大数据期末复习
大数据期末复习
Ch1 Intruction
What is big data?
Big data is used to describe a massive volume of both structured and unstructured data that is so large that it's difficult to process using traditional database and software techniques.
大数据用来描述大量的结构化和非结构化的数据,这些数据非常大,难以用传统的数据库和软件技术来处理。
The 4V Features of big data
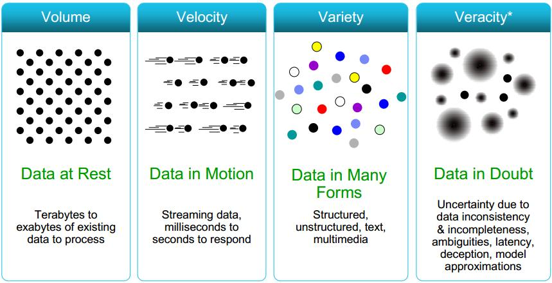
- Volume (Scale of Data)
- Velocity (Data Stream)
- Variety (Different types of data)
- Veracity (Uncertainty, missing value)
What is data mining?
Data mining consists of applying data analysis and discovery algorithms that, under acceptable computational efficiency limitations, produce a particular enumeration of patterns over the data.
数据挖掘包括应用数据分析和发现算法,在可接受的计算效率限制下,在数据上产生特定的模式列举。
The KDD Process(core part)

The main tasks of Data mining
- Association Rule Mining(关联规则挖掘)
- Cluster Analysis(聚类分析)
- Classification/Prediction(分类/预测)
- Outlier Detection(异常点检测)
The relationship between Data minning and other subjects(e.g. Database)
Data mining is known as Knowledge Discovery in Database (KDD) in the field of artificial intelligence, is also considered as a fundamental step in the process of knowledge discovery in database.
数据挖掘在人工智能领域被称为数据库知识发现(KDD),也被认为是数据库知识发现过程中的一个基本步骤。
The challenges of big data mining
- Curse of dimensionality(维度灾难)
- Storage cost
- Query speed
Ch2 Foundations of Data Mining
Supervised learning/Unsupervised learning/Semi-supervised learning
- Supervised learning: targets to learn the mapping function or relationship between the features and the labels based on the labeled data. Namely, \(𝑌=𝐹(𝑋|𝜃)\). (e.g. Classification, Prediction)
- Unsupervised learning: aims at learning the intrinsic structure from unlabeled data. (e.g. Clustering, Latent Factor Learning and Frequent Items Mining)
- Semi-supervised learning: can be regarded as the unsupervised learning with some constraints on labels, or the supervised learning with additional information on the distribution of data.
LOSS FUNCTION
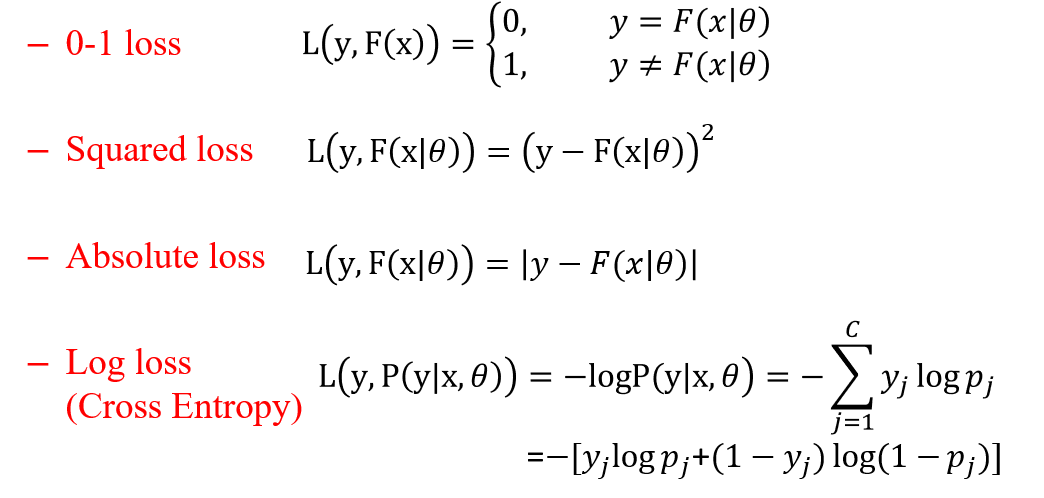
\(l_1\) norm:
\[L(\beta) =\frac{1}{N}\sum\limits_{i = 1}^{N}L(Y_i, F(X_i | \beta)) + \frac{\lambda}{2} || \beta ||_2\]
\(l_2\) norm:
\[L(\beta) =\frac{1}{N}\sum\limits_{i = 1}^{N}L(Y_i, F(X_i | \beta)) + \frac{\lambda}{2} || \beta ||_1\]
\(||A||_∗\) nuclear norm:
\[||A||_∗=∑\limits_i{σ_i}(A).\]
Overfitting/Underfitting problem
Reason?
How to avoid overfitting?
Classfied Algorithms
Decision Tree
- How to construct DT?
- Attribute selection Criteria
- Information Gain
- Information Gain Ratio
- Gini index
KNN
Lazy Learning: Lazy Learning does not extract rules or generalizations from a specific model. Instead, it searches for historical instances that are similar to the testing instance and makes a prediction based on their output results. (Lazy Learning并没有从特定的模型中提取基本规则或一般情况,而是在预测时查找与测试实例相似的历史实例,并根据它们的输出结果做出预测)
advantage:
- local data distribution(适用本地数据分布)
- Incremental/online learning(渐进式/在线学习)
- large number of classes(可以对很大的类型数量分类)
disvantage:
- parameter k(要设置参数k)
- imbalanced data(数据不平衡时分类效果差)
- slow inference(推理慢)
Naive bayse
basic idea
advantage
SVM
- basic concept
- Linear seperation problem
- Why SVM works well on small size of samples?
- 可以处理高维空间
- 可以控制正则化参数防止过拟合
- 对噪声鲁棒性强
- 适用非线性分类
- Good generalization
- Why SVM works well on small size of samples?
- NonLinear problem
- solution: map data into high dimension space
- Trick: kernel Trick \(K(X,Y) = \Phi(X) \Phi(Y)\)
- Kernel function: Gaussian kernel, polynormial kernel
损失函数是平方损失加上L1正则化
\[J(\theta) = \frac{1}{2m} \sum_{i=1}^m (h_\theta(x^{(i)}) - y^{(i)})^2 + \alpha \sum_{j=1}^n |\theta_j|\]
其中,第一项是平方损失,第二项是L1正则化项,\(\alpha\)是正则化参数。
Ensemble Learning
Rationale for Ensemble Learning: No Free Lunch thm: There is no algorithm that is always the most accurate
Two Criteria:
- Good base learner
- diversity
Three Strategies:
- Bagging(Random Forest)
- Boosting(AdaBoost)
- Stacking
Clustering
K-means procedure and darwbacks
K-means procedure:
- 从数据中选择k个对象作为初始聚类中心;
- 计算每个聚类对象到聚类中心的距离来划分;
- 再次计算每个聚类中心;
- 计算标准测度函数,之道达到最大迭代次数,则停止,否则,继续操作。
优点:
- 原理简单,实现容易;
- 复杂度与样本数量线性相关,对于处理大数据集合,该算法非常高效,且伸缩性较好。
drawbacks(缺点):
- K需要事先给定;
- Kmeans需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果;
- 结果不一定是全局最优,只能保证局部最优;
- 对噪声和离群点敏感;
- 该方法不适于发现非凸面形状的簇或大小差别很大的簇;
- 需样本存在均值(限定数据种类)。
DBSCAN
Advantage:
- 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
- 可以在聚类的同时发现异常点,对数据集中的异常点不敏感;
- 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
Disadvantage:
- 如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差。If the density of the sample set is not uniform and the distance between clusters is very different, the clustering quality is poor.
- 如果样本集较大时,聚类收敛时间较长。If the sample set is large, the clustering convergence time is long.
- 调参相对于传统的K-Means之类的聚类算法稍复杂. Parameter adjustment is more complex than K-means.
