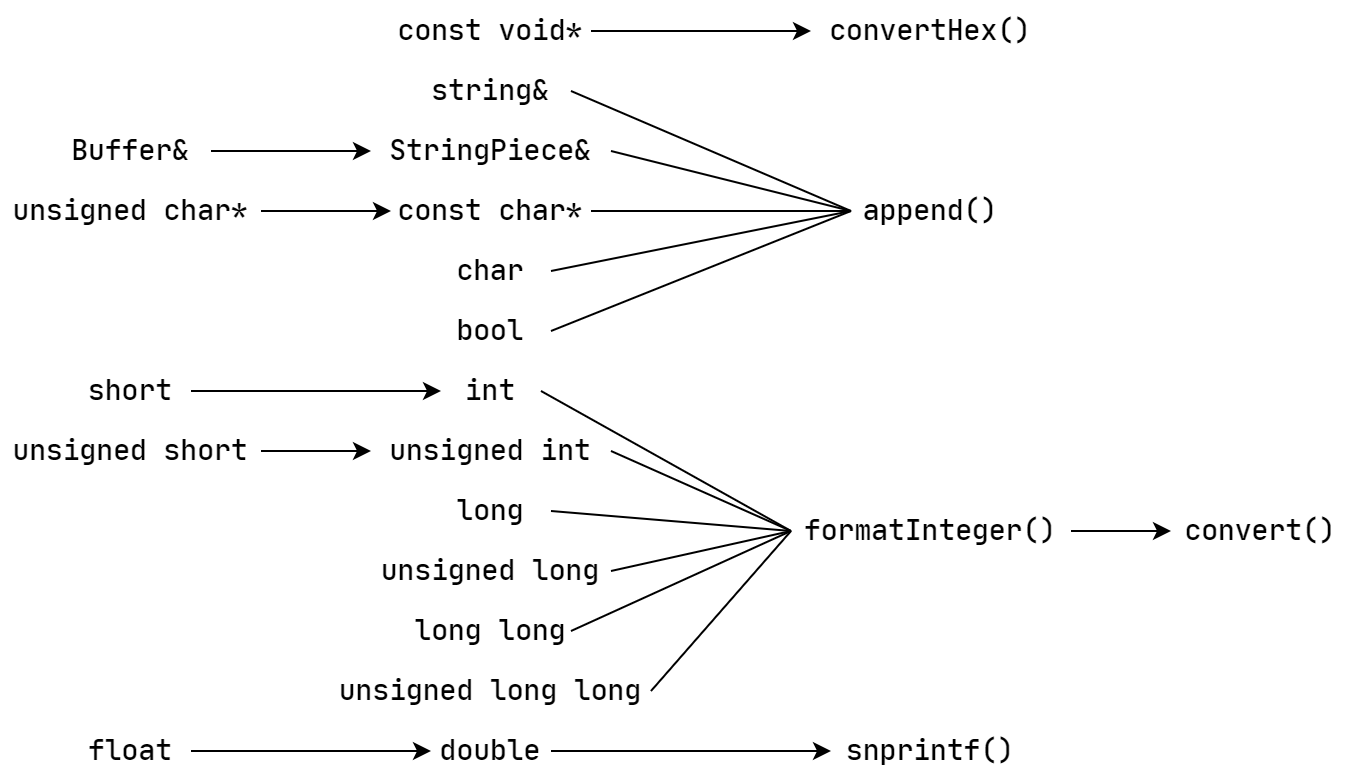
对于 LogStream 类类型来说,它将要输出的信息加载到
FixedBuffer 的缓冲区中,等待后续的处理。它通过重载
<<
运算符来输出基本的数据类型到缓冲区。各种输入类型的调用链如下所示:
note
LogStream 不是线程安全的,因此对于每个 log 消息应当构造一个临时的 LogStream,用完之后随即销毁。
在该类中,设计了大量的运算符重载函数,其效率要优于
iostream 和 stdio,使用的思想源于 Matthew
Wilson 的 “带符号整形数据的除法与余数”
算法实现。其巧妙之处在于,用一个对称的 digits
数组搞定了负数转换的边界条件(二进制补码的正负数表示范围不对称):
1 | |
此外,由于 LogStream 本身并不支持格式化,因此设计 Fmt
类类型将数值类型数据转化为一个长度不超过 32 位的字符对象
Fmt,并重载了支持 Fmt 输出到 LogStream 的
<< 操作符模板函数。
Logging
在 Logger 类中定义了枚举变量 LogLevel
来作为日志等级:
表格如下所示:
| 日志等级 | 说明 |
|---|---|
| TRACE | 跟踪:指明程序的运行轨迹,比 DEBUG 级别的粒度更细 |
| DEBUG | 调试:指明细致的事件信息,对调试应用最有用 |
| INFO | 信息:指明描述信息,从粗粒度上描述了应用的运行过程 |
| WARN | 警告:指明潜在的有害状况 |
| ERROR | 错误:指明错误事件,但应用可能还能继续运行 |
| FATAL | 致命:指明非常严重的可能导致应用终止执行的错误事件 |
如果日志设置为 \(L\),一个日志级别为 \(P\) 的输出日志只有满足 \(P≥L\)时日志才会输出。