Subspace learning
Dimension Reduction
Models:
- Linear methods
- PCA(Principal Component Analysis)
- MDS(Multi-Dimensional Scaling)
- Nonlinear methods
- LLE(Locally Linear Embedding)
- LEM(Laplacian eigenmaps)
- Isomap
Feature selection(Classification)
- Filter Method(IG, \(\mathcal{X}^2\) )
- wrapper Method
- Embedded Methods
Subspace Clustering(子空间聚类)
- Sparse subspace clustering (SSC)
- Low-rank representation (LRR)
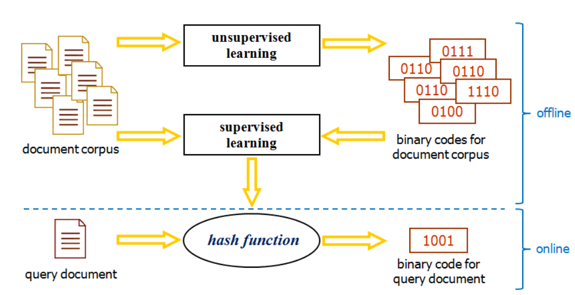
Ch3 Hashing
The role of Hashing(作用)
- After using the hash code to represent the data, the required storage space will be greatly reduced(使用哈希码表示数据后,所需要的存储空间会被大幅减小)
- Can reduce data dimensionality, thereby alleviating the dimensionality curse problem(可以降低数据维度,从而减轻维度灾难问题)
- Can realize fast neighbor retrieval at constant or sub-linear level, and provide support for the rapid realization of upper-level learning tasks(可以实现常数或者次线性级别的快速近邻检索,为上层学习任务的快速实现提供支撑)
Find similar items
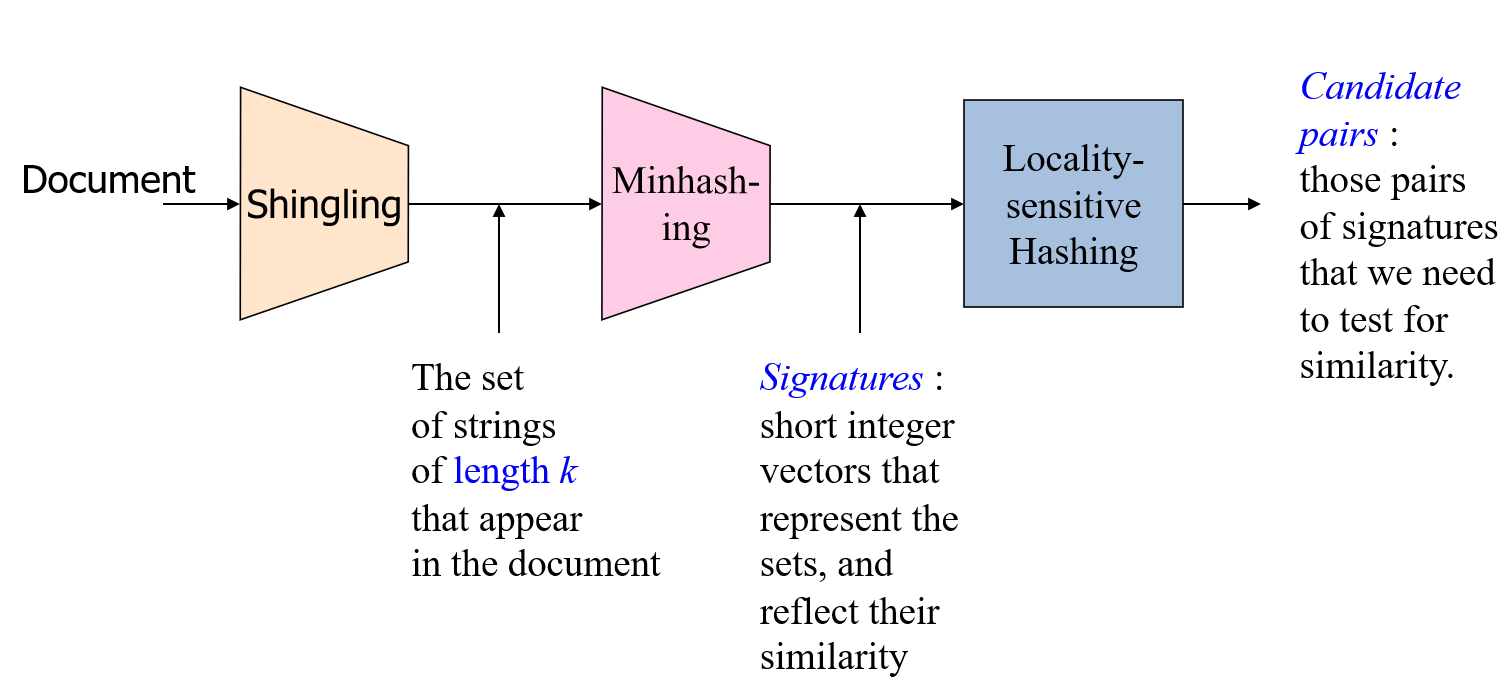
Three Essential Techniques for Similar items:
- K-Shingling:convert documents, emails, etc., to sets.
- Min-hashing:convert large sets to short signatures, while preserving similarity.
- Locality-sensitive hashing : focus on pairs of signatures likely to be similar.
Shingles
A k-shingle (or k-gram) for a document is a sequence of k characters that appears in the document. 一个文件的k-shingle(或k-gram)是一个出现在文件中的k个字符的序列。
Example: \(k=2; doc = abcab\). Set of 2-shingles = \(\{ab, bc, ca\}\).