具体的输出关系见下表,其中横向表头为日志级别,纵向表头为输出级别:
| TRACE | DEBUG | INFO | WARN | ERROR | FATAL | |
|---|---|---|---|---|---|---|
| TRACE | ✔️ | |||||
| DEBUG | ✔️ | ✔️ | ||||
| INFO | ✔️ | ✔️ | ✔️ | |||
| WARN | ✔️ | ✔️ | ✔️ | ✔️ | ||
| ERROR | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | |
| FATAL | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
0110 Logger 类使用了桥接模式,其具体实现交给内嵌类 Impl
来完成,它主要负责整合日志信息,主要包括:日期、时间、微秒、线程、日志级别、日志正文、源文件名、行号。其通过成员变量
stream_将日志输出到缓冲区中:
1 | |
除此之外,内嵌类 SourceFile
的目的是为了在编译期计算源文件的名称。
Logger 内部有两个成员变量 OutputFunc 和
FlushFunc,均为函数指针,分别指向输出函数和刷新函数,默认的输出函数使用线程安全的
fwrite() 函数,默认的刷新函数使用
fflush()。
1 | |
同时,通过全局变量 g_output 和 g_flush
来控制输出函数和刷新函数,使用 g_logTimeZone
来设置时区:
1 | |
文件内部定义了多个宏来便于调用 Logger
将日志追加到缓冲区中,如果当前日志消息等级低于
g_logLevel,就不会进行任何操作,几乎 0 操作,这是通过宏中的