min-hashing
definition:min-hash is an algorithm for text and data similarity comparison that efficiently extracts the signature of each data from large-scale data, thus supporting fast comparison of their similarity. min-hash是一种用于文本和数据相似度比较的算法,它可以高效地从大规模数据中提取每个数据的签名,从而支持快速地比较它们之间的相似程度。
signature matrix \(\Rightarrow\) how to compute similarity
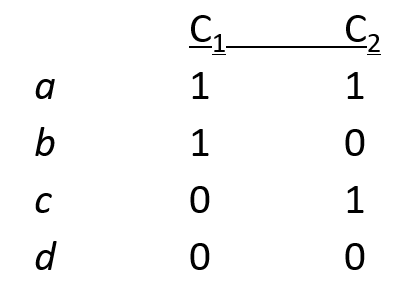
Jaccard similarity:不将\((0,0)\)计入分母,相同的行占全部行的比率
matrix similarity:相同的行占全部行的比率
Signature Matrix的计算方法:
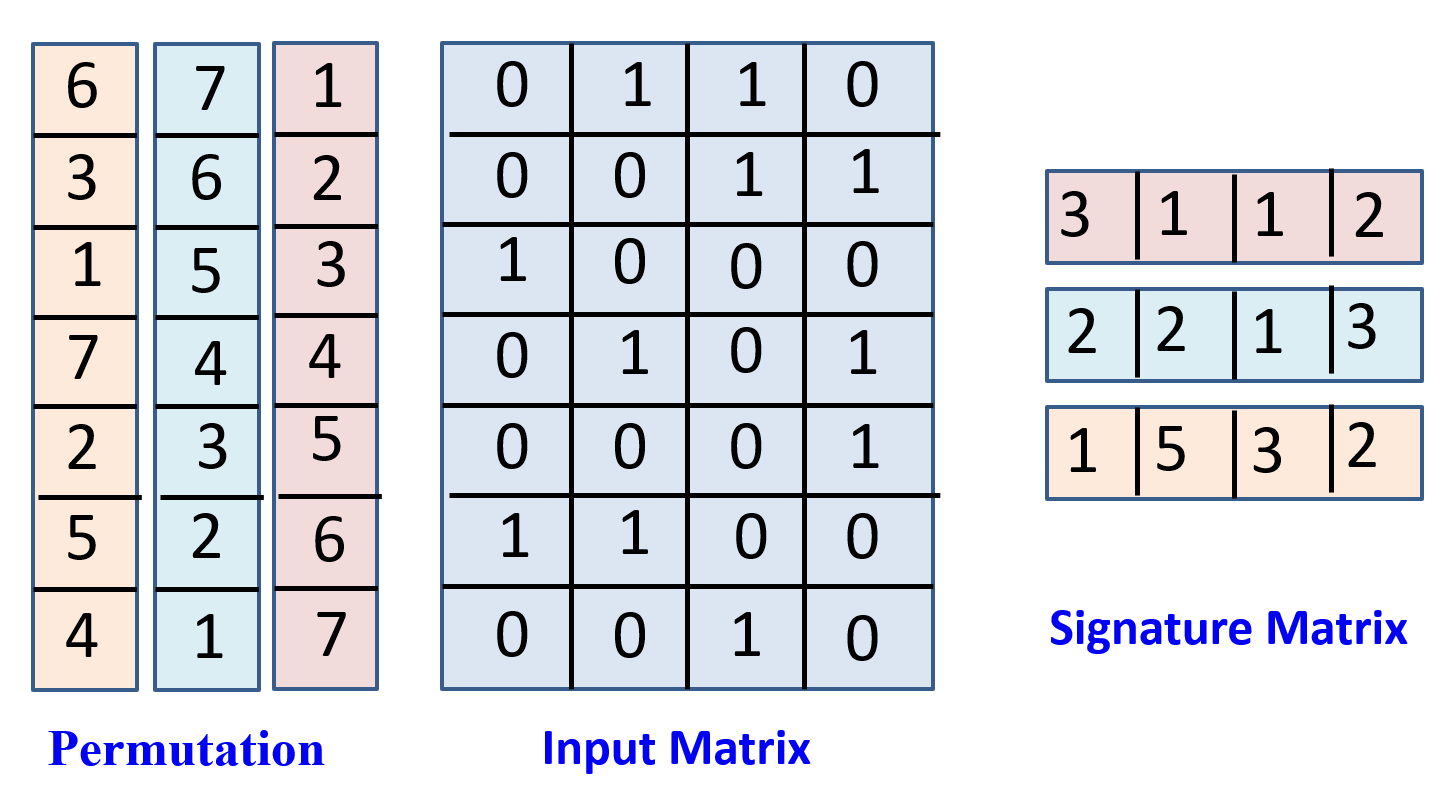
上图中间矩阵是输入矩阵,左侧的每一列都代表输入矩阵行的一种排列,那么signature matrix的每一行都对应左侧的一种排列方式,该行的每列数字对应该种排列方式对应列的第一个1的出现行数。
Locality-Sensitive Hashing(LSH)
假设我们在主内存中有代表大量对象的数据
- 可能是对象本身
- 可能是min-hashing中的签名
我们要逐一进行比较,找到那些足够相似的pair。但是检查所有的pair是很困难的。
- 一般的想法: 使用一个函数f(x,y),告诉人们x和y是否是一个候选对:一对元素的相似性必须被评估。
- 对于min-hash矩阵: 哈希列到许多桶中,并使同一桶中的元素成为候选对。
基本思想:Generate from the collection of all elements (signatures in our example) a small list of candidate pairs: pairs of elements whose similarity must be evaluated.
简单来说就是从我们Min-hashing得到的标记矩阵生成可能相似的文档对列表。
候选相似文档对 \(\Rightarrow\) 这一对的Jaccard相似度必须被准确计算出来
方法:
- 选一个相似度标准 \(t\),并且 \(t<1\),如果两个文档的相似度大于 \(t\),则认为这两个文档相似。
- 如果列\(c\)和列\(d\)被视为候选文档对,那么他们一定要满足 \(M(i,c)=M(i,d)>=t\),其中M是标记矩阵。
LSH for Minhashing Signatures
总体思想:把标记矩阵里的hash很多遍,只有hash到同一个桶(bucket)里的列才被认为是可能相似的。
Partion Into Bands
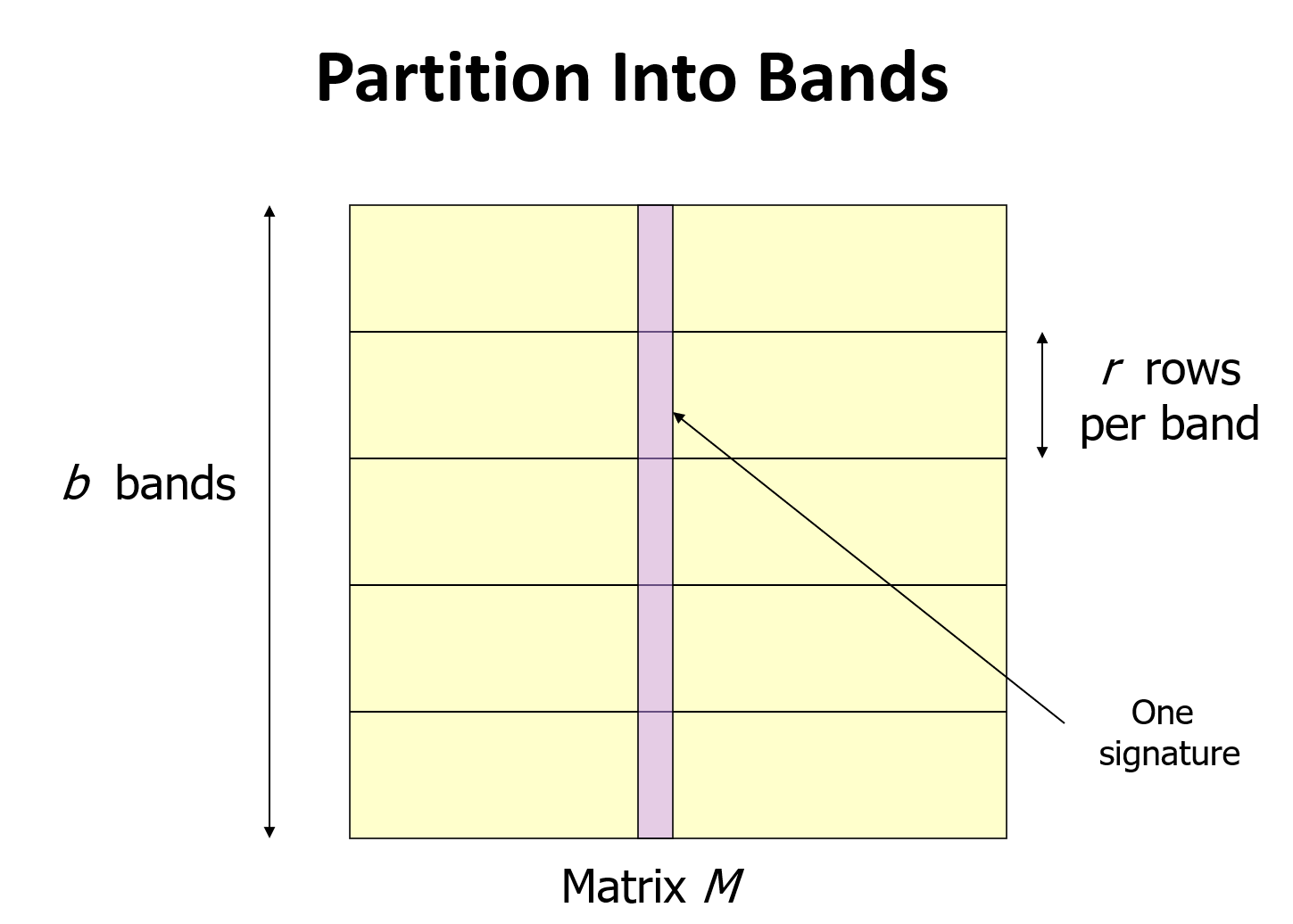