if 语句实现的。
1 | |
在 Logger 的析构函数中,先由 impl_
往缓冲区后添加后缀,即文件名和行数以及换行符,然后调用
g_output 将缓冲区内容输出到指定的文件流。
1 | |
前端日志的时序图如:
日志类
LogFile
主要负责对日志文件的操作,包括日志文件的滚动和写入,其构造函数如下:
1 | |
变量 threadSafe 主要用于控制日志后端的线程安全,默认为
true。当只有一个后端线程来处理日志消息时,则无需线程安全。rollSize
表示一次最大刷新的字节数,flushInterval
表示刷新的时间间隔,单位为毫秒。
checkEveryN 表示写数据的次数限制,默认为
1024。count_ 用来计数当前写数据的次数,如果超过
checkEveryN 则清除以重新计数。
mutex_
根据是否需要开启线程安全来决定是否需要初始化互斥锁指针。
当写数据的次数超过指定的写数据限制时,需要写入新的日志文件,这是通过
rollFile() 来实现的:
1 | |
其创建并打开一个新的日志文件,然后更改 unique_ptr
所指向的文件对象。
为了避免频繁的创建新的文件,该函数确保上次滚动事件到现在如果不足 1 秒,就不会发生滚动:
1 | |
日志名的生成是通过如下函数实现的:
1 | |
日志的文件名是通过
[基础名].[当前时间].[主机名].[进程号].log 来构成的。
LogFile 通过 append()
方法将日志写入文件,它实质上调用的是 append_unlocked()
方法,同时根据是否开启线程安全来决定是否需要添加互斥锁来保护临界区。
同样地,刷新操作也是根据是否启用线程安全来决定是否添加互斥锁保护临界区,其内部调用的是
AppendFile::flush() 方法。
AsyncLogging