Divide matrix M into b bands of r rows. For each band, hash its portion of each column to a hash table with k buckets. 如图所示,把标记矩阵(signature matrix)的所有行分成 \(b\) 个带(bands),每个带有 \(r\) 行。对于每条带,对带里面每列进行hash,分别hash到\(k\)个桶中,并让\(k\)尽可能得大。
只有有\(>=1\)的band哈希到同一个桶中,就把这两列当作候选相似对。
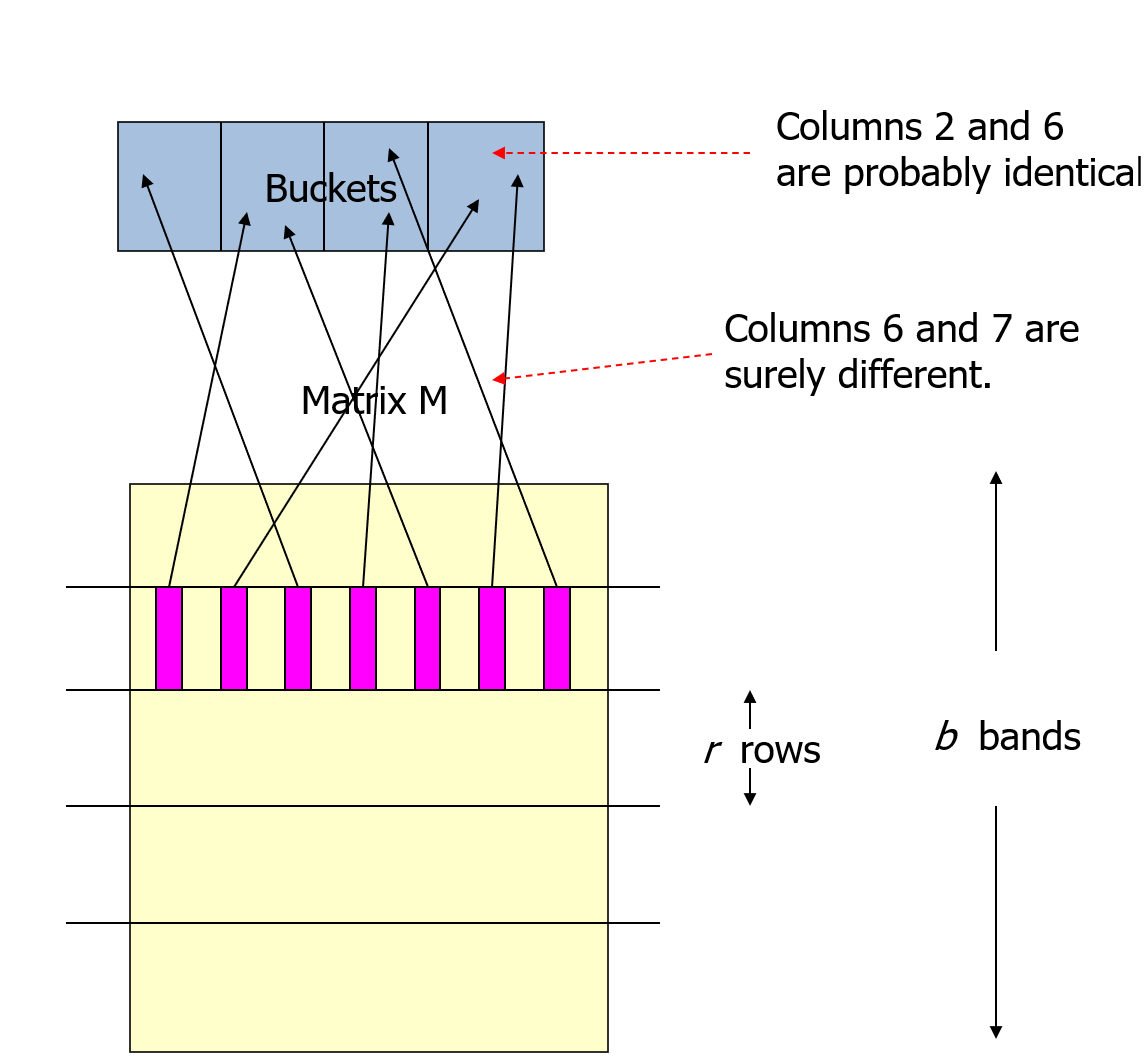
Example - Bands
假设有 100,000 列,每列有100个标记,因此存储标记需要40MB; 我们希望找到所以相似度大于80%的文档对,用上面的方法,把标记分为20个带,每个带里有5个标记。
这样的话,如果文档\(C_1\)和\(C_2\)的相似度是\(80\%\),那么他们的任意一个带的\(5\)个标记都相同的概率是: \((0.8)^5=0.328\) ,看起来好像不大,但是只要有任意一个带都相同就被认为是候选对,所以他们不被选上的概率,即20个带都不相同的概率为:\((1−0.328)^20=0.00035\) ,也就是每\(3000\)个相似度为\(80\%\)的文档对里才会有一对漏选。
我们再考虑文档\(C_1\)和\(C_2\)只有\(40\%\)的相似度,那么他们任意一个带的\(5\)个标记都相同的概率为 \((0.4)^5=0.01\),则文档\(C_1\)和\(C_2\)被选为候选对的概率,即他们中有一个带完全相同的概率为: \(C^1_{20}×0.01=0.2\) ,就是说每\(5\)个\(40\%\)相似度的文档对里就有一对会被误选为候选对。但是相似度小于\(40\%\)的文档对里误选的概率就非常小了。
Learn to Hash
- Data indenpendent:Random projection
- Data dependent:
- PCA hashing
- Spectral Hashing
PCA hashing
分为两个阶段
Projection Stage(投影阶段):
用一个转换矩阵\(W\),可以将\(x\)投影到一个新的特征平面。
\[Y=W^T X\]
Quantization Stage(量化阶段):
\[h(x) = sgn(W^T X)\]
最小化quantization loss(量化损失)
\[Q(B,Y) = ||B - Y^T R||^2_F\]
\(R\)是正交矩阵. \(B = Sgn(Y^T R)\)
基本思想是旋转数据以最小化量化损失。
实现方法:从\(R\)的随机初始化开始,采用类似K-means的迭代算法来优化\(R\)。在每次迭代中,每个数据点首先被分配到最近的聚类中心,然后更新\(R\)以使量化损失最小化。
Spectral Hashing(谱哈希)
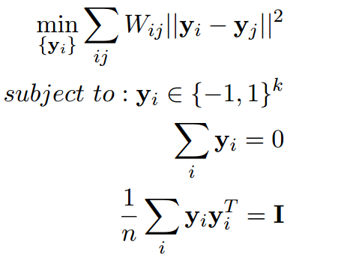
General Approach to Learning-Based Hashing(Learning-Based哈希的一般方法)
将哈希学习问题分解为两个步骤:
- hash bit learning. 哈希比特学习
- hash function learning based on the learned bits. 基于所学习的哈希比特的哈希函数学习
Ch4 Sampling
Why sampling?
- Big data issue
- Store complexity
- Calculate complexity
- Posterior estimation
- Expectation estimation
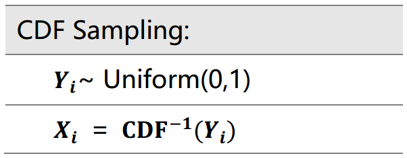
Inverse Transform Sampling(逆采样变换)
Inverse Transform Sampling based on the inverse of Cumulative Distribution Function (CDF). 逆采样变换(Inverse Transform Sampling)是伪随机数采样的一种基本方法。在已知任意概率分布的累积分布函数\(CDF\)时,可以通过\(CDF\)的逆函数来实现随机数的采样。
简单来说,假设\(X\)为一个连续随机变量,其概率密度函数为\(PDF(X)\),累计分布函数为\(CDF(X)\)。这时候若想生成符合\(X\)分布的随机变量样本,只需在\([0, 1]\)范围内生成随机变量\(x\),然后放入\(CDF\)的反函数中,即可得到符合\(X\)分布的随机变量样本。
方法:
优点:
- 简单
- 适用于任意分布
缺点:
- Hard to get the inverse function. 很难确定逆函数
Rejection Sampling(拒绝采样)
Rejection Sampling accept the samples in the region under the graph of its density function and reject others. 拒绝采样(Rejection Sampling)是一种基本的随机数采样方法。它的基本思想是:对于一个难以采样的分布,我们可以找到一个容易采样的分布,使得容易采样的分布包含难以采样的分布,然后从容易采样的分布中采样,若采样的点在难以采样的分布中,则接受该点,否则拒绝该点。
方法:
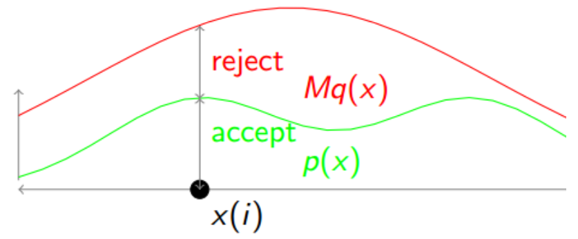
步骤:

这就使得Proposal Distribution \(q(x)\)的支撑集(support)要大于目标分布\(p(x)\)的支撑集。所以\(q(x)\)的分布选择很重要。
Importance Sampling(重要性采样)
Importance Sampling not reject but assign weight to each instance so that the correct distribution is targeted. 重要性采样(Importance Sampling)与Rejection Sampling(拒绝采样)的区别在于,重要性采样不会拒绝采样的点,而是对采样的点赋予一个权重,使得采样的点更多地来自于目标分布。
Importance Sampling和Rejection Sampling的区别
- RS的实例有一个相同的权重,只有部分的实例会被保留
- IS的实例有不同的权重,所有的实例都会被保留
- IS对对proposal distribution的选择更不敏感
Markov Chain Monte Carlo(MCMC)
MCMC methods are a class of algorithms for sampling from a probability distribution based on constructing a Markov chain that has the desired distribution as its equilibrium distribution. The state of the chain after a number of steps is then used as a sample of the desired distribution.
马尔可夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)是一种基于马尔可夫链的随机采样方法。它的基本思想是:对于一个难以采样的分布,我们可以构造一个马尔可夫链,使得该马尔可夫链的平稳分布为该难以采样的分布,然后从该马尔可夫链中采样,得到的样本服从该难以采样的分布。
蒙特卡洛法:
蒙特卡洛法(Monte Carlo Method)是一种基于随机数的数值计算方法。它的基本思想是:对于一个难以计算的问题,我们可以构造一个概率分布,使得该概率分布的期望为该问题的解,然后从该概率分布中采样,得到的样本的平均值即为该问题的解。
Detailed Balance Condition(细致平衡条件)
细致平衡条件(Detailed Balance Condition)是马尔可夫链平稳分布的一个必要条件。它的基本思想是:对于一个马尔可夫链,若该马尔可夫链的平稳分布为\(\pi(x)\),则该马尔可夫链的任意两个状态\(x\)和\(y\)满足:
\[\pi(x)P(x, y) = \pi(y)P(y, x)\]
其中\(P(x, y)\)为从状态\(x\)转移到状态\(y\)的概率,\(\pi(x)\)为状态\(x\)的概率。那么\(\pi(x)\)就是该马尔可夫链的平稳分布。
The Procedure of MCMC(MCMC的流程)

Metropolis-Hastings Algorithm(MH算法)
由于MCMC采样有收敛太慢的问题,所以在MCMC的基础之上进行改进,引出MH算法。

MH算法的具体流程如下:

一般来说M-H采样算法较MCMC算法应用更广泛,然而在大数据时代,M-H算法面临着两个问题:
- 在高维时的计算量很大,算法效率很低,同时存在拒绝转移的问题,也会加大计算量
- 由于特征维度大,很多时候我们甚至很难求出目标的各特征维度联合分布,但是可以方便求出各个特征之间的条件概率分布(因此就思考是否能只知道条件概率分布的情况下进行采样)。
Gibbs Sampling
Gibbs Sampling是MH算法的一种特殊情况。它的基本思想是:


因此可以得出在二维的情况下Gibbs采样算法的流程如下:

而在多维的情况下,比如一个n维的概率分布\(π(x_1, x_2, ...x_n)\),我们可以通过在\(n\)个坐标轴上轮换采样,来得到新的样本。对于轮换到的任意一个坐标轴\(x_i\)上的转移,马尔科夫链的状态转移概率为\(P(x_i|x_1, x_2, ..., x_{i−1}, x_{i+1}, ..., x_n)\),即固定\(n−1\)个坐标轴,在某一个坐标轴上移动。而在多维的情况下Gibbs采样算法的流程如下:

Gibbs Sampling和MH算法的联系与区别
- Gibbs Sampling和MH都是MCMC
- Acceptance Ratio:
- Gibbs Sampling: \(1\)
- MH: \(\frac{\pi(y)q(y, x)}{\pi(x)q(x, y)} < 1\)
- MH不需要知道条件概率,而Gibbs Sampling需要知道条件概率
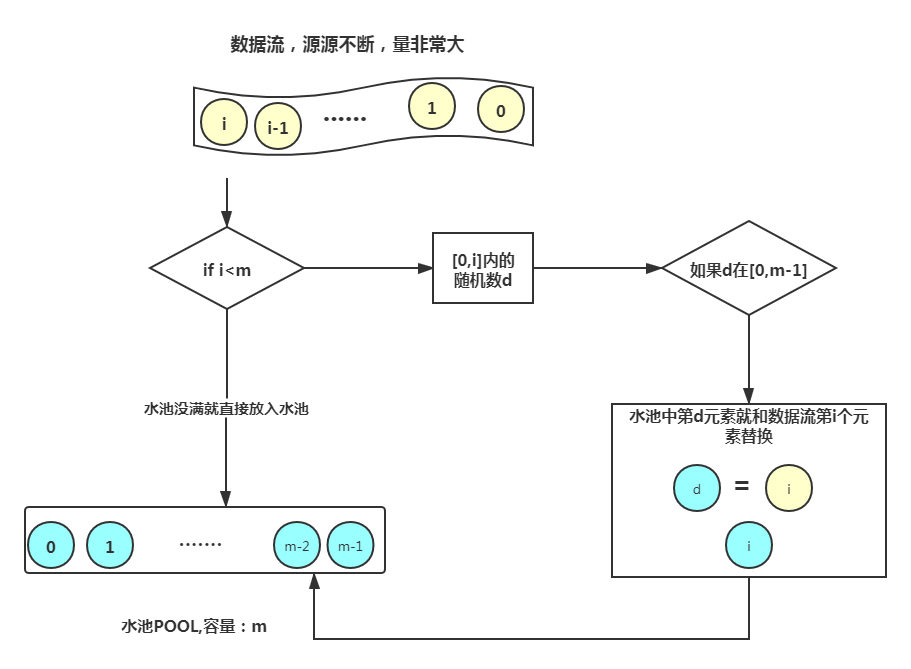
Reservoir sampling
Reservoir sampling是一种随机采样算法,它的基本思想是:对于一个数据流,我们希望从中随机采样出\(k\)个样本,但是我们不知道数据流的长度,也就是说我们不知道\(k\)的大小。具体流程如下:
Ch5 Data Stream Mining
Data Stream
What is Data Stream?
A data stream is a massive sequence of data objects which have some unique features.
Properity of Data Stream
数据流(Data Stream)是一种连续不断的数据,它的特点是:
- One by One(逐个到达)
- Potentially Unbounded(无界)
- Concept Drift(概念漂移)
Conncept Drift(概念漂移)
Concept Drift is the probability distribution changes.
概念漂移(Concept Drift)是指数据流中的数据分布随着时间的推移而发生变化的现象。概念漂移分为两种类型:
- Real concept drift (真实概念漂移)
- Virtual concept drift (虚假概念漂移)
Concept Drift Detection(概念漂移检测)
- Distribution-based detector(基于分布的检测器)
监测两个固定或可变化的数据窗口之间的数据分布变化,如果数据分布发生变化,则认为发生了概念漂移。方法很简单:只要\(W\)的两个足够大的子窗口\(W_1\)和\(W_2\)的数据分布不同,就认为发生了概念漂移,这时较旧的窗口就被放弃。
draw back(缺点):
- Hard to determine window size.