AsyncLogging 主要负责提供大缓冲区,即
LargeBuffer,默认大小为 4MB,以存放多条日志消息,而成员变量
BufferVector 则用于存放多个
LargeBuffer。其构造函数如下:
1 | |
前端线程通过调用 LOG_XXX << "..." 输出日志消息时,可以通过调用 AsyncLogging::append() 方法将日志消息传递给后端:
1 | |
由于 append()
可能被多个前端线程调用,因此必须考虑线程安全,采用互斥锁加锁。其基本思路如下图所示:
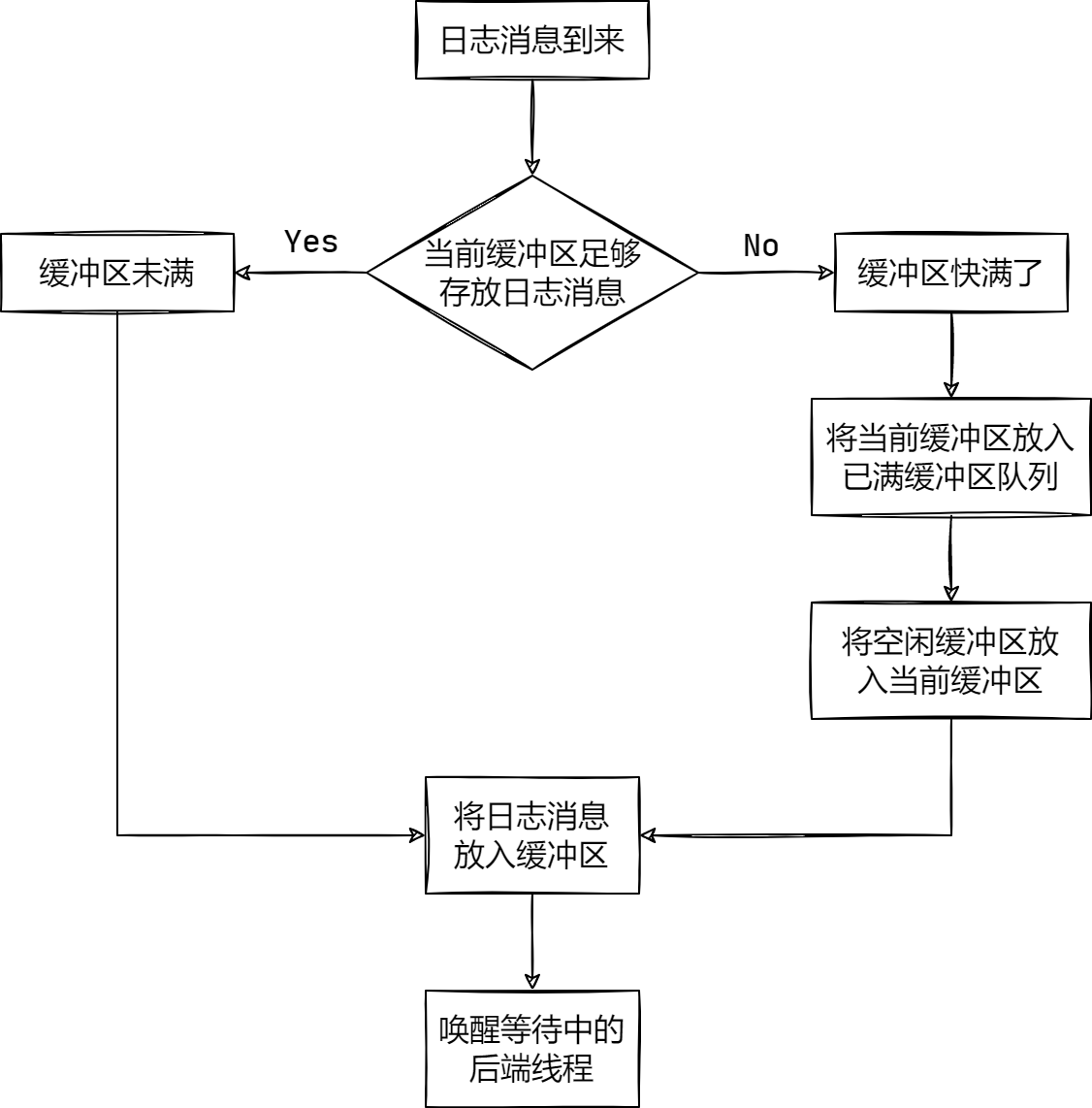
最后需要唤醒后端线程,是因为后端线程很可能阻塞等待日志消息,当缓冲区满时,能及时唤醒后端线程将已满的数据写入到磁盘上,否则短时间内如果产生大量的日志消息,会造成数据堆积,甚至丢失,而后端线程一直休眠,直到 3 秒超时后唤醒。
后端线程的启动和结束是在如下两个方法中:
1 | |
其中变量 latch_ 的作用是等待 thread_
线程启动完成。stop()
则用于关闭后端线程,通常实在析构函数中自动调用:
1 | |
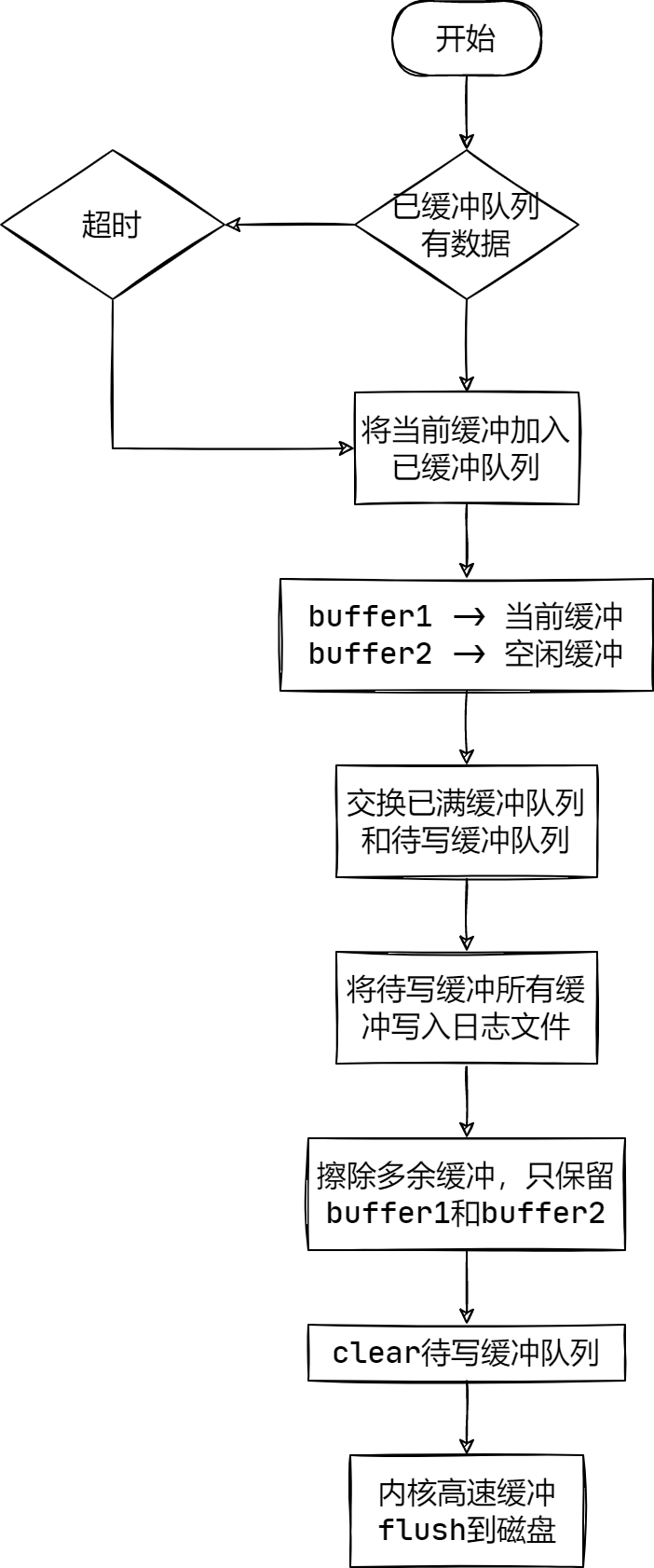
后端线程函数 threadFunc,会创建 1 个
LogFile 对象,用于控制日志文件的创建和写日志数据,创建 2
个空闲缓冲区
buffer1、buffer2,和一个待写缓冲队列
buffersToWrite,分别用于替换当前缓冲
currentBuffer_、空闲缓冲
nextBuffer_、已满缓冲队列
buffers_,避免在写文件过程中,锁住缓冲区和队列,导致前端无法写数据到后端缓冲。
threadFunc 内部的 loop 流程如下:
总结
转载自 Muduo库之异步日志