- Learn concept drift slower
- Virtual concept drift
Adaptive Windowing(ADWIN):
ADWIN 的思想是从时间窗口 \(W\) 开始,在上下文没有明显变化时动态增大窗口 \(W\),并在检测到变化时将其缩小。 该算法试图找到显示不同平均值的 \(W - w_0\) 和 \(w_1\) 的两个子窗口。 这意味着窗口的旧部分 \(- w_0\) 是基于与实际不同的数据分布,因此被删除。
- Error-rate based detector(基于错误率的检测器)
根据分类性能的变化来捕捉概念的漂移,如果分类器的错误率超过了某个阈值,则认为发生了概念漂移。
DDM算法:
DDM算法的基本思想是:在数据流中,如果某个时间点的错误率比之前的错误率大很多,则认为发生了概念漂移。确定错误率的变化是否显著的方法如下公式:
\[p_i + s_i \ge p_{min} + 3 \times s_{min}\]
误差率是指观察到错误的概率\(p_i\),其标准差为\(s_i = sqrt(p_i (1 - p_i) / i)\)
draw back(缺点):
- Sensitive to noise
- Hard to deal with gradual concept drift
- Depend on learning model itself heavily
Data Stream面临的挑战
- Infinite Length(无限长度)
- Evolving Nature(不断变化的数据)
Data Stream Clissification(数据流分类)
流程:
- 从数据流中读取下一个可用数据(要求1)
- 用读取的数据更新分类器,并且这样做不回超过对它设置的内存限制(要求2),并尽可能快地完成(要求3)
- 算法已经学习了足够的数据,以便在新数据上进行分类(要求4)
典型算法:
- VFDT(very fast decision tree, KDD'00)
- CVFDT(Concept-adapting very fast decision tree, KDD'01)
- SyncStream(同步流算法, KDD'14)
VFDT
Hoeffding树是一种基于决策树学习的数据流分类算法,在处理数据流时,可以保证挖掘效率的同时,达到对数据流一些必要操作的要求。该算法简单的对数据流中的每个样本检查一次,并逐步生成一颗决策树,而在这些样本更新完决策树之后无需进行存储。 在内存中只需维护决策树信息,因为在决策树的叶结点中存储着决策树扩展所必须的统计信息,并且在处理训练数据集时,可以用决策树中的信息进行预测。
VFDT(very fast decision tree)是基于Hoeffding tree改进的算法和系统,它和Hoeffding tree算法相似之处在于都是根据Hoeffding 不等式来决定决策节点的最佳属性从而建立决策树模型。
Hoeffding 不等式:
Hoeffding不等式适用于有界的随机变量。设有两两独立的一系列随机变量\(X_1, X_2, ..., X_n\),且\(X_i\)的取值范围是\([a_i, b_i]\),这\(n\)个随机变量的经验期望\(\bar{X}=\frac{X_1 + \dots + X_n}{n}\)满足以下不等式:
\[P(|\bar{X} - E(\bar{X})| \ge \epsilon) \ge \exp(-\frac{2n^2\epsilon^2}{\sum_{i=1}^n(b_i - a_i)^2})\]
\[P(|\bar{X} - E(\bar{X})| \ge \epsilon) \le 2 \exp(-\frac{2n^2\epsilon^2}{\sum_{i=1}^n(b_i - a_i)^2})\]
其中\(E(\bar{X})\)是\(\bar{X}\)的期望,\(\epsilon\)是一个正数。
VFDT系统解决了Hoeffding tree算法没有提到的实际问题,就是当两个属性的信息熵差不多时,这个时候就会发生两个属性之间的权衡。这是系统需要花费大量的时间和空间,利用更多的样本来决定选择哪个属性为最佳的决策节点的属性,而这显然是浪费的。
VFDT算法相较于Hoeffding Tress算法的改进:
- 提供了一个用户定义的阈值\(τ\) 用来解决“两个属性的信息熵差不多时的博弈”。当信息熵差值小于某个阈值时,即可判定其为决策节点属性。
- 允许设定节点的最小样本个数值\(n_{min}\),在用户能够承受的置信度下,让用户设定每个节点最小的样本数将有效的减少样本信息熵\(G\)的计算而消耗的时间复杂度。
- 提供重新扫描数据集和二次抽样的功能,并且在数据流中的样本数减少时,决策树的精度也会无限逼近于读取所有样本建立决策树的精度。
以下是 VFDT 算法的基本流程:
构建决策树:对于一个分类问题,首先需要构建一颗决策树。该决策树会被 VFDT 算法不断地更新和重新构建。
建立示例集:随机选择一些实例作为示例集。
计算初始统计信息:对于示例集中的每个实例,计算它们分类结果的概率分布。
增量统计每个实例:对于新增加的每个实例,将其加入当前的示例集,并更新分类结果的概率分布。
检查增量误差:计算每个分类器的误差,并选择一个误差最小的分类器来更新决策树。
执行更新:将当前分类器放到决策树上对应的位置,并更新决策树。
重复步骤 4-6,直到决策树满足一定条件。
VFDT 算法是一种增量式建树算法,它通过不断更新决策树的方法来尽可能地减小误差。这种算法的好处是,可以随时加入新的数据,更新模型,同时不需要重新训练整个模型。但是,VFDT 算法也存在一些缺点,比如计算复杂度较高,对异常数据较为敏感等。
VFDT的优缺点
优点:
- Scales better than traditional methods(比传统方法更好)
- Sublinear with sampling(子线性采样)
- Very small memory utilization(非常小的内存使用率)
- Incremental(增量学习)
- Make class predictions in parallel(并行预测分类)
- New examples are added as they come(新的样本随着到来而添加)
缺点:
- Could spend a lot of time with ties(可能会花费很多时间)
- Memory used with tree expansion(内存使用率随着树的扩展而增加)
- Number of candidate attributes(候选属性的数量大)
CVFDT(Concept-adapting very fast decision tree)
CVFDT是VFDT的改进版,它保持了VFDT的精度和速度,VFDT 算法假设所分析处理的数据流是平稳分布的,所以应对数据流中概念变化时采用的是单一的决策树模型,这就导致VFDT的决策树模型不能及时反映数据流随时间变化的趋势。
另外VFDT也没有处理连续值属性的问题。因为在CVFDT 中滑动窗口的引入,过时的样本都被删除,所以 CVFDT 树比 VFDT 树要小很多。 CVFDT根据滑动窗口中的数据流样本来持续检测旧的决策树的有效性从而保证建立模型与概念漂移同步。
CVFDT算法对VFDT算法的改进如下:
- CVFDT算法解决了VFDT算法不能处理数据流中概念漂移的问题。通过在VFDT算法基础上添加滑动窗口使得建立决策树模型的数据流能够不断实现更新,保证在概念漂移的数据流中保持模型的准确率。
- 对于每个节点包括根节点都有相应的ID。样本遍历每个节点时不仅会在节点处保存其样本的属性信息,同时窗口中的样本也会保存其遍历过的节点信息。当样本滑出窗口时,该样本所经历过的节点统计值将依次减一。
- CVFDT还为每个决策节点设置备选子树,周期性的检测每个决策节点的准确率从而决定替代子树是否替换当前的决策节点,从而也有效的提高了决策树模型的准确率。
CVFDT算法流程如下:
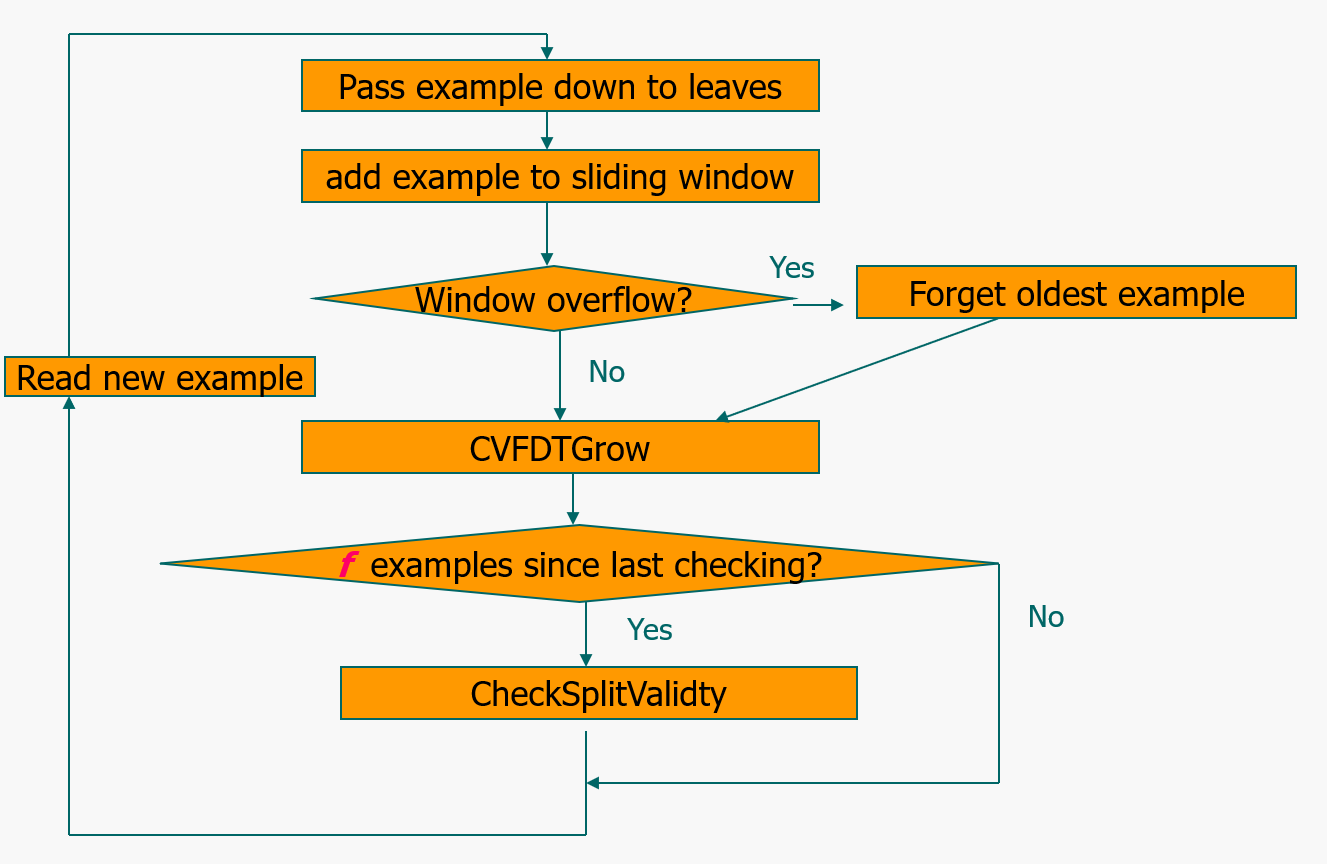
CVFDT算法采用增量的方式训练决策树,解决了VFDT算法不能处理连续属性的问题,并且在处理大规模数据时效率更高。
SyncStream
KNN style
Open-set problem
- Novel class Dection(Extreme Value Theory,EVT)
EVT 中心思想是概率分布,可给出事件发生概率的数学公式。
- Continued learning(Elastic Weight Consolidation,EWC)
EWC的基本思想:模型中的一些参数对前面的任务很重要。只改变不重要的参数
Gradient Episodic Memory (GEM)的基本思想:限制梯度的方向来改善之前的工作
- Class-incremental learning
问题:
- 怎么平衡新旧类的样本
- 怎么平衡新旧类的样本的重要性
- 怎么提取榜样样本(exemplars examples)
Knowledge Distillation(知识蒸馏):
Weight Aligning(权重对齐): 通过对齐权重来减少模型的参数数量
Data Stream Clustering(流聚类)
Framework
有两个阶段
- online Data abstraction(数据抽象):将数据归纳为具有内存效率的数据结构
- offline clustering(离线聚类):使用聚类算法来寻找数据类别
流聚类算法:

online Data abstraction
Micro-Cluster: A Micro-Cluster is a set of individual data points that are close to each other and will be treated as a single unit in further offline Macro-clustering.(Micro-Cluster是一组彼此接近的单个数据点,将在进一步的离线宏聚类中作为单个单元处理。)
Cluster Feature: 用来表示一个Micro-Cluster的属性,\(CF = (N, LS, SS)\)
其中\(LS = \sum\limits_{i=1}^N X_i, SS = \sum\limits_{i=1}^N X_i^2\)
其中\(N\)是数据点,\(LS,SS\)中的\(X_i\)是一个向量。
Cluster Feature的属性:Additivity Property
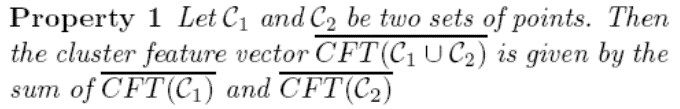
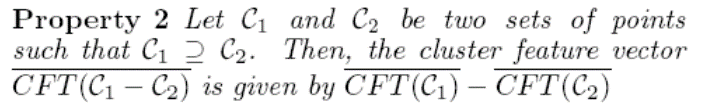
- 动态选择short-term和long-term的代表性example,代表性高的保留,代表性低的删除,没有,若代表性没有改变,就进行statistic summary(摘要统计)
- Cluster Feature的属性:Additivity Property
Ch6 Graph Mining
Key Node Identification
Centrality
Degree Centrality:节点度的大小用来衡量节点的重要性(节点的直接影响)。
Betweenness Centrality:每个顶点的间性中心度是通过该顶点的这些最短路径的数量。
Closeness Centrality:计算为节点与图中所有其他节点之间的最短路径长度之和。
K-shell Decomposition
将图中结点度为1的所有结点和对应的连边去掉后,新的网络中可能会有新的度为1的结点,把这些结点和边也去掉,重复操作,直到不再有度为1的结点为止。这种操作类似于剥去网络最外面一层壳,所以把所有去除的结点以及他们之间的连边称为网络的1-壳(1-shell)。网络中度为0的独立结点称为0-壳(0-shell)。在去除1-壳后的网络中,所有结点度都大于等于2,因此,接着把度为2的结点和对应连边去掉,直到不再有度为2的结点为止,则去除的结点和边称为2-壳(2-shell)。依此类推,直到网络中每个结点都划分到相应k-shell中,就得到网络的k-shell分解。
每个结点都唯一对应一个k-shell,这个k-shell中的结点的度一定大于等于k。但是注意,度相同的结点不一定属于同一个k-shell。并且,度大的结点既可能属于k值大的k-shell(最内层),可能能属于k值较小的shell(外层)。所以,度值大的未必就重要。
优点:
- 计算复杂度低
- 直观的揭示了网络的层次结构
缺点:
- 不能在很多网络中使用,如星形网络、树形网络等。
- 不能很好地反映网络的重要性,有时候甚至不如单纯用节点度值衡量效果好。
Eigenvector(特征向量)e.g.PageRank
PageRank是Google最早的搜索引擎核心用的就是这个算法
PageRank基本思想:如果一个页面被很多其他页面链接到的话说明这个页面比较重要,如果一个页面被一个很重要的页面链接到的话,那么这个页面也很重要。
Community Detection
Cut-based Methods
Minimum Cut
由于大多数节点互动是在组内进行的,而组与组之间的互动则很少。所以我们可以把community detection问题转换为一个最小割问题。最小割问题是指在一个无向图中,找到一条边的集合,使得这些边的权重之和最小,且删除这些边之后,图被分成两个部分。
Ratio Cut & Normalized Cut
由于最小割往往返回一个不平衡的partation,其中的一个集合是一个单点,所以我们可以用Ratio Cut和Normalized Cut来解决这个问题。思想是在最小割的基础之上修改目标函数以考虑到partation的平衡性。
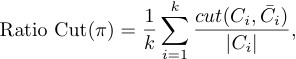
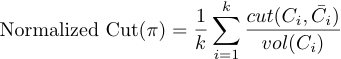
其中\(C_i\)是一个子集和,\(\bar{C_i}\)是\(C_i\)的补集,\(|C_i|\)是子集和的大小,\(vol(C_i)\)是子集和中所有节点的度之和。
在 RatioCut 切图中,不仅要考虑使不同组之间的权重最小化,也考虑了使每个组中的样本点尽量多。
在 Norm Cut 切图中,除了考虑最小化损失函数之外,还考虑了子图之间的权重大小。
由于子图样本的个数多并不一定权重就大,切图时基于权重也更合目标,因此一般来说Norm cut 切图优于 RatioCut 切图。
Modularity Maximization(模块度最大化)
模块度通过考虑度分布来衡量Community partition的强度。
给定一个有\(m\)条边的网络,学位为\(d_i\)和\(d_j\)的两个节点之间的预期边数为\(d_i d_j / 2 m\)
给定如下例子:
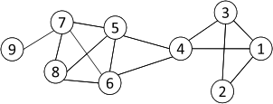
则节点\(1\)和\(2\)之间的预期边数为\(3 * 2 / (2 * 14)\)
Strength of a community: \(\sum\limits_{i \in C, j \in C} A_{ij} - \frac{d_i d_j}{2m}\)
Modularity(模块度):\(Q = \frac{1}{2m}\sum\limits_{l =1}^k \sum\limits_{i \in C, j \in C} (A_{ij} - \frac{d_i d_j}{2m})\) )
数值越大,表明community structure越好.
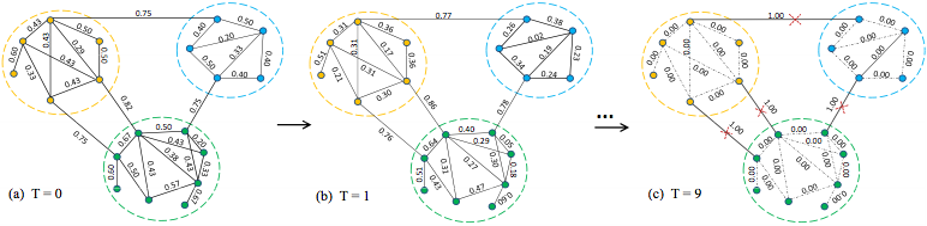
Simulating:Distance Dynamics
动态距离(Distance Dynamics)是Community Detection的一种新视角,它的基本思想是模拟边距离的动态变化。
它将整个网络视为一个动态系统,根据不同的互动模式模拟距离动态(距离动态与节点动态).所有边的距离都会收敛,从而直观地识别出社区结构。
如果两个节点相连,每个节点都会吸引另一个节点,使得另一个节点移动到自己身边.
边距离:受三种不同类型节点的影响:(a)直接链接节点;(b)共同邻居;(c)独占邻居
- 直接链接节点的影响:使u和v更接近。
- 共同邻居的影响:使u和v更接近。
- 独占邻居的影响:使u和v更接近或更远。
Distance Dynamics的步骤:
- Initialization:计算每条边的Jaccard距离
- Dynamics: 研究每条边距离的变化
- Community Detection : 删除距离为1的边
Graph embedding
Motivation
- 网络包含数十亿的节点和边,对整个网络进行复杂的推理是难以实现的。
- 机器学习算法需要向量表示
- 如何在Graph embedding的过程中保留Commmunity structure
- 如何有效地处理大规模网络
Graph embedding的目标是将每个节点映射到一个低维空间。
图是一种非欧几里得结构,图的属性:
- 节点的编号是任意的
- 图具有任意的大小
- 结构复杂
困难:
- 衡量节点之间的相似度
- 编码网络信息并生成节点表示
DeepWalk
详见【Graph Embedding】DeepWalk:算法原理,实现和应用
Node2vec
详见【Graph Embedding】node2vec:算法原理,实现和应用
Ch7 Hadoop/Spark
Hadoop
What is Hadoop
Hadoop是一个软件框架,用于在大型计算机集群中分布式处理大型数据集。
Design Principles of Hadoop
- Need to process big data
- Need to parallelize computation across thousands of nodes
- Commodity hardware
- Large number of low-end cheap machines working in parallel to solve a computing problem
- This is in contrast to Parallel DBs
- Small number of high-end expensive machines
- Automatic parallelization & distribution
- Hidden from the end-user
- Fault tolerance(容错) and automatic recovery
- Nodes/tasks will fail and will recover automatically
- Clean and simple programming abstraction.(干净而简单的编程抽象)
- Users only provide two functions “map” and “reduce”
Hadoop Architecture
- Distributed file system (HDFS)
- Execution engine (MapReduce)
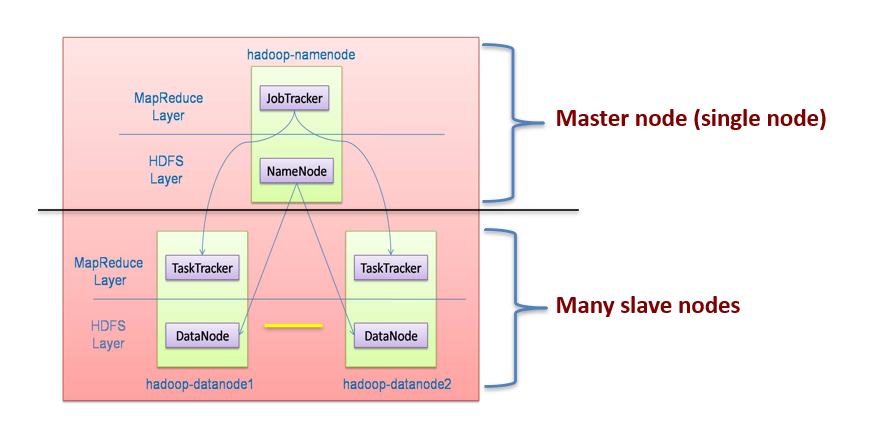
Eco-system of Hadoop
- HDFS:Storing(存储)
- MapReduce:computation
- HBASE:NoSQL database
- Hive:Data warehouse(数据仓库)
- Pig:Data flow language
- Zookeeper:Coordination service
- Core:Filesystems and I/O
- Avro:Cross-language serialization(跨语言序列化)
Hadoop Distributed File System(HDFS):分布式文件系统
Main Properties of HDFS:
- Large:一个HDFS实例可能由数以千计的服务器机器组成,每个机器都存储着文件系统的部分数据
- Replication:每个数据块被多次复制(默认为3)。
- Failure:失败是常态而不是例外
- Fault Tolerance:检测故障和快速自动恢复故障是HDFS的一个核心架构目标
NameNode + DataNode
- NameNode(meta-information)
- Managing FsImage file and EditLog file to manager meta information
- EditLog is used to update FsImage (Checkpoint).
- DataNode(actual data)
- Store data
- Block operation
Fault Tolerance: Replication + HeartBeat
- HeartBeat:DataNode
- Replication:Steady NameNode
MapReduce
MapReduce的思想就是“分而治之”
Map
Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:
- 一是数据或计算的规模相对原任务要大大缩小;
- 二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;
- 三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce
Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题具体设置。
Spark(基于内存的计算框架)
MapReduce is great at one-pass computation,but inefficient for multi-pass algorithms.
What is Spark
Apache Spark is a fast and general-purpose cluster computing system.It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming for streaming processing.
Memory based computation
RDD
Spark的主要抽象是resilient distributed dataset (RDD),它表示一个只读的对象集合,在一组机器上进行分区,如果一个分区丢失,可以重建。
An RDD can be created 2 ways:
- Parallelize a collection
- Read data from an external source
Operations on RDD
- transformations:create a new dataset from an existing one
- actions: return a value to the driver program after running a computation on the dataset
Fault Tolerance
暂无待续.
MapReduce VS Spark
MapReduce:
- Great at one-pass computation, but inefficient for multi-pass algorithms.
- No efficient primitives for data sharing(没有用于数据共享的有效基元)
Spark:
- Extends a programming language with a distributed collection data-structure(RDD).(用分布式集合数据结构(RDD)扩展了一种编程语言)
- Clean APIs in Java, Scala, Python, R.